概述
本文介绍使用ELK(elasticsearch、logstash、kibana) + kafka来搭建一个日志系统。主要演示使用spring aop进行日志收集,然后通过kafka将日志发送给logstash,logstash再将日志写入elasticsearch,这样elasticsearch就有了日志数据了,最后,则使用kibana将存放在elasticsearch中的日志数据显示出来,并且可以做实时的数据图表分析等等。
详细
本文介绍使用ELK(elasticsearch、logstash、kibana) + kafka来搭建一个日志系统。主要演示使用spring aop进行日志收集,然后通过kafka将日志发送给logstash,logstash再将日志写入elasticsearch,这样elasticsearch就有了日志数据了,最后,则使用kibana将存放在elasticsearch中的日志数据显示出来,并且可以做实时的数据图表分析等等。
为什么用ELK
以前不用ELK的做法
最开始我些项目的时候,都习惯用log4j来把日志写到log文件中,后来项目有了高可用的要求,我们就进行了分布式部署web,这样我们还是用log4j这样的方式来记录log的话,那么就有N台机子的N个log目录,这个时候查找log起来非常麻烦,不知道问题用户出错log是写在哪一台服务器上的,后来,想到一个办法,干脆把log直接写到数据库中去,这样做,虽然解决了查找异常信息便利性的问题了,但存在两个缺陷:
1,log记录好多,表不够用啊,又得分库分表了,
2,连接db,如果是数据库异常,那边log就丢失了,那么为了解决log丢失的问题,那么还得先将log写在本地,然后等db连通了后,再将log同步到db,这样的处理办法,感觉是越搞越复杂。
现在ELK的做法
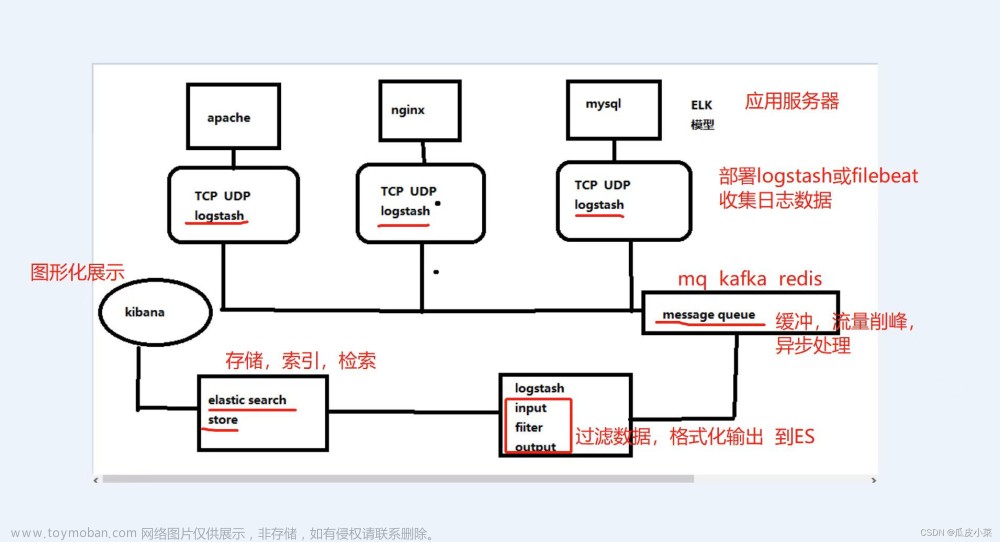
好在现在有了ELK这样的方案,可以解决以上存在的烦恼,首先是,使用elasticsearch来存储日志信息,对一般系统来说可以理解为可以存储无限条数据,因为elasticsearch有良好的扩展性,然后是有一个logstash,可以把理解为数据接口,为elasticsearch对接外面过来的log数据,它对接的渠道,有kafka,有log文件,有redis等等,足够兼容N多log形式,最后还有一个部分就是kibana,它主要用来做数据展现,log那么多数据都存放在elasticsearch中,我们得看看log是什么样子的吧,这个kibana就是为了让我们看log数据的,但还有一个更重要的功能是,可以编辑N种图表形式,什么柱状图,折线图等等,来对log数据进行直观的展现。
ELK职能分工
-
logstash做日志对接,接受应用系统的log,然后将其写入到elasticsearch中,logstash可以支持N种log渠道,kafka渠道写进来的、和log目录对接的方式、也可以对reids中的log数据进行监控读取,等等。
-
elasticsearch存储日志数据,方便的扩展特效,可以存储足够多的日志数据。
-
kibana则是对存放在elasticsearch中的log数据进行:数据展现、报表展现,并且是实时的。
怎样用ELK
首先说明一点,使用ELK是不需要开发的,只需要搭建环境使用即可。搭建环境,可以理解为,下载XX软件,然后配置下XX端口啊,XX地址啊,XX日志转发规则啊等等,当配置完毕后,然后点击XX bat文件,然后启动。
Logstash配置
可以配置接入N多种log渠道,现状我配置的只是接入kafka渠道。
配置文件在\logstash-2.3.4\config目录下
要配置的是如下两个参数体:
-
input:数据来源。
-
output:数据存储到哪里。
input {
kafka {
zk_connect => "127.0.0.1:2181"
topic_id => "mylog_topic"
}
}
filter {
#Only matched data are send to output.
}
output {
#stdout{}
# For detail config for elasticsearch as output,
# See: https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html
elasticsearch {
action => "index" #The operation on ES
hosts => "127.0.0.1:9200" #ElasticSearch host, can be array.
index => "my_logs" #The index to write data to.
}
}Elasticsearch配置
配置文件在\elasticsearch-2.3.3\config目录下的elasticsearch.yml,可以配置允许访问的IP地址,端口等,但我这里是采取默认配置。
Kibana配置
配置文件在\kibana-4.5.4-windows\config目录下的kibana.yml,可以配置允许访问的IP地址,端口等,但我这里是采取默认配置。
这里有一个需要注意的配置,就是指定访问elasticsearch的地址。我这里是同一台机子做测试,所以也是采取默认值了。
# The Elasticsearch instance to use for all your queries.
# elasticsearch.url: "http://localhost:9200"关于ELK的配置大致上,就这样就可以了,当然其实还有N多配置项可供配置的,具体可以google。这里就不展开说了。
具体的配置请下载运行环境,里面有具体的配置。
和spring aop日志对接
elk环境搭建完毕后,需要在应用系统做日志的aop实现。
部分spring配置
<aop:aspectj-autoproxy />
<aop:aspectj-autoproxy proxy-target-class="true" />
<!-- 扫描web包,应用Spring的注解 -->
<context:component-scan base-package="com.demodashi">
<context:include-filter type="annotation" expression="org.springframework.stereotype.Controller" />
<context:exclude-filter type="annotation" expression="javax.inject.Named" />
<context:exclude-filter type="annotation" expression="javax.inject.Inject" />
</context:component-scan>部分java代码
package com.demodashi.aop.annotation;
import java.lang.annotation.*;
/**
*自定义注解 拦截service
*/
@Target({ElementType.PARAMETER, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface ServiceLogAnnotation {
String description() default "";
}
package com.demodashi.aop.annotation;
import java.lang.annotation.*;
/**
*自定义注解 拦截Controller
*/
@Target({ElementType.PARAMETER, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface ControllerLogAnnotation {
String description() default "";
}代码截图

