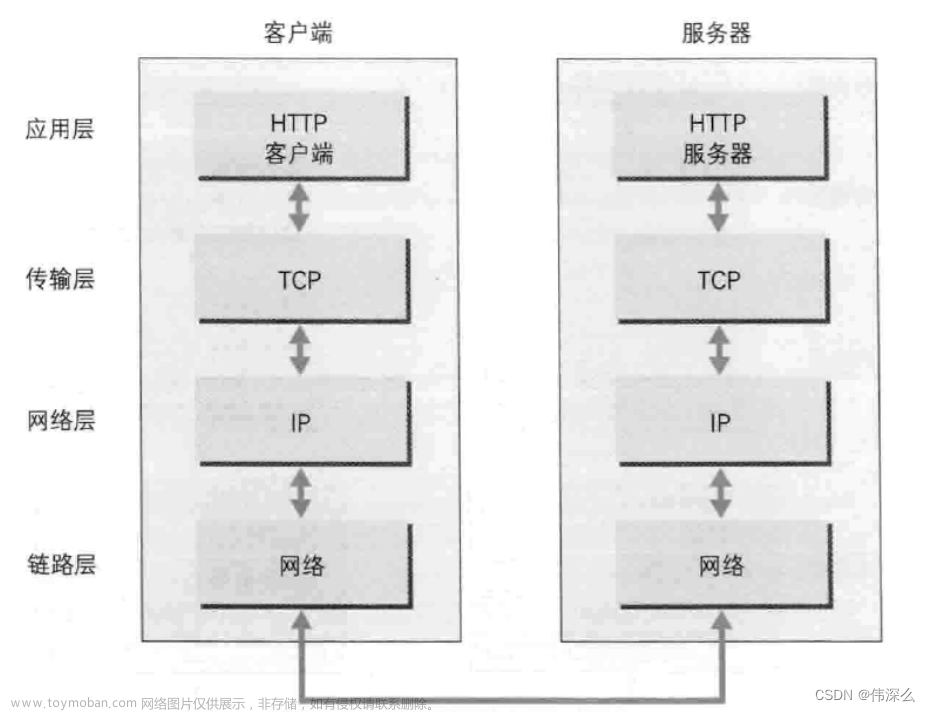
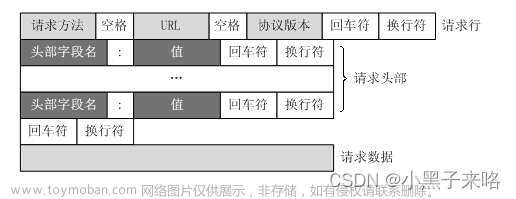
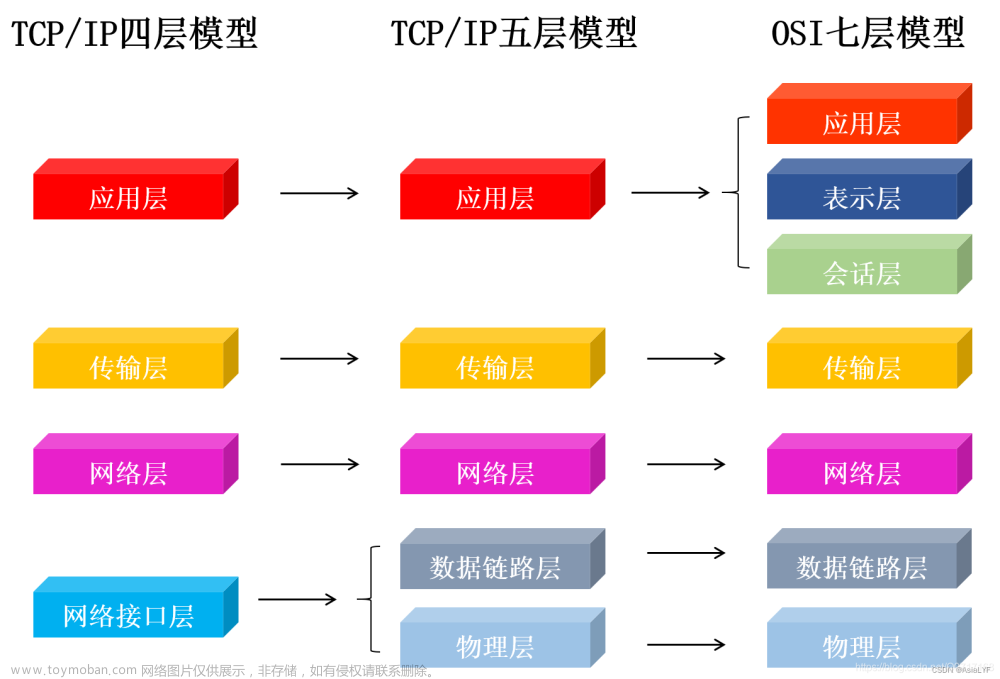
R语言爬虫是指使用R语言编写程序,自动从互联网上获取数据的过程。在R语言中,可以使用三个主要的包(XML、RCurl、rvest)来实现爬虫功能。了解HTML等网页语言对于编写爬虫程序也非常重要,因为这些语言是从网页中提取数据的关键。网页语言通常是树形结构,只要理解了这些语言的基本语法,就可以找到需要的数据位置并提取数据。

代码实现
# 导入httr包
library(httr)
# 定义爬虫ip服务器地址和端口
proxy_host <- "duoip"
proxy_port <- 8000
# 使用httr包中的GET函数,设置爬虫ip服务器,请求alitrip的视频
video_url <- GET("alitrip",
config = list(proxies = list(http = paste0("http://", proxy_host, ":", proxy_port),
https = paste0("http://", proxy_host, ":", proxy_port))))
代码解释
1、library(httr):导入httr包,它是R语言中用于发送HTTP请求的包。
2、proxy_host <- "duoip"和proxy_port <- 8000:定义爬虫ip服务器地址和端口。在这个例子中,我们使用的是duoip的8000端口。文章来源:https://www.toymoban.com/news/detail-741960.html
3、video_url <- GET("alitrip", config = list(proxies = list(http = paste0("http://", proxy_host, ":", proxy_port), https = paste0("http://", proxy_host, ":", proxy_port)))):使用httr包中的GET函数,设置爬虫ip服务器,请求alitrip的视频。其中,video_url是返回的视频URL,config参数中的proxies列表用于设置爬虫ip服务器,http和https分别对应HTTP和HTTPS协议的爬虫ip服务器地址和端口。注意,爬虫ip服务器地址和端口需要以http://或https://开头,后面跟着地址和端口,用冒号分隔。文章来源地址https://www.toymoban.com/news/detail-741960.html
到了这里,关于R语言使用HTTP爬虫IP写一个程序的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!