01. ElasticSearch 分析器
1. ElasticSearch match 文本搜索的过程?
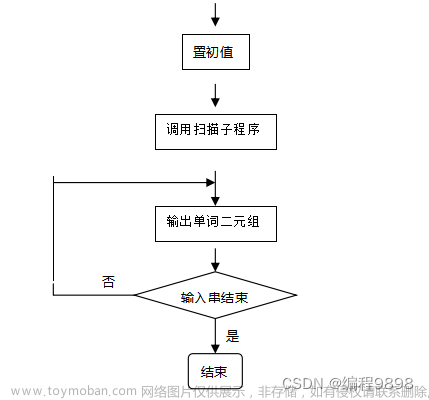
Elasticsearch 的 match 查询是一种基于文本匹配的查询方式,它的搜索过程如下:
① 将查询字符串分词:Elasticsearch 会将查询字符串分成一个个词项(term),并去除停用词(如“的”、“是”等常用词汇)和标点符号等无意义的字符。
② 构建倒排索引:Elasticsearch 会将每个词项与它所在的文档建立倒排索引(inverted index),即记录每个词项出现的文档编号和出现次数。
③ 计算文档得分:当执行 match 查询时,Elasticsearch 会根据查询字符串中的词项在倒排索引中查找对应的文档,并计算每个文档的得分。得分的计算方式包括词频(term frequency)、逆文档频率(inverse document frequency)和字段长度等因素。
④ 返回结果:Elasticsearch 会按照得分从高到低的顺序返回匹配的文档,同时可以根据需要进行分页、排序、过滤等操作。
总的来说,Elasticsearch 的 match 查询是一种基于倒排索引的文本匹配方式,它可以高效地处理大规模的文本数据,并返回与查询字符串相关的文档。
如下为文本搜索的过程:
ES 分析器先将查询词切分为“金都”和“怡家”,然后分别到倒排索引里查找两个词对应的文档列表并获得了文档1、2、3,然后根据相关性算法计算文档得分并进行排序,最后将文档集合返回给客户端。
2. ElasticSearch 分析器是什么?
ElasticSearch 是一个基于 Lucene 的分布式搜索引擎,它提供了丰富的分析器来处理文本数据。分析器是将文本数据转换为可索引的单词的过程,一般用在下面两个场景中:
① 创建或更新文档时,对相应的文本字段进行分词处理;
② 查询文本字段时,对查询语句进行分词。
ES中的分析器有很多种,但是所有分析器的结构都遵循三段式原则,即字符过滤器、分词器和词语过滤器。其中,字符过滤器可以有0个或多个,分词器必须只有一个,词语过滤器可以有0个或多个。从整体上来讲,三个部分的数据流方向为字符过滤器→分词器→分词过滤器。
① 字符过滤器:用于对原始文本进行预处理,例如去除 HTML 标签、转换大小写等。
② 分词器:将文本数据分割成单词,例如将一段中文文本分割成单个汉字或者按照空格、标点符号等进行分割。
③ 词语过滤器:对分词器产生的单词进行进一步处理,例如去除停用词、同义词转换、词干提取等。
ElasticSearch 提供了多种内置的分析器,例如 Standard Analyzer、Simple Analyzer、Whitespace Analyzer、Keyword Analyzer 等。此外,ElasticSearch 还支持自定义分析器,用户可以根据自己的需求定义自己的分析器。
3. ElasticSearch 分析器的功能?
Elasticsearch 分析器是用于将文本数据分解为单个词汇单元的组件。它们是搜索引擎中的重要组成部分,因为它们允许搜索引擎在索引和搜索文本数据时进行正确的匹配。以下是 ElasticSearch 分析器的一些常见功能:
