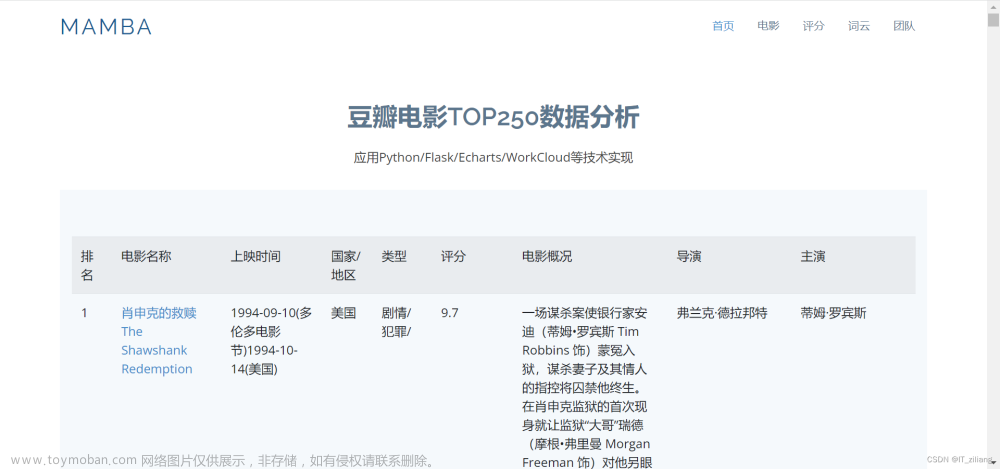
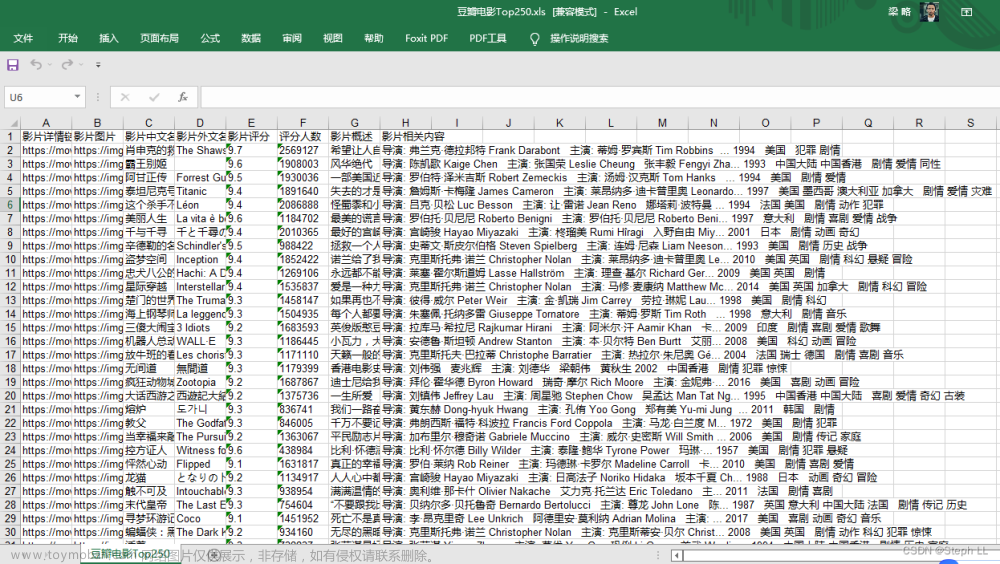
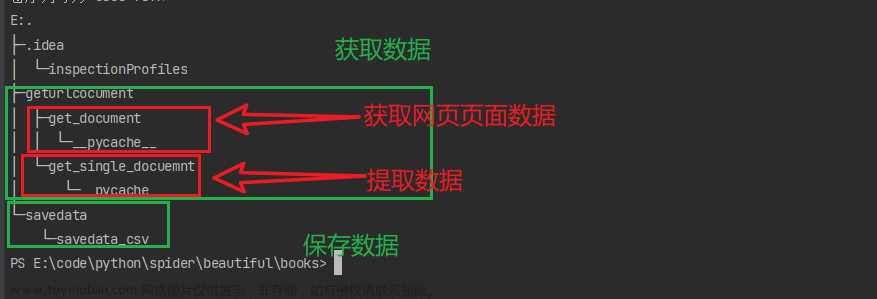
先贴上爬取的脚本:
import requests
import re
for i in range(1,11):
num=(i-1)*25
url=f"https://movie.douban.com/top250?start={num}&filter="
head={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"}#伪造请求头
res=requests.get(url,headers=head)
#print(res.text)
format=re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
data=format.finditer(res.text)
for i in data:
dic=i.groupdict()
print(dic)
首先导入requests库,主要是对网站发起请求
然后就是re库,主要是在python中能够使用正则表达式匹配
url=f"https://movie.douban.com/top250?start={num}&filter="
这边url中加上f是为了能识别num变量,主要是为了能识别多个网页
head={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"}
修改请求头,因为某瓣有反爬机制,不修改的,该请求头默认为python的标识,修改的请求头可在f12的netword数据中获取

