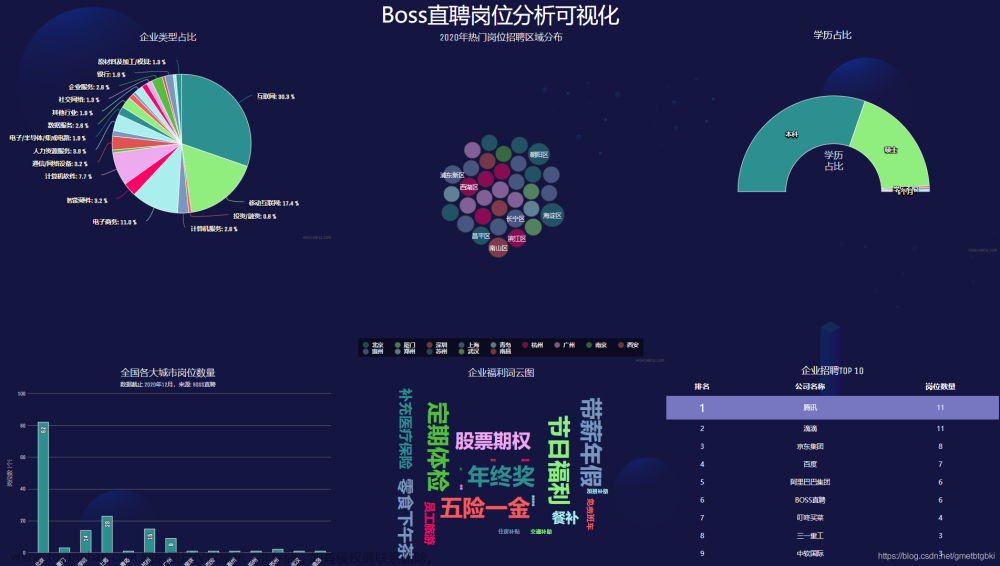
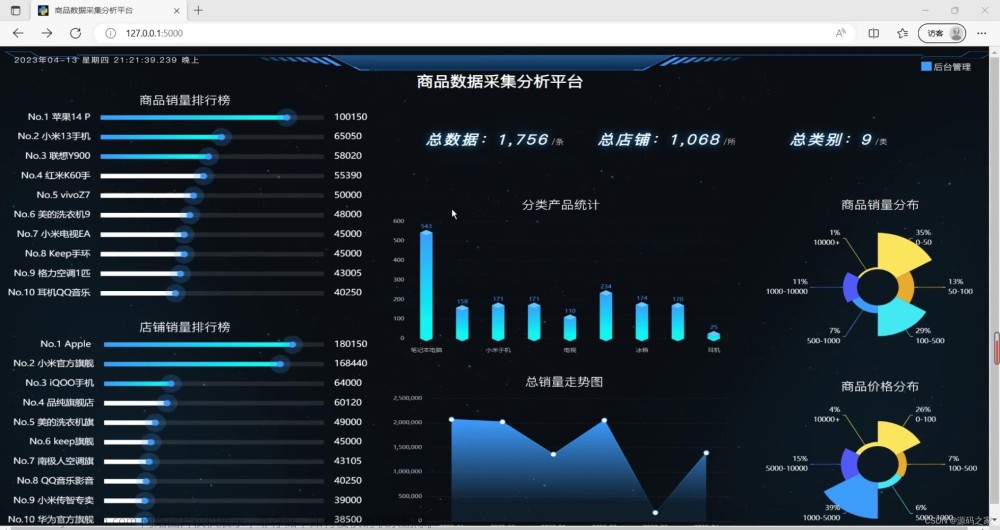
记得学妹刚毕业那天,为了不让学妹毕业就失业,连夜我就用Python采集了上万份岗位,分析出最合适她的工作。
为此,学妹连夜来我家表示感谢😍


我们开始今天的正题吧
首先要准备这些
软件
- Python 3.8
- Pycharm
模块使用
- requests # 数据请求模块 pip install requests
- execjs # 编译js代码模块 pip install PyExecJS
- csv 保存表格模块
前两个需要手动安装,win + R 输入cmd 输入安装命令 pip install 模块名 (如果你觉得安装速度比较慢, 你可以切换国内镜像源)
如何实现爬虫程序
一. 数据来源分析
- 明确需求: 明确采集的网站以及数据内容
- 网址: https://www.liepin.com/zhaopin/?inputFrom=www_index&workYearCode=0&key=python&scene=input&ckId=z66s3wh10u4fpsartgqu6hpk0uadh1kb&dq=
- 数据: 职位信息 - 抓包分析: 通过浏览器开发者工具进行抓包分析
- 打开开发者工具: F12
- 刷新网页
- 通过关键字搜索找到对应的数据包
职位数据包: https://api-c.liepin.com/api/com.liepin.searchfront4c.pc-search-job
二. 代码实现步骤
- 发送请求 -> 模拟浏览器对于url地址发送请求
- 获取数据 -> 获取服务器返回响应数据
- 解析数据 -> 提取我们需要的数据内容
- 保存数据 -> 保存表格文件中
代码解析
发送请求
# 模拟浏览器 headers = { 'Cookie': '__uuid=1697715537830.29; __tlog=1697715537842.14%7C00000000%7C00000000%7Cs_00_t00%7Cs_00_t00; XSRF-TOKEN=2Uk6ks7eQzClntAW4e3-rg; __gc_id=b3d87325dfce4ed2a845c293e7719666; _ga=GA1.1.511850321.1697715541; acw_tc=2760828916977155414545948ecf12c457b2d8550e00549caffbda5e0ffef1; Hm_lvt_a2647413544f5a04f00da7eee0d5e200=1697715542; __session_seq=3; __uv_seq=3; Hm_lpvt_a2647413544f5a04f00da7eee0d5e200=1697715546; __tlg_event_seq=52; _ga_54YTJKWN86=GS1.1.1697715541.1.1.1697717226.0.0.0', 'Host': 'api-c.liepin.com', 'Origin': 'https://www.liepin.com', 'Referer': 'https://www.liepin.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36', 'X-Client-Type': 'web', 'X-Fscp-Bi-Stat': '{"location": "https://www.liepin.com/zhaopin/?inputFrom=www_index&workYearCode=0&key=python&scene=input&ckId=z66s3wh10u4fpsartgqu6hpk0uadh1kb&dq="}', 'X-Fscp-Fe-Version': '', 'X-Fscp-Std-Info': '{"client_id": "40108"}', 'X-Fscp-Trace-Id': '8a1776f0-6366-46c1-88e6-8439dd8e7f2b', 'X-Fscp-Version': '1.1', 'X-Requested-With': 'XMLHttpRequest', 'X-XSRF-TOKEN': '2Uk6ks7eQzClntAW4e3-rg', } for page in range(1, 6): # 请求链接 url = 'https://api-c.liepin.com/api/com.liepin.searchfront4c.pc-search-job' # 读取js代码文件 f = open('猎聘.js', mode='r', encoding='utf-8').read() # 编译JS代码文件 js_code = execjs.compile(f) # 调用JS函数获取ckId值 ckId = js_code.call('r', 