① 分词:将文本数据分解为单个词汇单元,例如将句子分解为单个单词。
② 去除停用词:去除常见的无意义词汇,例如“a”、“an”、“the”等。
③ 小写化:将所有文本转换为小写,以便在搜索时不区分大小写。
④ 同义词扩展:将搜索词扩展为其同义词,以便在搜索时能够匹配更多的文本数据。
⑤ 词干提取:将单词转换为其基本形式,例如将“running”转换为“run”。
⑥ 字符过滤:去除文本中的特定字符,例如标点符号或 HTML 标签。
⑦ 自定义规则:允许用户定义自己的规则,以便在分析器中执行特定的操作。
这些功能可以根据需要进行组合和配置,以便在搜索引擎中实现最佳的文本匹配和搜索结果。
02. ElasticSearch 字符过滤器
4. ElasticSearch 字符过滤器是什么?
Elasticsearch 字符过滤器是一种用于处理文本的插件,它可以在文本被分词之前对其进行预处理。字符过滤器可以用于去除 HTML 标签、转换字符大小写、删除特定字符或字符序列、替换字符等操作。在处理文本之前,字符过滤器可以对文本进行清理和标准化,以便更好地进行搜索和分析。Elasticsearch 提供了许多内置的字符过滤器,同时也支持自定义字符过滤器。
5. ElasticSearch 内置的字符过滤器有哪些?
ElasticSearch 内置了许多字符过滤器,可以用于在索引和搜索期间对文本进行预处理。以下是一些常见的字符过滤器:
① html_strip:从文本中删除 HTML 标记。
② pattern_replace:使用正则表达式替换文本中的模式。
③ lowercase:将文本转换为小写。
④ uppercase:将文本转换为大写。
⑤ ascii_folding:将文本中的非 ASCII 字符转换为 ASCII 字符。
⑥ mapping:使用映射表替换文本中的字符。
⑦ trim:删除文本开头和结尾的空格。
⑧ length:删除文本中长度小于或大于指定值的单词。
6. ElasticSearch 字符过滤器如何使用?
① 自定义一个字符过滤器
② 自定义一个分析器,并使用自定义字符过滤器
③ 对索引的字段使用自定义分析器
PUT /my_index
{
"settings": {
"analysis": {
// 自定义一个过滤器:用于将文本中的“&”字符替换为“and”
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": ["& => and"]
}
},
// 自定义一个分析器:在分析器中使用字符过滤器
"analyzer": {
"my_analyzer": {
// 使用 "standard" 分词器将文本分成单词
"tokenizer": "standard",
// 使用 "my_char_filter" 字符过滤器对文本进行预处理
"char_filter": ["my_char_filter"]
}
}
}
},
"mappings": {
"properties": {
// 对 my_field 字段使用 my_analyzer 分析器
"my_field": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
④ 索引文本,索引一个包含“AT&T”文本的文档:
PUT /my_index/_doc/1
{
"my_field": "AT & T"
}
⑤ 搜索包含“AT and T”文本的文档:
GET /my_index/_search
{
"query": {
"match": {
"my_field": "AT and T"
}
}
}
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.8630463,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.8630463,
"_source" : {
"my_field" : "AT & T"
}
}
]
}
}
03. ElasticSearch 分词器
7. ElasticSearch 分词器是什么?
Elasticsearch 分词器是用于将文本分解为单词(或词条)。在 Elasticsearch 中,文本被视为一个或多个单词的集合,这些单词被称为词条。分词器将文本分解为词条,并将这些词条存储在倒排索引中,以便能够快速地搜索和检索文档。
8. ElasticSearch 内置的分词器有哪些?
ElasticSearch 内置的分词器包括:
① Standard Analyzer:标准分析器,适用于大多数语言,按照空格和标点符号进行分词。
② Simple Analyzer:简单分析器,按照非字母字符进行分词。
③ Whitespace Analyzer:空格分析器,按照空格进行分词。
④ Stop Analyzer:停用词分析器,去除常见的停用词,如“的”、“是”、“在”等。
⑤ Keyword Analyzer:关键词分析器,不进行分词,直接将输入作为一个整体进行索引。
⑥ Pattern Analyzer:模式分析器,按照正则表达式进行分词。
⑦ Language Analyzers:语言分析器,针对不同的语言提供了特定的分析器,如中文分析器、日文分析器等。
除了以上内置的分词器,ElasticSearch 还支持自定义分词器,可以根据具体需求进行定制。
9. ElasticSearch 分词器如何使用?
ElasticSearch 分词器是用于将文本分解为单词或词汇单元的工具。在 ElasticSearch 中,分词器是用于索引和搜索文本的关键组件之一。以下是使用 ElasticSearch 分词器的一些步骤:
① 创建索引:在 ElasticSearch 中,首先需要创建一个索引,以便可以将文档添加到其中。
② 定义分词器:在创建索引时,需要定义一个分词器。ElasticSearch 提供了多种不同类型的分词器,例如标准分词器、简单分词器、语言分词器等。 如下,创建了一个名为 my_index 的索引,并定义了一个名为 my_analyzer 的分词器。然后,我们将 my_field 字段定义为 text 类型,并将其分析器设置为 my_analyzer。
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"type": "standard"
}
}
}
},
"mappings": {
"properties": {
"my_field":{
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
③ 添加文档:在索引中添加文档时,ElasticSearch 将使用指定的分词器将文本分解为单词或词汇单元,并将其存储在索引中。
POST /my_index/_doc/1
{
"my_field": "这是一个示例文本"
}
④ 搜索文档:当搜索文档时,ElasticSearch 将使用相同的分词器将搜索查询分解为单词或词汇单元,并在索引中查找匹配的文档。
GET /my_index/_search
{
"query": {
"match": {
"my_field": "示例"
}
}
}
{
"took" : 376,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.5753642,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.5753642,
"_source" : {
"my_field" : "这是一个示例文本"
}
}
]
