Docker自带的监控命令
docker top #容器的动态进程
docker stats #列出每个容器的cpu、内存、io
docker logs #查看容器日志 emerg alert crit error warning notice info debug
一、sysdig 轻量级的系统监控程序
docker run -it --rm --name sysdig --privileged=true \
--volume=/var/run/docker.sock:/host/var/run/docker.sock \
--volume=/dev:/host/dev --volume=/proc:/host/proc:ro \
--volume=/boot:/host/boot:ro --volume=/lib/modules:/host/lib/modules:ro \
--volume=/usr:/host/usr:ro sysdig/sysdig
//如果下载插件失败,可以运行下边的命令,重新下载
sysdig-probe-loader
//下载成功之后,可以运行sysdig命令,查看监控项
csysdig
sysdig容器是以privileged方式运行,而且会读取操作系统 /dev,/proc等数据,这是为了获取足够的系统信息。
csysdig
view
Containers
选择对应容器
sysdig的特点:
(1)监控信息全,包括Linux操作系统和容器
(2)界面交互性强
(3)缺点是sysdig显示的是实时数据,看不到变化和趋势。而且是命令行操作方式,需要ssh到host上执行,不是太方便
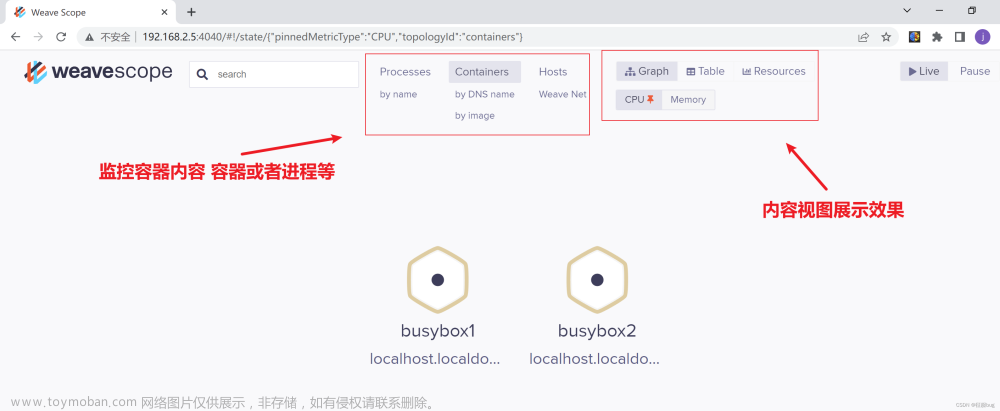
二.Weave scope
图形化的显示,能够直观的看到容器资源使用情况,便于理解,监控和控制容器
官方安装命令:
sudo curl -L git.io/scope -o /usr/local/bin/scope
sudo chmod a+x /usr/local/bin/scope
scope launch
推荐安装命令,提供基本身份验证功能:
sudo curl -L https://github.com/weaveworks/scope/releases/download/latest_release/scope -o /usr/local/bin/scope
sudo chmod a+x /usr/local/bin/scope
scope launch -app.basicAuth -app.basicAuth.password 123456 -app.basicAuth.username user -probe.basicAuth -probe.basicAuth.password 123456 -probe.basicAuth.username user
使用 Scope:
成功启动scope后,可以在浏览器中方法http://ip:4040,如果端口没有修改默认是4040。之后输入用户名和密码进入监控首页
一般我们可以点击Container查看容器的情况,这里一般会列出你自己的容器和weave自带的容器,通过名字可以区别。点击相应容器可以对它进行在线bash操作,或者重启,暂停,关闭容器
点击Hosts按钮,可以对自己的主机进行监控和操作,当然也可以在线bash
点击by image可以看到自己现在docker中所有的镜像
PS: scope可以监控单台dockerhost,也可以监控多台的dockerhost,监控 效果只需在运行scope launch 本机IP地址 其他IP地址,不过需要注意的是如果是多台的dockerhost,在运行前,保证主机名不能冲突,区别主机名。
若要监控多台dockerhost 以docker01和docker02举例,需要分别运行scope launch 本地ip 另外一台主机ip来实现