日志和kafka、和logstash、elasticsearch、kibana直接的关系
ELK,kafka、aop之间的关系
1、aop对日志进行收集,然后通过kafka发送出去,发送的时候,指定了topic(在spring配置文件中配置为 topic="mylog_topic")
2、logstash指定接手topic为 mylog_topic的kafka消息(在config目录下的配置文件中,有一个input的配置)
3、然后logstash还定义了将接收到的kafka消息,写入到索引为my_logs的库中(output中有定义)
4、再在kibana配置中,指定要连接那个elasticsearch(kibana.yml中有配置,默认为本机)
5、最后是访问kibana,在kibana的控制台中,设置要访问elasticsearch中的哪个index。
部署ELK + kafka环境
我本机的环境是jdk8.0,我记得测试的过程中,elasticsearch对jdk有特别的要求,必须是jdk7或者以上。
下载运行环境附件,并解压后,看到如下:

这些运行环境,在每个软件里面,都有具体的启动说明,如kafka的目录下,这样:

按照启动说明的命令来执行,即可启动。
这里需要说明一点,最先启动,应该是zookeeper,然后才是其他的,其他几个没有严格区分启动顺序。
直接在window下面,同一台机子启动即可。除了kibana-4.5.4-windows外,其他几个也是可以在linux下运行的。文章来源:https://www.toymoban.com/news/detail-742519.html
本文由“未央天际人家账号”发布,2023年11月2日文章来源地址https://www.toymoban.com/news/detail-742519.html
到了这里,关于ELK + kafka 日志方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!