}
}
04. ElasticSearch 分词过滤器
10. ElasticSearch 分词过滤器是什么?
分词过滤器接收分词器的处理结果,并可以将切分好的词语进行加工和修改,进而对分词结果进行规范化、统一化和优化处理。例如,它可以将文本中的字母全部转换为小写形式,还可以删除停用词(如的、这、那等),还可以为某个分词增加同义词。ElasticSearch 提供了许多内置的分词过滤器,同时也支持自定义分词过滤器。
11. ElasticSearch 内置的分词过滤器有哪些?
Elasticsearch 内置的分词过滤器有很多,以下是一些常用的分词过滤器:
① Lowercase Token Filter:将所有的单词转换为小写形式。
② Stop Token Filter:去除常见的停用词,如“a”、“an”、“the”等。
③ Stemmer Token Filter:将单词还原为其词干形式,如“running”还原为“run”。
④ Synonym Token Filter:将指定的同义词替换为原始词汇,如“car”和“automobile”。
⑤ Word Delimiter Token Filter:将单词拆分为子单词,如“WiFi”拆分为“Wi”和“Fi”。
⑥ Edge N-gram Token Filter:生成指定长度的前缀或后缀 n-gram,如“quick”生成“q”、“qu”、“qui”、“quic”、“quick”。
⑦ Length Token Filter:过滤掉长度不在指定范围内的单词。
以上仅是一些常用的分词过滤器,Elasticsearch 还提供了很多其他的分词过滤器,可以根据具体需求进行选择和配置。
12. ElasticSearch 分词过滤器如何使用?
ElasticSearch 分词过滤器是用于对文本进行分词和过滤的工具。它可以将文本分解成单词,并根据指定的规则进行过滤和转换。以下是 ElasticSearch 分词过滤器的使用方法:
① 在创建索引时指定分词器和过滤器:创建一个名为 my_index 的索引,并指定了一个名为 my_analyzer 的标准分词器,并使用了一个名为 _english_ 的停用词过滤器。我们还将 my_field 字段的分析器设置为 my_analyzer。
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "standard",
"stopwords": "_english_"
}
}
}
},
"mappings": {
"properties": {
"my_field": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
② 索引文档:
PUT /my_index/_doc/1
{
"my_field":"这是一个文本示例"
}
③ 使用分词器和过滤器进行搜索:
GET /my_index/_search
{
"query": {
"match": {
"my_field":{
"query": "文本示例",
"analyzer": "my_analyzer"
}
}
}
}
{
"took" : 545,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.72928625,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.72928625,
"_source" : {
"my_field" : "这是一个文本示例"
}
}
]
}
}
05. ElasticSearch 分析器的使用
13. ElasticSearch 分析器 API 的使用
① DSL中可以直接使用参数analyzer来指定分析器的名称进行测试,分析API的请求形式如下:
POST /_analyze
{
"analyzer": "standard", //指定分析器名称为standard
"text": "The letter tokenizer is not configurable." //待分析文本
}
standard分析器对文本进行分析时,按照空格把上面的句子进行了分词。分析API返回信息的参数说明如下:
- token:文本被切分为词语后的某个词语;
- start_offset:该词在文本中的起始偏移位置;
- end_offset:该词在文本中的结束偏移位置;
- type:词性,各个分词器的值不一样;
- position:分词位置,指明该词语在原文本中是第几个出现的。
- start_offset和end_offset组合起来就是该词在原文本中占据的起始位置和结束位置。
{
"tokens" : [ //分析器将文本切分后的分析结果
{
"token" : "the", //将文本切分后的第一个词语
"start_offset" : 0, //该词在文本中的起始偏移位置
"end_offset" : 3, //该词在文本中的结束偏移位置
"type" : "<ALPHANUM>", //词性
"position" : 0 //该词语在原文本中是第0个出现的词语
},
{
"token" : "letter",
"start_offset" : 4,
"end_offset" : 10,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "tokenizer",
"start_offset" : 11,
"end_offset" : 20,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "is",
"start_offset" : 21,
"end_offset" : 23,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "not",
"start_offset" : 24,
"end_offset" : 27,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "configurable",
"start_offset" : 28,
"end_offset" : 40,
"type" : "<ALPHANUM>",
"position" : 5
}
]
}
② 除了指定分析器进行请求分析外,用户还可以指定某个索引的字段,使用这个字段对应的分析器对目标文本进行分析。下面使用酒店索引的title字段对应的分析器分析文本。
POST /hotel/_analyze
{ //使用酒店索引的title字段对应的分析器分析文本
"field": "title",
"text": "金都嘉怡假日酒店"
}