[root@docker01 ~]# scope launch 192.168.8.10 192.168.8.20
1c4f97ee6dc2543e32961bd7be155fda256797532a6787807c28c666f9612ab7
Scope probe started
Weave Scope is listening at the following URL(s):
* http://172.19.0.1:4040/
* http://172.20.0.1:4040/
* http://192.168.10.100:4040/
* http://172.22.16.1:4040/
* http://192.168.122.1:4040/
root@docker02 ~]# scope launch 192.168.8.20 192.168.8.10
3d1f206dda3f5a0aa476b646eccb86814bb48611b11aac771ba60b7e5476875c
Scope probe started
Weave Scope is listening at the following URL(s):
* http://192.168.10.101:4040/
* http://192.168.122.1:4040/
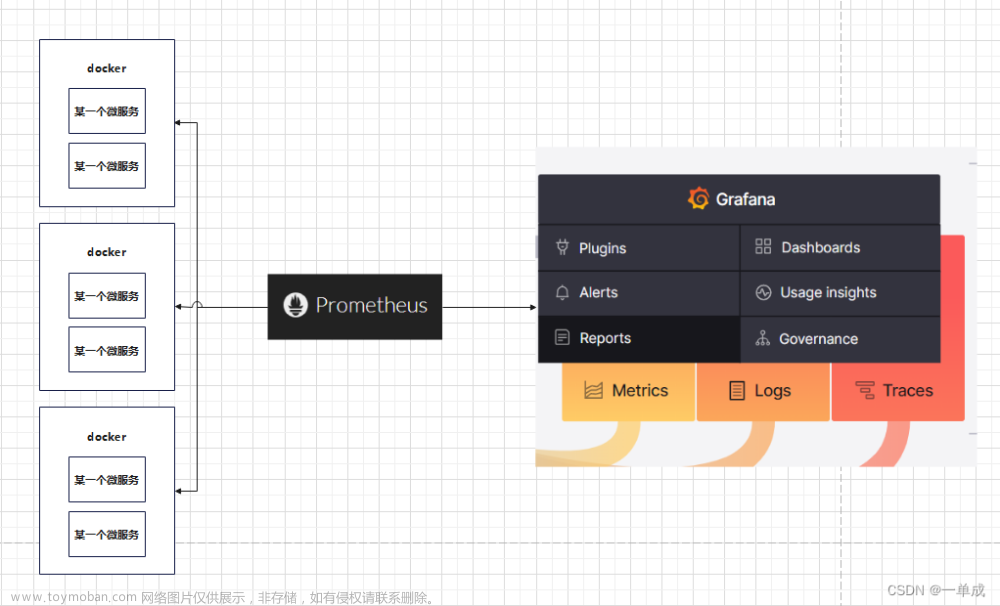
prometheus
prometheus官方网站:https://prometheus.io/
Prometheus是由SoundCloud开发的开源监控系统的开源版本。2016年,由Google发起的Linux基金会(Cloud Native Computing Foundation,CNCF)将Prometheus纳入其第二大开源项目。Prometheus在开源社区也十分活跃
易管理性:
Prometheus: Prometheus核心部分只有一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
Nagios: 需要有专业的人员进行安装,配置和管理,并且过程很复杂。
业务数据相关性:
Prometheus:监控服务的运行状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。
Nagios:大部分的监控能力都是围绕系统的一些边缘性的问题,主要针对系统服务和资源的状态以及应用程序的可用性。
另外Prometheus还存在以下优点:
高效:单一Prometheus可以处理数以百万的监控指标;每秒处理数十万的数据点。
易于伸缩:通过使用功能分区(sharing)+联邦集群(federation)可以对Prometheus进行扩展,形成一个逻辑集群;Prometheus提供多种语言的客户端SDK,这些SDK可以快速让应用程序纳入到Prometheus的监控当中。
良好的可视化:Prometheus除了自带有Prometheus UI,Prometheus还提供了一个独立的基于Ruby On Rails的Dashboard解决方案Promdash。另外最新的Grafana可视化工具也提供了完整的Proetheus支持,基于Prometheus提供的API还可以实现自己的监控可视化UI。
实验环境
| 主机名称 | IP地址 | 安装组件 |
| -------- | ------------- | -------------------------------------------------- |
| docker1 | 192.168.8.10 | NodeEXporter、cAdvisor、Prometheus Server、Grafana |
| docker2 | 192.168.8.20 | NodeEXporter、cAdvisor |
| docker3 | 192.168.8.30 | NodeEXporter、cAdvisor |
全部关闭防火墙,禁用selinux。
需要部署的组件:
Prometheus Server: 普罗米修斯的主服务器。
NodeEXporter: 负责收集Host硬件信息和操作系统信息。
cAdvisor: 负责收集Host上运行的容器信息。
Grafana: 负责展示普罗米修斯监控界面。
##### 1)3个节点,全部部署node-EXporter,和cAdvisor.
//部署node-EXporter,收集硬件和系统信息。
docker run -d -p 9100:9100 --name exporter -v /proc:/host/proc -v /sys:/host/sys -v /:/rootfs --net=host prom/node-exporter --path.procfs /host/proc --path.sysfs /host/sys --collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
PS: 注意,这里使用了--net=host,这样Prometheus Server可以直接与Node-EXporter通信。
验证:打开浏览器验证结果。
http://192.168.8.10:9100
//部署安装cAdvisor,收集节点容器信息。
docker run -v /:/rootfs:ro -v /var/run:/var/run/:rw -v /sys:/sys:ro -v /var/lib/docker:/var/lib/docker:ro -p 8080:8080 --detach=true --name=cadvisor --net=host google/cadvisor
部署完成之后,打开浏览器验证。
http://192.168.8.10:8080
##### 2)在docker01上部署Prometheus Server服务。
在部署prometheus之前,我们需要对它的配置文件进行修改,所以我们先运行一个容器,先将其配置文件拷贝出来。
docker run -d -p 9090:9090 --name prometheus --net=host prom/prometheus
docker cp prometheus:/etc/prometheus/prometheus.yml /root
vim prometheus.yml
- targets:['localhost:9090','localhost:8080','localhost:9100','192.168.8.20:8080','192.168.8.20:9100','192.168.8.30:8080','192.168.8.30:9100']
PS: 这里指定了prometheus的监控项,包括它也会监控自己收集到的数据。
修改配置文件后删除掉前面开启的prometheus容器,因为我们已经得到配置文件并按照实际修改了,后面需要重新开启新的容器
docker rm -f prometheus 容器名
//重新运行prometheus容器。
docker run -d -p 9090:9090 --name prometheus --net=host -v /root/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
浏览器访问验证。
http://192.168.8.10:9090/targets
PS: 这里能够查看到我们各个监控项。
##### 3)在docker01上,部署grafana服务,用来展示prometheus收集到的数据。
mkdir /grafana-storage
chmod 777 -R /grafana-storage/
docker run -d -p 3000:3000 --name grafana -v /grafana-storage:/var/lib/grafana -e "GF_SECURITY_ADMIN_PASSWORD=123.com" grafana/grafana
浏览器访问验证:
http://192.168.8.10:3000/login
用户名:admin
密码:123.com
设置Grafana,添加数据来源(prometheus)
点击“DATA SOURCES”
选择“Prometheus”
Name 选择Prometheus
URL 填写http://192.168.8.10:9090
点击 Save & Test
PS: 看到这个提示,说明prometheus和grafana服务的是正常连接的。
此时,虽然grafana收集到了数据,但怎么显示它,仍然是个问题,grafana支持自定义显示信息,不过要自定义起来非常麻烦,不过好在,grafana官方为我们提供了一些模板,来供我们使用。
grafana官网: https://grafana.com/
Grafana
Dashboards
Prometheus
Node Exporter for full
Download JSON
选中一款模板,然后,我们有2种方式可以套用这个模板。
**第一种方式:通过JSON文件使用模板。**
下载完成之后,来到grafana控制台