32) print(ckId) # 请求参数 data = { "data": { "mainSearchPcConditionForm": { "city": "410", "dq": "410", "pubTime": "", "currentPage": page, "pageSize": 40, "key": "python", "suggestTag": "", "workYearCode": "0", "compId": "", "compName": "", "compTag": "", "industry": "", "salary": "", "jobKind": "", "compScale": "", "compKind": "", "compStage": "", "eduLevel": "" }, "passThroughForm": { "ckId": ckId, "fkId": "yng225lwgtfiy60pn8auwftcpe0c304b", "scene": "page", "sfrom": "search_job_pc", "skId": "yng225lwgtfiy60pn8auwftcpe0c304b", } } } # 发送请求 response = requests.post(url=url, json=data, headers=headers)
获取响应json数据
json_data = response.json()
解析数据, 提取我们需要职位信息
job_list = json_data['data']['data']['jobCardList'] # for循环遍历 for job in job_list: # 提取城市信息 1. 上海 2. 上海-浦东新区 city_info = job['job']['dq'].split('-') # --> ['上海'] / ['上海', '浦东新区'] if len(city_info) == 2: # 有两个元素说明含有区域 city = city_info[0] # 城市 area = city_info[1] # 区域 else: city = city_info[0] # 城市 area = '未知' # 区域 # 薪资 salary_info = job['job']['salary'].split('·') if len(salary_info) == 2: salary = salary_info[0] year_money = salary_info[-1] else: salary = salary_info[0] year_money = '12薪' # 字典取值提取数据内容 dit = { '职位': job['job']['title'], '城市': city, '区域': area, '薪资': salary, '年薪': year_money, '经验': job['job']['requireWorkYears'], '学历': job['job']['requireEduLevel'], '公司': job['comp']['compName'], '领域': job['comp']['compIndustry'], '规模': job['comp']['compScale'], '标签': ','.join(job['job']['labels']), '公司详情页': job['comp']['link'], '职位详情页': job['job']['link'], } csv_writer.writerow(dit) print(dit)
创建文件对象
csv_file = open('data.csv', mode='w', encoding='utf-8', newline='') csv_writer = csv.DictWriter(csv_file, fieldnames=[ '职位', '城市', '区域', '薪资', '年薪', '经验', '学历', '公司', '领域', '规模', '标签', '公司详情页', '职位详情页', ]) # 完整代码和视频讲解我都打包好了 # 都放在这个抠裙了 708525271
写入表头
csv_writer.writeheader()
可以看到数据已经获取到,保存在表格里了~
 文章来源:https://www.toymoban.com/news/detail-741771.html
文章来源:https://www.toymoban.com/news/detail-741771.html
好了,本次分享到这结束了,大家快去试试吧~文章来源地址https://www.toymoban.com/news/detail-741771.html
到了这里,关于学妹刚毕业那天,我连夜用Python采集了上万份岗位数据,只为给她找一份好工作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!