③ 在下面的示例中自定义了一个分析器,该分析器的分词器使用standard,分词过滤器使用Lower Case,其将分词后的结果转换为小写形式。
GET _analyze
{
"tokenizer": "standard", //使用standard分词器
"filter":["lowercase"], //使用Lower Case分词过滤器
"text": "JinDu JiaYi Holiday Hotel" //待分析文本
}
{
"tokens" : [
{
"token" : "jindu",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "jiayi",
"start_offset" : 6,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "holiday",
"start_offset" : 12,
"end_offset" : 19,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "hotel",
"start_offset" : 20,
"end_offset" : 25,
"type" : "<ALPHANUM>",
"position" : 3
}
]
}
14. ElasticSearch 内置分析器
ES已经内置了一些分析器供用户使用,在默认情况下,一个索引的字段类型为text时,该字段在索引建立时和查询时的分析器是standard。standard分析器是由standard分词器、Lower Case分词过滤器和Stop Token分词过滤器构成的。注意,standard分析器没有字符过滤器。 ElasticSearch 内置了许多分析器,可以用于处理文本数据。以下是一些常见的 ElasticSearch 内置分析器:
① Standard Analyzer:标准分析器是默认的分析器,它将文本分成单个单词,并删除停用词和标点符号。
② Simple Analyzer:简单分析器将文本分成单个单词,但不删除停用词和标点符号。
③ Whitespace Analyzer:空格分析器将文本分成单个单词,但不删除任何字符。
④ Keyword Analyzer:关键字分析器将整个文本作为单个单词处理,不进行任何分词或标记化。
⑤ Stop Analyzer:停用词分析器删除常见的停用词,例如“a”和“the”。
⑥ Pattern Analyzer:模式分析器使用正则表达式将文本分成单个单词。
⑦ Language Analyzers:ElasticSearch 还提供了多种语言分析器,例如英语、法语、德语、西班牙语等,这些分析器可以处理特定语言的文本数据。
以上是一些常见的 ElasticSearch 内置分析器,可以根据需要选择适合的分析器来处理文本数据。
15. ElasticSearch 索引时使用分析器
文本字段在索引时需要使用分析器进行分析,ES默认使用的是standard分析器。如果需要指定分析器,一种方式是在索引的settings参数中设置当前索引的所有文本字段的分析器,另一种方式是在索引的mappings参数中设置当前字段的分析器。
① 在settings参数中指定在酒店索引的所有文本字段中使用simple分析器进行索引构建。
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type": "simple"
}
}
}
},
"mappings": {
"properties": {
"title":{
"type": "text"
},
"content":{
"type": "text"
}
}
}
}
② 在mappings参数中指定在酒店索引的 title 字段中使用 whitespace 分析器进行索引构建:
PUT /hotel
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "whitespace"
},
"content":{
"type": "text"
}
}
}
}
16. ElasticSearch 搜索时使用分析器
为了搜索时更加协调,在默认情况下,ES对文本进行搜索时使用的分析器和索引时使用的分析器保持一致。当然,用户也可以在mappings参数中指定字段在搜索时使用的分析器。
PUT /hotel
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "whitespace", //索引时使用whitespace分析器
"search_analyzer": "whitespace" //搜索时使用whitespace分析器
},
}
}
}
注意,这里指定的搜索分析器和索引时的分析器是一致的,但是在大多数情况下是没有必要指定的,因为在默认情况下二者就是一致的。如果指定的搜索分析器和索引时的分析器不一致,则ES在搜索时可能出现有不符合预期的匹配情况,因此该设置在使用时需要慎重选择。
17. ElasticSearch 自定义分词器
当系统内置的分析器不满足需求时,用户可以使用自定义分析器。在有些场景中,某个文本字段不是自然语言而是在某种规则下的编码。
① 创建索引时使用自定义分词器
在settings部分中,定义了一个名为“comma_analyzer”的分析器,它使用名为“comma_tokenizer”的分词器。该分词器使用逗号作为分隔符,将文本分成多个词条。这个分析器可以用于分析“title”字段中的文本。
在mappings部分中,title属性是一个文本类型,但使用了之前定义的“comma_analyzer”分析器进行分析。这意味着文本将按照逗号进行分词
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"comma_analyzer": {
"tokenizer": "comma_tokenizer"
}
},
"tokenizer": {
"comma_tokenizer": {
"type": "pattern",
"pattern": ","
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "comma_analyzer"
}
}
}
}
② 下面向酒店索引中插入几条数据:
POST /_bulk
{"index":{"_index":"hotel","_id":"001"}}
{"title":"APP,H5"}
{"index":{"_index":"hotel","_id":"002"}}
{"title":"H5,WX"}
{"index":{"_index":"hotel","_id":"003"}}
{"title":"WX"}