http://192.168.8.10:3000/datasources
点击左侧“+”,import ,upload JSON file
**第二种导入模板的方式**:
可以直接通过模板的ID 号。
10619 #监控docker容器
======================
grafana常用监控模板
1、监控物理机/虚拟机ID(Linux)
8919
9276
1860
2、监控物理机/虚拟机ID(windows)
10467
10171
2129
3、监控容器ID
3146
8685
10000
8588
315
4、监控数据库ID
7362
10101
5、监控网站或者协议端口ID
http监控某个网站
icmp监控某台机器
tcp监控某个端口
dns监控dns
9965
Nginx
9614
2949
======================
--------------------------------------
配置AlertManager
接下来,我们需要启动 AlertManager 来接受 Prometheus 发送过来的报警信息,并执行各
种方式的告警。同样以 Docker 方式启动 AlertManager,最简单的启动命令如下
docker run --name alertmanager -d -p 9093:9093 prom/alertmanager:latest
docker cp alertmanager:/etc/alertmanager/alertmanager.yml /root
这里 AlertManager 默认启动的端口为 9093,启动完成后,浏览器访问 http://<IP>:9093 可以看到默认提供的 UI 页面,不过现在是没有任何告警信息的,因为我们还没有配置报警规则来触发报警。
URL:http://192.168.8.10:9093
AlertManager 配置邮件告警
AlertManager 默认配置文件为 alertmanager.yml,在容器内路为/etc/alertmanager/alertmanager.yml
简单介绍一下主要配置的作用:
- global: 全局配置,包括报警解决后的超时时间、SMTP 相关配置、各种渠道通知的 API 地址等等。
- route: 用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
- receivers: 配置告警消息接受者信息,例如常用的 email、wechat、slack、webhook 等消息通知方式。
- inhibit_rules: 抑制规则配置,当存在与另一组匹配的警报(源)时,抑制规则将禁用与一组匹配的警报(目标)。
那么,我们就来配置一下使用 Email 方式通知报警信息,这里以 QQ 邮箱为例,
当然在配置QQ邮箱之前,需要我们登录QQ邮箱,打开SMTP服务,并获取授权码。
配置如下:
[root@docker1 ~]# vim alertmanager.yml
global:
resolve_timeout: 5m
smtp_from: '1793594335@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '1793594335@qq.com'
smtp_auth_password: 'yuemqwmhdizdbjeg'
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '1793594335@qq.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
PS: 以上模板中涉及的QQ邮箱换成自己的即可,授权码也一样。
修改 AlertManager 启动命令,将本地 alertmanager.yml 文件挂载到容器内指定位置
[root@docker1 ~]# docker rm -f alertmanager
[root@docker01 ~]# docker run -d --name alertmanager -p 9093:9093 -v /root/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager
### Prometheus 配置 AlertManager 告警规则
接下来,我们需要在 Prometheus 配置 AlertManager 服务地址以及告警规则,新建报警规则文件 node-up.rules 如下
mkdir -p /root/prometheus/rules
cd /root/prometheus/rules/
[root@docker1 rules]# vim node-up.rules
groups:
- name: node-up
rules:
- alert: node-up
expr: up{job="prometheus"} == 0
for: 15s
labels:
severity: 1
team: node
annotations:
summary: "{{ $labels.instance }} 已停止运行超过 15s!"
