一、Hadoop HDFS(分布式文件系统)
为什么要分布式存储数据
假设一个文件有100tb,我们就把文件划分为多个部分,放入到多个服务器
靠数量取胜,多台服务器组合,才能Hold住
数据量太大,单机存储能力有上限,需要靠数量来解决问题
数量的提升带来的是网络传输,磁盘读写,CUP,内存等各方面的综合提升。分布式组合在一起可以达到
1+1>2的效果
二、大数据体系中,分布式的调度主要有2类架构模式:
1.去(无)中心化模式
去中心化模式,没有明确的中心,众多服务器之间基于特定规则进行同步协调

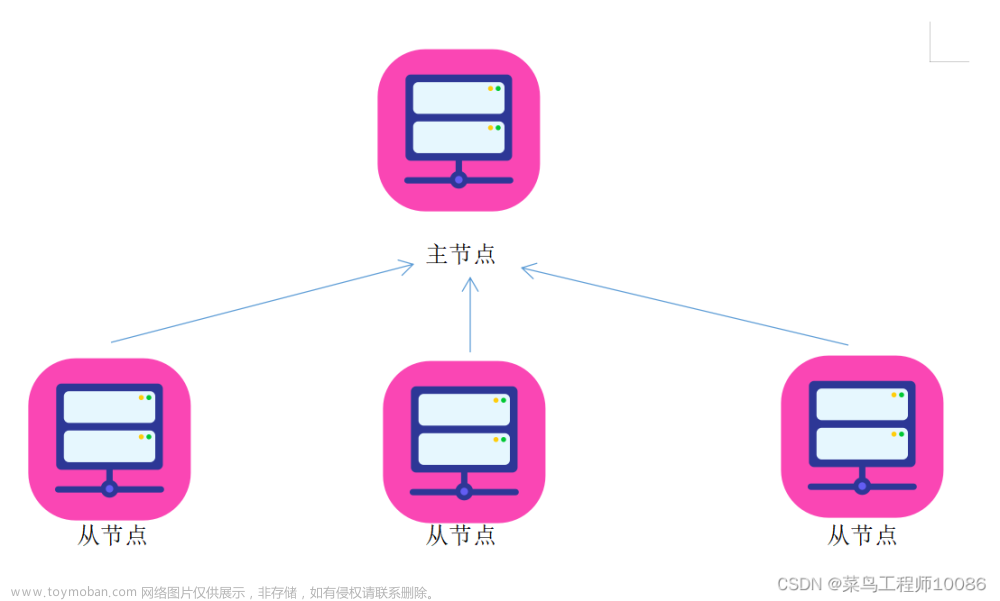
2.中心化模式
中心化模式

主从模式,大数据框架,大多数的基础架构上,都是符合:中心化模式的
即:有一个中心节点(服务器)来统筹其他服务器的工作,统一指挥,统一调派,避免混乱
这种模式,也被称之为:一主多从模式,简称主从模式(Master And Slaves)
主从模式(中心化模式)在现实生活中同样很常见:
公司企业管理,组织管理,行政管理
我们学习的Hadoop框架,就是一个典型的主从模式(中心化模式)架构的技术框架
三、HDFS是Hadoop三大组件(HDFS,MapReduce,YARN)之一
全程是:Hadoop Distributed File System(Hadoop分布文件系统)
是Hadoop技术栈内提供的分布式数据存储解决方案
可以在多台服务器上构建存储集群,存储海量的数据
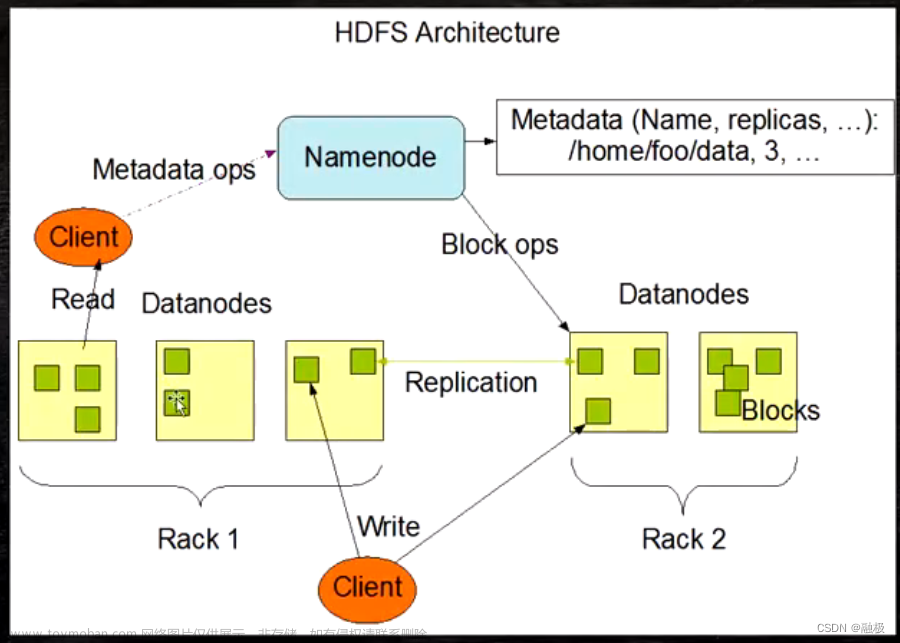
HDFS就是一个典型的主从架构,拥有三个角色,以下就是HDFS的基础架构

1.NameNode:
HDFS系统的主角色,是一个独立的进程
负责管理HDFS整个文件系统
负责管理Datanode
2.Datanode:
HDFS系统的从角色,是一个独立进程
主要负责数据的存储,即存入数据和取出数据
3.SecondaryNameNode:
NameNode的辅助,是一个独立进程
主要帮忙NameNode完成源数据整理工作(打杂)
四、HDFS架构概述
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
五、YARN架构概述
1)ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。文章来源:https://www.toymoban.com/news/detail-742352.html
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关文章来源地址https://www.toymoban.com/news/detail-742352.html
到了这里,关于Hadoop HDFS(分布式文件系统)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!