③ 当前用户的客户端为H5或App,当搜索“金都”关键词时应该构建的DSL如下:
GET /hotel/_search
{
"query": {
"match": {
"title": "APP,H5"
}
}
}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.3411059,
"hits" : [
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "001",
"_score" : 1.3411059,
"_source" : {
"title" : "APP,H5"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "002",
"_score" : 0.43445712,
"_source" : {
"title" : "H5,WX"
}
}
]
}
}
06. ElasticSearch 中文分词器
比较常用的第三方中文分析器是HanLP和IK分析器。
18. ElasticSearch ik分析器
Elasticsearch Ik分词器是一种基于Java开发的中文分词器,它是Elasticsearch官方推荐的中文分词器之一。Ik分词器支持细粒度和智能分词两种分词模式,可以根据不同的需求进行选择。细粒度模式适用于搜索引擎等需要精确匹配的场景,而智能模式则适用于一般的文本分析场景。
Ik分词器还支持自定义词典,可以通过添加自定义词典来提高分词的准确性。同时,Ik分词器还支持多种分词器插件,如拼音分词器、同义词分词器等,可以根据具体需求进行选择和配置。
总的来说,Elasticsearch Ik分词器是一种功能强大、灵活性高的中文分词器,可以满足各种中文文本分析的需求。
19. ElasticSearch 分析器 ik_smart 和 ik_max_word
IK分析器提供了两个子分析器,即 ik_smart 和 ik_max_word,另外它还提供了两个和分析器同名的子分词器。
下例使用ik_max_word分析器对待测试文本进行分析:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "金都嘉怡假日酒店"
}
{
"tokens" : [
{
"token" : "金都",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "嘉",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "怡",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "假日酒店",
"start_offset" : 4,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "假日",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "酒店",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 5
}
]
}
下例使用ik_smart分析器对待测试文本进行分析:
POST _analyze
{
"analyzer": "ik_smart",
"text": "金都嘉怡假日酒店"
}
{
"tokens" : [
{
"token" : "金都",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "嘉",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "怡",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "假日酒店",
"start_offset" : 4,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 3
}
]
}
从上述两个分析结果中可以看到,ik_max_word和ik_smart分析器的主要区别在于切分词语的粒度上,ik_smart的切分粒度比较粗,而ik_max_word将文本进行了最细粒度的拆分,甚至穷尽了各种可能的组合。
20. ElasticSearch ik分析器如何使用
① 创建索引时指定使用IK分词器:
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"ik_analyzer": {
"tokenizer": "ik_max_word"
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_analyzer"
}
}
}
}
② 索引文档:
PUT /my_index/_doc/1
{
"content":"中国人民"
}
PUT /my_index/_doc/2
{
"content":"中国银行"
}
③ 查询时使用IK分词器:
GET /my_index/_search
{
"query": {
"match": {
"content": {
"query": "中国人民银行",
"analyzer": "ik_max_word"
}
}
}
}
{
"took" : 10,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.6807432,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 2.6807432,
"_source" : {
"content" : "中国人民"
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.9752057,
"_source" : {
"content" : "中国银行"
}
}
]
}
}
07. ElasticSearch 使用同义词
在搜索场景中,同义词用来处理不同的查询词,有可能是表达相同搜索目标的场景。例如,当用户的查询词为“带浴缸的酒店”和“带浴池的酒店”时,其实是想搜索有单独泡澡设施的酒店。再例如,在电商搜索中,同义词更是应用广泛,如品牌同义词Adidas和“阿迪达斯”,产品同义词“投影仪”和“投影机”,修饰同义词“大码”和“大号”等。用户在使用这些与同义词相关的关键词进行搜索时,搜索引擎返回的搜索结果应该是一致的。
用户还可以通过ES中的分析器来使用同义词,使用方式分为两种,一种是在建立索引时指定同义词并构建同义词的倒排索引,另一种是在搜索时指定字段的search_analyzer查询分析器使用同义词。
21. ElasticSearch 建立索引时使用同义词