PS:该 rules 目的是监测 node 是否存活,expr 为 PromQL 表达式验证特定节点 job="node-exporter" 是否活着,
for 表示报警状态为 Pending 后等待 15s 变成 Firing 状态,一旦变成 Firing 状态则将报警发送到 AlertManager,
labels 和 annotations 对该 alert 添加更多的标识说明信息,所有添加的标签注解信息,以及 prometheus.yml 中
该 job 已添加 label 都会自动添加到邮件内容中,更多关于 rule 详细配置可以参考
https://prometheus.io/docs/prometheus/latest/configuration/recording_rules/#rule
然后,修改 prometheus.yml 配置文件,添加 rules 规则文件
# vim /root/prometheus.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.8.10:9093
rule_files:
- "/usr/local/prometheus/rules/*.rules"
PS:这里 rule_files 为容器内路径,需要将本地 node-up.rules 文件挂载到容器内指定路径,修改 Prometheus 启动命令如下,并重启服务。
[root@docker1 ~]# docker rm -f prometheus
[root@docker1 ~]# docker run -d -p 9090:9090 -v /root/prometheus.yml:/etc/prometheus/prometheus.yml -v /root/prometheus/rules:/usr/local/prometheus/rules --name prometheus --net=host prom/prometheus
此时在prometheus主页上可以看到相应规则
http://192.168.8.10:9090/targets
Status
Rules
关闭某个node触发报警发送 Email
=============================
扩展报警规则:
vim node_alerts.yml
groups:
- name: 主机状态-监控告警
rules:
- alert: 主机状态
expr: up {job="kubernetes-nodes"} == 0
for: 15s
labels:
status: 非常严重
annotations:
summary: "{{.instance}}:服务器宕机"
description: "{{.instance}}:服务器延时超过15s"
- alert: CPU使用情况
expr: 100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 60
for: 1m
labels:
status: warning
annotations:
summary: "{{$labels.instance}}: High CPU Usage Detected"
description: "{{$labels.instance}}: CPU usage is {{$value}}, above 60%"
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} : {{ $labels.mountpoint }} 分区使用率过高"
description: "{{ $labels.instance }}: {{ $labels.mountpoint }} 分区使用大于80% (当前值: {{ $value }})"
- alert: 内存使用
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{ $labels.instance}} 内存使用率过高!"
description: "{{ $labels.instance }} 内存使用大于80%(目前使用:{{ $value}}%)"
- alert: IO性能
expr: (avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) > 60
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.instance}} 流入磁盘IO使用率过高!"
description: "{{ $labels.instance }} 流入磁盘IO大于60%(目前使用:{{ $value }})"
- alert: 网络
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{ $labels.instance}} 流入网络带宽过高!"
description: "{{ $labels.instance }}流入网络带宽持续2分钟高于100M. RX带宽使用率{{ $value }}"
- alert: TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{ $labels.instance }} TCP_ESTABLISHED过高!"
description: "{{ $labels.instance }} TCP_ESTABLISHED大于1000%(目前使用:{{ $value }}%)"
vim pod_rules.yml
groups:
- name: k8s_pod.rules
rules:
- alert: pod-status
expr: kube_pod_container_status_running != 1
for: 5s
labels:
severity: warning
annotations:
description : pod-{{ $labels.pod }}故障
summary: pod重启告警
- alert: Pod_all_cpu_usage
expr: (sum by(name)(rate(container_cpu_usage_seconds_total{image!=""}[5m]))*100) > 10
for: 5m
labels:
severity: critical
service: pods
annotations:
description: 容器 {{ $labels.name }} CPU 资源利用率大于 75% , (current value is {{ $value }})
summary: Dev CPU 负载告警
- alert: Pod_all_memory_usage
expr: sort_desc(avg by(name)(irate(container_memory_usage_bytes{name!=""}[5m]))*100) > 1024*10^3*2
for: 10m
labels:
severity: critical
annotations:
description: 容器 {{ $labels.name }} Memory 资源利用率大于 2G , (current value is {{ $value }})
summary: Dev Memory 负载告警
- alert: Pod_all_network_receive_usage
expr: sum by (name)(irate(container_network_receive_bytes_total{container_name="POD"}[1m])) > 1024*1024*50
for: 10m
labels:
severity: critical
annotations:
description: 容器 {{ $labels.name }} network_receive 资源利用率大于 50M , (current value is {{ $value }})
summary: network_receive 负载告警文章来源:https://www.toymoban.com/news/detail-741447.html
微信报警:
https://blog.csdn.net/m0_37680131/article/details/120090880文章来源地址https://www.toymoban.com/news/detail-741447.html
到了这里,关于Docker的监控-Prometheus(普罗米修斯)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!