Hadoop HA安装部署
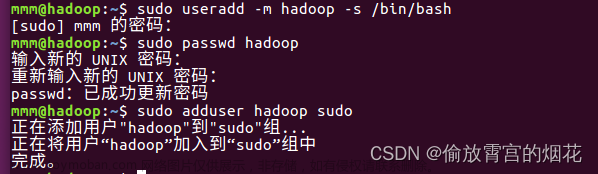
本文章使用root用户完成相关配置与启动、这里分为master、slave1、slave2进行配置
一、将hadoop解压至需要的目录下

二、配置hadoop-env.sh启动文件
export JAVA_HOME=/opt/module/jdk1.8.0_212
//设置JDK路径
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_ZKFC_USER=root
//配置root用户权限(不配置将无法启动对应的进程)三、配置hdfs-site.xml文件
<property>
<name>dfs.nameservices</name>
<value>hadoopcluster</value>
</property>
<!-- namenode存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-2.7.7/namenode</value>
</property>
<!-- datanode存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/module/hadoop-2.7.7/datanode</value>
</property>
<property>
<name>dfs.ha.namenodes.hadoopcluster</name>
<value>nn1,nn2</value>
</property>
<!-- 指定namenode1 -->
<property>
<name>dfs.namenode.rpc-address.hadoopcluster.nn1</name>
<value>master:9000</value>
</property>
<!-- 指定namenode2 -->
<property>
<name>dfs.namenode.rpc-address.hadoopcluster.nn2</name>
<value>slave1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoopcluster.nn1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoopcluster.nn2</name>
<value>slave1:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>
qjournal://master:8485;slave1:8485;slave2:8485/lagou
</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/hadoop-2.7.7/journalnode</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>四、配置core-site.xml文件
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopcluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.7/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>五、配置yarn-site.xml文件
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启⽤resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave1</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>六、分发至slave1、slave2
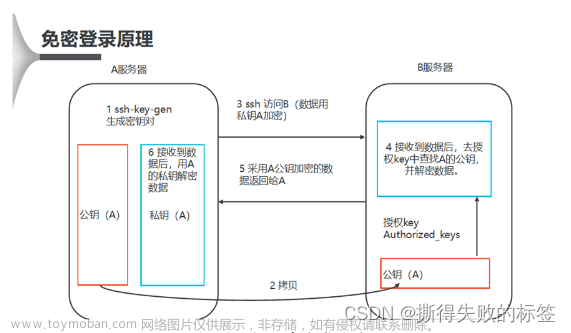
配置完成后,将hadoop配置文件分发至slave1、slave2,这里需要配置ssh免密登入,通过scp进行分发。详细见本栏目文章。
七、启动
1、启动zookeeper
在zookeeper目录下启动,zookeeper配置请见本人主页分栏。
./bin/zkServer.sh start2、启动journalnode
JournalNode是Hadoop集群中的一个组件,用于维护HDFS的命名空间和事务日志。它通常作为HDFS高可用性功能的一部分,在NameNode和DataNode之间提供一个分布式共享的存储介质,以确保在节点失效时能够快速进行故障切换。
hadoop-daemon.sh start journalnode3、初始化namenode、ZKfc
如果已经运行过请删除hadoop目录下的logs、datanode、namenode的存储目录
hdfs namenode -format
//初始化namenode
hdfs zkfc -formatZK
//初始化zkfc4、slave1上同步namenode
先启动master上的namenode
hadoop-daemon.sh start namenode
//在slave1上输入同步namenode
hdfs namenode -bootstrapStandby5、启动集群
start-all.sh该命令需要配置hadoop的全局环境
八、查看三台机子jps进程情况


 文章来源:https://www.toymoban.com/news/detail-742011.html
文章来源:https://www.toymoban.com/news/detail-742011.html
文章来源地址https://www.toymoban.com/news/detail-742011.html
到了这里,关于Hadoop HA-hadoop完全分布式高可用集群配置、高可用集群启动方式、master/slave1/slave2配置的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!