在ES内置的分词过滤器中,有一种分词过滤器叫作synonyms,它是一种支持用户自定义同义词的分词过滤器。
① 建立索引时使用同义词分析器:
"settings"字段:该字段用于设置索引的分析器,其中包含了一个名为"ik_synonyms_filter"的同义词过滤器,用于将一些同义词进行转换。例如,"北京"和"首都"是同义词,"天津"和"天津卫"是同义词,"假日"和"度假"是同义词。
“mappings"字段:该字段用于定义索引中的文档类型及其属性。在这个例子中,只定义了一个"title"属性,它的类型是"text”,使用了名为"ik_analyzer_synonyms"的分析器。这个分析器使用了"ik_max_word"分词器,将文本进行分词,并使用"lowercase"过滤器将所有单词转换为小写字母,然后使用"ik_synonyms_filter"过滤器将同义词进行转换。
PUT /hotel
{
"settings": {
"analysis": {
"filter": { //定义分词过滤器
"ik_synonyms_filter": {
"type": "synonym",
"synonyms": [ //在分词过滤器中定义近义词
"北京,首都",
"天津,天津卫",
"假日,度假"
]
}
},
"analyzer": { //自定义分析器
"ik_analyzer_synonyms": {
"tokenizer": "ik_max_word", //指定分词器
"filter": [ //指定分词过滤器
"lowercase",
"ik_synonyms_filter"
]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_analyzer_synonyms" //指定索引时使用自定义的分析器
}
}
}
}
② 索引文档:
POST /_bulk
{"index":{"_index":"hotel","_id":"001"}}
{"title": "文雅假日酒店"}
{"index":{"_index":"hotel","_id":"002"}}
{"title": "北京金都嘉酒店"}
{"index":{"_index":"hotel","_id":"003"}}
{"title": "天津金都欣欣酒店"}
{"index":{"_index":"hotel","_id":"004"}}
{"title": "金都酒店"}
{"index":{"_index":"hotel","_id":"005"}}
{"title": "文雅精选酒店"}
③ 搜索文档:
GET /hotel/_search
{
"query": {
"match": {
"title": "首都度假"
}
}
}
{
"took" : 415,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.9320302,
"hits" : [
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "001",
"_score" : 1.9320302,
"_source" : {
"title" : "文雅假日酒店"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "002",
"_score" : 1.9320302,
"_source" : {
"title" : "北京金都嘉酒店"
}
}
]
}
}
由上面的结果可见,酒店标题中的“北京”和“假日”分别可以匹配查询词中的“首都”和“度假”,说明前面的同义词设置成功。
22. ElasticSearch 查询时使用同义词
在ES内置的分词过滤器中还有个分词过滤器叫作synonym_graph,它是一种支持查询时用户自定义同义词的分词过滤器。
① 建立索引时使用同义词分析器:
PUT /hotel
{
"settings": {
"analysis": {
"filter": { //定义分词过滤器
"ik_synonyms_graph_filter": {
"type": "synonym_graph",
"synonyms": [ //在分词过滤器中定义近义词
"北京,首都",
"天津,天津卫",
"假日,度假"
]
}
},
"analyzer": { //自定义分析器
"ik_analyzer_synonyms_graph": {
"tokenizer": "ik_max_word", //指定分词器
"filter": [ //指定分词过滤器
"lowercase",
"ik_synonyms_graph_filter"
]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_analyzer_synonyms_graph" //指定查询时使用自定义的分析器
}
}
}
}
② 索引文档:
POST /_bulk
{"index":{"_index":"hotel","_id":"001"}}
{"title": "文雅假日酒店"}
{"index":{"_index":"hotel","_id":"002"}}
{"title": "北京金都嘉酒店"}
{"index":{"_index":"hotel","_id":"003"}}
{"title": "天津金都欣欣酒店"}
{"index":{"_index":"hotel","_id":"004"}}
{"title": "金都酒店"}
{"index":{"_index":"hotel","_id":"005"}}
{"title": "文雅精选酒店"}
③ 检索文档:
GET /hotel/_search
{
"query": {
"match": {
"title": "首都度假"
}
}
}
{
"took" : 29,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.2929529,
"hits" : [
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "001",
"_score" : 1.2929529,
"_source" : {
"title" : "文雅假日酒店"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "002",
"_score" : 1.2929529,
"_source" : {
"title" : "北京金都嘉酒店"
}
}
]
}
}
08. ElasticSearch 使用停用词
23. ElasticSearch 自定义分析器使用停用词
