前言:本实验的所有路径均为本人计算机路径,有些路径需要看自己的,跟着我的一起做最好。普通用户下大部分命令需要加sudo,root模式下不用。如果怕麻烦,直接在root用户下操作。
目录
实验环境:
实验步骤:
一、配置NAT网络 ,分配静态IP地址
1.打开VMware,选择编辑,选择虚拟网络编辑器,选择NAT模式,取消选择使用本地DHCP服务将IP地址分配给虚拟机(进行完此操作,虚拟机应该是没网了)
2.点击上图中的NAT设置,查看并记住网关IP(要以自己电脑的为准)
3.打开控制面板\网络和 Internet\网络连接,右键VMnet8,查看属性,选择Ipv4,点击属性:
4.打开终端,查看网卡名称:
5.打开网络配置文件,配置网络:
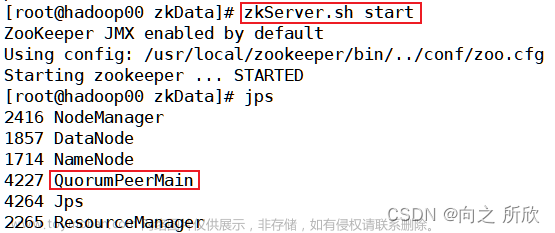
6.执行 reboot 命令重启系统(非必须)。
7.用 ping 命令验证网络是否通达(其实打开浏览器搜索试一下也可以):
二、关闭防火墙(可以防止后续ssh登录出现问题)
三、为了方便,修改host用户名(安装虚拟机的时候就直接起对名字就好了)
四、配置主机名与ip映射:
五、配置Java jdk1.8
1.在宿主机下载jdk1.8然后通过共享文件夹传到虚拟机
2.可以通过图形界面进入共享文件夹目录然后右键在终端打开:
3.使用命令进行解压,使用命令tar -zxf 刚才复制的名字 -C /usr/local(我选择将jdk安装至 /usr/local/ 中为例,也可以装在其他地方)
4.配置环境变量
5.刷新环境变量:(一定要做)
6.测试java命令是否可用:
六、安装配置hadoop
1.在宿主机下载hadoop然后通过共享文件夹传到虚拟机
2.可以通过图形界面进入共享文件夹目录然后右键在终端打开:
3.然后使用命令sudo tar -zxf 刚才复制的名字 -C /usr/local(我选择将 Hadoop 安装至 /usr/local/ 中为例,也可以装在其他地方)
4. 进入/usr/local/进行操作:
5. Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息(不查看也行,配置完环境变量查看即可):
6.配置环境变量(root模式下)
七、 安装配置ssh,配置root用户ssh登录
1.SSH介绍
2.配置root用户ssh登录:
八、克隆两个虚拟机
九、本机以及不同主机之间的ssh免密登录
1.先说一下原理:
2.自身免密的步骤,以A主机(假设登录名为name,相当于master的lee)为例:
3.主机之间免密登录(假设A:192.168.75.111,B:192.168.75.113。A登录名为lee,host名为Node1;B登录名为lee,host名为Node3)
4.总结(master,salve1,slave2本机的ssh免密登录以及相互之间的免密登录,登录名均为lee)
十、最终配置与调试
1.修改配置文件
2.将配置好的Hadoop分发到其他主机
3.格式化namenode
4.启动hadoop
5.浏览器web测试
本框架的分布式集群如下图所示(IP地址不一定跟图中一样)

实验环境:
ubuntu18.04
Hadoop版本:3.1.3
JDK版本:1.8
实验步骤:
一、配置NAT网络 ,分配静态IP地址
1.打开VMware,选择编辑,选择虚拟网络编辑器,选择NAT模式,取消选择使用本地DHCP服务将IP地址分配给虚拟机(进行完此操作,虚拟机应该是没网了)

2.点击上图中的NAT设置,查看并记住网关IP(要以自己电脑的为准)
我的是192.168.75.2:

实际上就是文章开头图中的这个:

3.打开控制面板\网络和 Internet\网络连接,右键VMnet8,查看属性,选择Ipv4,点击属性:


(选择使用下面的IP地址)查看ip地址,当这个地址跟虚拟机NAT设置里的网关(也就是上文所说的192.168.75.2)一样时,需要改变
当不一样时,改为192.168.75.x(即前三段数字与网关ip一样),x不能为2,以免与网关冲突,最好也不为0(注意要以自己电脑的为准)
这里我把ip地址设为192.168.75.1:

这个IP地址就是文章开头图片的这个:

然后修改默认网关为192.168.75.2与网关ip一样

4.打开终端,查看网卡名称:
输入ip addr 查看网卡名称(后续要用),本人网卡名称为ens33(基本上都是这个名字):
输入ls /etc/netplan查看配置文件:

从图上可以看出网络配置文件名为:01-network-manager-all.yaml
5.打开网络配置文件,配置网络:
输入(如果提示权限不够就用root模式):
vi /etc/netplan/01-network-manager-all.yaml
或vim /etc/netplan/01-network-manager-all.yaml
或gedit /etc/netplan/01-network-manager-all.yaml(仅适用于图形界面,最方便)
注:未安装vim时,使用vi命令可能会出bug,处理方法见我其他文章(未完待做)
修改文件如下(一定要注意缩进):
network:
ethernets:
ens33:
#配置的网卡名称
dhcp4: no
#关闭dhcp4
dhcp6: no
#关闭dhcp6
addresses: [192.168.75.115/24]
#设置本机IP地址(192.168.75.x,不能与下边的网关一样)及掩码
gateway4: 192.168.75.2
#设置网关(即虚拟机NAT设置里的网关)
nameservers:
addresses: [114.114.114.114,8.8.8.8]
#设置DNS
我的Node1(master)节点配置如下:
配置完应该是这样的(一定要注意缩进,空格和tab键不能一起用):
network:
ethernets:
ens33:
dhcp4: no
dhcp6: no
addresses: [192.168.75.111/24]
gateway4: 192.168.75.2
nameservers:
addresses: [114.114.114.114,8.8.8.8]
version: 2
renderer: NetworkManager
其中gateway4就是上文说的的网关即192.168.75.2
addresses是linux虚拟机即节点的IP地址,也就是文章开头图中的(需要三个节点):

前三位与网关一样,最后一位自己分配,即192.168.75.x,为了防止冲突,这里的x不能是2,1(192.168.75.1是宿主机的VMnet8这个虚拟网络的IP地址),最好不要是0。我分配的是192.168.75.111,另外两个节点(slave1 slave2)是192.168.75.112和192.168.75.113(这两个节点可以先不分配,先配置完master的部分环境,再克隆两个即可,注意,克隆的两个虚拟机只需要改addresses即可)。
Node1(后边改名为master):

改完之后一定要保存设置!!!
即一定要执行(sudo)netplan apply(普通用户要加sudo)命令可以让配置直接生效
sudo netplan apply如果回车之后什么都没提示说明,配置成功,否则失败,需要检查上方的操作(缩进,漏输入,多输入)
6.执行 reboot 命令重启系统(非必须)。
7.用 ping 命令验证网络是否通达(其实打开浏览器搜索试一下也可以):
ping -c 4 baidu.com下图为正常情况

二、关闭防火墙(可以防止后续ssh登录出现问题)
在root用户下,输入以下命令即可关闭防火墙(同样地,根据命令字面意思,打开防火墙也就会了吧):
ufw disable三、为了方便,修改host用户名(安装虚拟机的时候就直接起对名字就好了)
即把Node改为master,Node2改为slave1,Node3改为slave2。(一个主节点,两个从节点)
图形界面(很简单):
打开Ubuntu设置->共享,然后修改即可

重启才能真正生效!!!
命令行界面(图形界面也可以用):
ubuntu 18.04不能直接修改/etc/hostname中主机名称,重启后又恢复到安装时设置的主机名称.
正确的修改步骤如下:
修改主机名(永久),root用户不用加sudo
sudo vi /etc/hostname 然后改为需要的主机名后保存
保存后重启
sudo reboot如果是root模式,不用加sudo
四、配置主机名与ip映射:
sudo vi /etc/hosts 插入下列内容
192.168.75.xxx(这里是你的ip地址,上一步设置过了) 主机名
以master为例,应该是
192.168.75.111 master完整的如下图:

ip地址每个人都不一样,用你自己配的!
如果没记住,可以使用以下命令查看(记住请略过)
ifconfig如果发生以下错误,说明你没有安装net相关组件,直接复制它的提示