该请求头随意修改就行,合理就行文章来源地址https://www.toymoban.com/news/detail-741840.html
format=re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
这里是re的compile函数,可以写正则表达式为后续使用,re.S是为了匹配到换行符,因为.*?中的.是没办法匹配到换行符的,?P<name>,是将匹配到的数据存到name分组中
data=format.finditer(res.text)
进行正则匹配,finditer将匹配的数据存入迭代器,方便后面for循环
for i in data:
dic=i.groupdict()
print(dic)
这里的groupdict是将分组数据提取出来,是以字典的形式
测试结果如下:

文章来源:https://www.toymoban.com/news/detail-741840.html
到了这里,关于【爬虫】一次爬取某瓣top电影前250的学习记录的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[Python练习]使用Python爬虫爬取豆瓣top250的电影的页面源码](https://imgs.yssmx.com/Uploads/2024/02/797225-1.png)

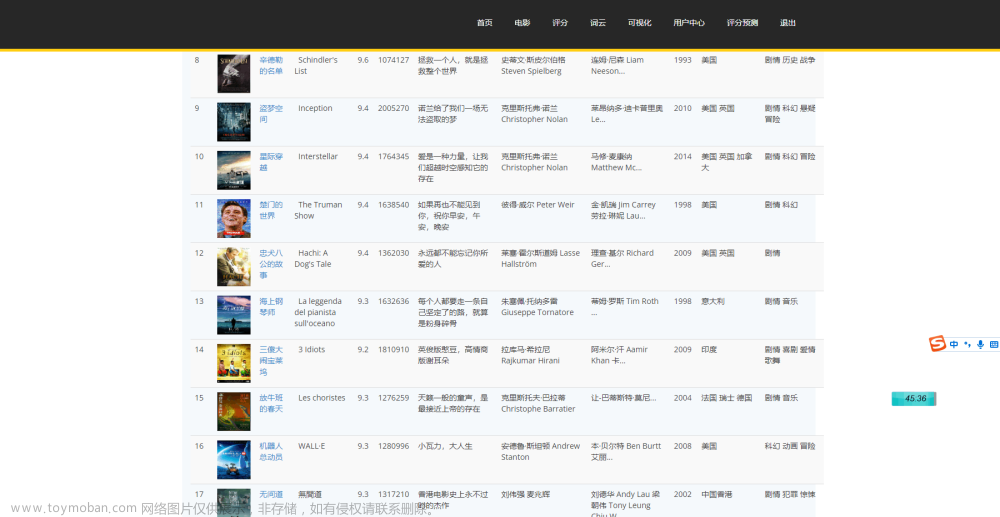
![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2024/01/415693-1.png)