Elasticsearch 支持使用停用词来提高搜索的准确性和效率。停用词是指在搜索中被忽略的常见词语,例如“的”、“是”、“在”等。这些词语在搜索中出现的频率很高,但它们并没有提供有用的信息,因此可以被忽略。
在 Elasticsearch 中,可以使用停用词过滤器来过滤掉停用词。停用词过滤器可以在索引和搜索时使用。在索引时,可以在分析器中配置停用词过滤器,以便在索引文档时过滤掉停用词。在搜索时,可以在查询中使用停用词过滤器,以便在搜索时过滤掉停用词。
① 可以通过创建自定义分析器的方式使用停用词,方法是在分析器中指定停用词过滤器,在过滤器中可以指定若干个停用词。下面使用standard分词器和停用词过滤器组成一个自定义分析器进行索引定义DSL如下:
PUT /my_index
{
"settings": {
"analysis": {
"filter": {
"my_top_filter":{
"type":"stop",
"stopwords":["我","的","这"]
}
},
"analyzer": {
"standard_stop":{
"tokenizer": "standard",
"filter":["my_top_filter"]
}
}
}
},
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "standard_stop"
}
}
}
}
② 使用上述分析器进行文本分析,DSL如下:
POST /my_index/_analyze
{
"field": "title",
"text": "我的酒店"
}
{
"tokens" : [
{
"token" : "酒",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "店",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
}
]
}
通过以上结果可以看到,“我的酒店”中的“我”和“的”已经被停用词过滤器过滤,只剩下“酒”和“店”。但是“酒”的开始位置是2,“店”的开始位置是3,说明分析结果中“我”和“的”的位置被保留了下来,这种特意保留停用词的方式有助于后续的模糊搜索。
24. 在内置分析器中使用停用词
① 其实,像standard这种常用的分析器都自带有停用词过滤器,只需要对其参数进行相应设置即可。以下示例中使用standard分析器并通过设置其stopwords属性进行停用词的设定:
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_standard": {
"type": "standard",
"stopwords":["我","的","这"]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "my_standard"
}
}
}
}
② 使用上述分析器进行文本分析,DSL如下:
POST /my_index/_analyze
{
"field": "title",
"text": "我的酒店"
}
{
"tokens" : [
{
"token" : "酒",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "店",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
}
]
}
09. ElasticSearch 高亮显示搜索
25. ElasticSearch 高亮显示搜索基本使用
在ES中通过设置DSL的highlight参数可以对搜索的字段高亮显示。
① 索引文档,构造数据:
PUT /my_index
{
"mappings": {
"properties": {
"title":{
"type": "text"
},
"content":{
"type": "text"
}
}
}
}
PUT /my_index/_doc/1
{
"title": "文雅酒店",
"content": "Beijing City"
}
PUT /my_index/_doc/2
{
"title": "孟连酒店",
"content": "Huaibei City"
}
② 高亮显示搜索:
GET /my_index/_search
{
"query": {
"match": {
"title": {
"query": "金都怡家酒店"
}
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
其中设定对title字段的匹配结果进行高亮显示的标记标签,此处使用默认的HTML标签<em></em>,因此将title对应的值置为空对象。上述DSL的搜索结果如下:
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.36464313,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.36464313,
"_source" : {
"title" : "文雅酒店",
"content" : "Beijing City"
},
"highlight" : {
"title" : [
"文雅<em>酒</em><em>店</em>"
]
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.36464313,
"_source" : {
"title" : "孟连酒店",
"content" : "Huaibei City"
},
"highlight" : {
"title" : [
"孟连<em>酒</em><em>店</em>"
]
}
}
]
}
}
在每个搜索结果中增加了一个highlight子结果,其中将查询字段中匹配上的字符串都用HTML标签<em></em>进行了标记,这样的结果可以直接传送到前端,前端根据标记标签进行特殊化处理即可完成匹配字符串的高亮显示。
③ 当然,如果希望使用其他HTML标签对匹配内容进行标记,可以在DSL中进行更改。以下DSL将匹配内容标记标签改为了<high></high>:
GET /my_index/_search
{
"query": {
"match": {
"title": {
"query": "酒店"
}
}
},
"highlight": {
"fields": {
"title": {
"pre_tags": "<high>",
"post_tags": "</high>"
}
}
}
}
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.36464313,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.36464313,
"_source" : {
"title" : "文雅酒店",
"content" : "Beijing City"
},
"highlight" : {
"title" : [
"文雅<high>酒</high><high>店</high>"
]
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.36464313,
"_source" : {
"title" : "孟连酒店",
"content" : "Huaibei City"
},
"highlight" : {
"title" : [
"孟连<high>酒</high><high>店</high>"
]
}
}
]
}
}
26. SpringBoot整合ES实现高亮显示
@Slf4j
@Service
public class ElasticSearchImpl {
@Autowired
private RestHighLevelClient restHighLevelClient;
public void searchUser() throws IOException {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// query
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", "酒店");
searchSourceBuilder.query(matchQueryBuilder);
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<high>");
highlightBuilder.postTags("</high>");
highlightBuilder.field("title");
// highlight
searchSourceBuilder.highlighter(highlightBuilder);
SearchRequest searchRequest = new SearchRequest(new String[]{"my_index"},searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(searchResponse);
}
}
10. ElasticSearch 拼写纠错
用户在使用搜索引擎的过程中,输入的关键词可能会出现拼写错误的情况。针对错误的关键词,绝大多数的搜索引擎都能自动识别并进行纠正,然后将纠正后的关键词放到索引中匹配数据。如果拼写错误特别多导致无法纠正,则会直接告知用户当前搜索没有匹配的结果。
也可以使用ES进行拼写纠错,首先需要搜集一段时间内用户搜索日志中有搜索结果的查询词,然后单独建立一个纠正词索引。当用户进行搜索时,如果在商品索引中没有匹配到结果,则在纠正词索引中进行匹配,如果有匹配结果则给出匹配词,并给出该匹配词对应的商品结果,如果没有匹配结果则告知用户没有搜索到商品。
在ES中进行纠错匹配时使用fuzzy-match搜索,该搜索使用编辑距离和倒排索引相结合的形式完成纠错,什么是编辑距离呢?词语A经过多次编辑后和词语B相等,编辑的次数就叫作编辑距离。可以这样定义一次编辑:替换一个字符,或删除一个字符,或插入一个字符,或交换两个字符的位置。
① 索引文档:
PUT /error_correct
{
"mappings": {
"properties": {
"hot_word": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
POST /_bulk
{"index":{"_index":"error_correct","_id":"001"}}
{"hot_word": "王府井"}
{"index":{"_index":"error_correct","_id":"002"}}
{"hot_word": "王府中环"}
{"index":{"_index":"error_correct","_id":"003"}}
{"hot_word": "双井"}
{"index":{"_index":"error_correct","_id":"004"}}
{"hot_word": "成府路"}
{"index":{"_index":"error_correct","_id":"005"}}
{"hot_word": "大王庄"}
② ES的match查询支持模糊匹配,这里的模糊匹配指的是ES将查询文本进行分词进而得到分词列表,然后将列表中的词语分别和索引中的词语进行匹配,这时按照编辑距离进行模糊匹配,在符合编辑距离阈值的情况下才算是匹配。如下指定编辑距离为1:文章来源:https://www.toymoban.com/news/detail-741531.html
GET /error_correct/_search
{
"query": {
"match": {
"hot_word":{
"query": "王府景",
"operator": "and",
"fuzziness": 1
}
}
}
}
{
"took" : 1212,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.2354476,
"hits" : [
{
"_index" : "error_correct",
"_type" : "_doc",
"_id" : "001",
"_score" : 1.2354476,
"_source" : {
"hot_word" : "王府井"
}
},
{
"_index" : "error_correct",
"_type" : "_doc",
"_id" : "004",
"_score" : 0.0,
"_source" : {
"hot_word" : "成府路"
}
}
]
}
}
通过以上结果可以看出,纠错结果基本符合预期,但是“成府路”也出现在搜索结果中,这是为什么呢?按照hot_word字段默认的分析器对查询词“王府景”和查询词“成府路”进行分析,查询词“王府景”被切分成了“王府”和“景”;查询词“成府路”被切分成了“成”“府”和“路”。因为“王府”和“府”的编辑距离为1,符合模糊匹配的编辑距离的阈值,因此“成府路”被匹配上。文章来源地址https://www.toymoban.com/news/detail-741531.html
到了这里,关于ElasticSearch系列 - SpringBoot整合ES:分析器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!