根据提示,使用命令安装net相关组件
sudo apt install net-tools如果出现以下报错:

那么先执行sudo apt-get update,再sudo apt install net-tools
sudo apt-get update再次使用ifconfig,可以查看自己的ip地址:

五、配置Java jdk1.8
1.在宿主机下载jdk1.8然后通过共享文件夹传到虚拟机
设置共享文件夹:
(30条消息) 大数据开源框架环境配置(三)——打开Ubuntu虚拟机,设置root密码,安装VMware Tools,设置共享文件夹_木子一个Lee的博客-CSDN博客

2.可以通过图形界面进入共享文件夹目录然后右键在终端打开:

也可以在终端使用cd /mnt/hgfs/share进入(我的共享文件夹目录是/mnt/hgfs/share,以自己的为准,/mnt/hgfs/是一样的,第三级每个人不同)
提前复制好压缩包的名字,我的是jdk-8u311-linux-x64.tar.gz

3.使用命令进行解压,使用命令tar -zxf 刚才复制的名字 -C /usr/local(我选择将jdk安装至 /usr/local/ 中为例,也可以装在其他地方)
sudo tar -zxvf ./jdk-8u311-linux-x64.tar.gz -C /usr/local或
sudo tar -zxf ./jdk-8u311-linux-x64.tar.gz -C /usr/local注意:每个人下载的jdk1.8版本可能不一样,也就是压缩包名字可能不一样
4.配置环境变量
为了方便,先修改文件名:
进入/usr/local
cd /usr/local执行:
mv jdk1.8.0_311 jdk将原文件夹名改为jdk
然后设置环境变量(需要在root用户下):
关于环境变量的相关问题,请看:
(30条消息) 解决配置了/etc/profile/下环境路径刷新后,重新打开或切换用户失效的问题_木子一个Lee的博客-CSDN博客
(30条消息) Linux(Ubuntu)配置不同用户的环境变量_木子一个Lee的博客-CSDN博客_linux不同用户的环境变量 (30条消息) ubuntu配置环境变量的方法_ubuntu设置环境变量_木子一个Lee的博客-CSDN博客
(30条消息) ubuntu中环境变量文件/etc/profile、.profile、.bashrc、/etc/bash.bashrc之间的区别和联系_木子一个Lee的博客-CSDN博客_ubuntu 环境变量文件
cdvi /etc/profile或
vim /etc/profile或
gedit /etc/profile(仅限于图形界面)在最后加入环境变量(直接复制过去会有乱码,仔细检查一下):
以下路径(/usr/local/jdk)是以我自己的为准
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
或:
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
5.刷新环境变量:(一定要做)
source /etc/profile6.测试java命令是否可用:
java -version如果提示Command ‘java’ not found…..,说明环境变量配置错误,需要检查一下
出现以下内容说明成功了:

六、安装配置hadoop
1.在宿主机下载hadoop然后通过共享文件夹传到虚拟机

2.可以通过图形界面进入共享文件夹目录然后右键在终端打开:

也可以在终端使用cd /mnt/hgfs/share进入

提前复制好压缩包的名字,每个人可能不一样,我的是hadoop-3.1.3.tar.gz

3.然后使用命令sudo tar -zxf 刚才复制的名字 -C /usr/local(我选择将 Hadoop 安装至 /usr/local/ 中为例,也可以装在其他地方)
如果是root用户下,不需要加sudo(下同)
即
sudo tar -zxvf ./hadoop-3.1.3.tar.gz -C /usr/local或
sudo tar -zxf ./hadoop-3.1.3.tar.gz -C /usr/local注意:每个人下载的hadoop版本可能不一样,也就是压缩包名字可能不一样
4. 进入/usr/local/进行操作:
cd /usr/local/将文件夹名改为hadoop
sudo mv ./hadoop-3.1.3/ ./hadoop5. Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息(不查看也行,配置完环境变量查看即可):
cd /usr/local/hadoop./bin/hadoop version以上两条命令可以用一条代替:
/usr/local/hadoop/bin/hadoop version
6.配置环境变量(root模式下)
vi /etc/profile或
vim /etc/profile或
gedit /etc/profile(仅限于图形界面)添加(同样,路径/usr/local/hadoop也是每个人都不一样的,即安装目录):
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH保存退出后刷新环境变量!
source /etc/profile这时候就可以直接用hadoop version(不需要找到指定目录)查看Hadoop版本了,验证是否配置成功
七、 安装配置ssh,配置root用户ssh登录
1.SSH介绍
ssh为 Secure Shell 的缩写,由 IETF 的网络小组(Network Working Group)所制定;SSH 为建立在应用层基础上的安全协议。SSH 是较可靠,专为远程登录会话和其他网络服务提供安全性的协议。首先查看系统是否启动了SSH进程
在root模式下,
安装ssh服务:
apt install openssh-server安装完成后启动SSH进程:
service ssh start2.配置root用户ssh登录:
默认情况下Ubuntu不允许使用root用户进行SSH登录,需对配置文件/etc/ssh/sshd_config进行如下修改:(也可以在root用户下进行,不用输入sudo)
sudo vi /etc/ssh/sshd_config或
sudo vim /etc/ssh/sshd_config或(仅限于图形界面)
sudo gedit /etc/ssh/sshd_config将配置项PermitRootLogin 设为yes
可以直接把PermitRootLogin prohibit-passwd前面的#去掉,然后改成
PermitRootLogin yes也可以跟下图一样,直接添加

然后重启ssh服务(一定要做!):
service ssh restart
八、克隆两个虚拟机
克隆操作:
保证虚拟机在关机状态,点击虚拟机:

然后选择管理->克隆,点击下一步:

默认:

选择完整克隆,下一步:

修改名字和位置(最好不要在C盘),完成:

克隆后的两个虚拟机(salve1、slave2)
开机后,用ifconfig看看IP地址,发现跟master一样,需要重新改一下ip地址。
跟步骤一一样,在网络配置文件里修改ip地址即可
slave1:

slave2:

也要记得保存设置:
sudo netplan apply发现jdk也已经搞好了
java -version查看VMware Tools,发现也装好了
Root密码也是一样的
防火墙状态也是一样的
Hadoop也安装好了
修改完ip之后,在mobaxterm里边远程登录,发现是可以的
mobaxterm请看:
(30条消息) 使用MobaXterm进行远程登录_木子一个Lee的博客-CSDN博客
用户名(master是lee,slaves也是lee)也是一样的,可以选择改,不改也没关系
如果你在克隆之前做了不同主机之间的ssh免密登录(一般放在下一步做),那么克隆之后是不行的,要重新配置
所以最好克隆之后再配置不同主机之间的ssh免密登录
九、本机以及不同主机之间的ssh免密登录
如果不想看1 2 3啰嗦就直接往下翻,看4.总结
1.先说一下原理:
假如有两台(或多台)同局域网的服务器A:192.168.75.111,B:192.168.75.113。让A,B这两台服务器之间能两两互相免密登录,并且每台服务器都可以自我免密登录(自我免密登录即:ssh localhost 时不需要密码)。
免密登录需要授权,假设把A公钥id_rsa.pub交给B授权,那么A就可以免密登录B,如果A的公钥id_rsa.pub给了自己,那么A就可以免密登录自己。
2.自身免密的步骤,以A主机(假设登录名为name,相当于master的lee)为例:
首先生成公钥、私钥:ssh-keygen -t rsa,然后一直回车;
然后查看A主机生成密钥文件,默认在用户目录中的.ssh文件夹内(在普通用户下生成的公钥,密钥文件只在普通用户的.ssh文件里,root用户里的没有,而且连.ssh文件夹都没有(只有生成密钥,才会创建.ssh文件夹),反之也是如此):
普通用户:/home/name/.ssh/ name是登录名,如果换成master节点,我的master的登录名是lee,所以位置在/home/lee/.ssh/
对于root用户,位于/root/.ssh下
其中:id_rsa为私钥文件,id_rsa.pub为公钥文件
如下图所示

然后对于普通用户,查看/home/name/.ssh/有没有管理密码登录权限的authorized_keys文件
如果按照我的master节点,就是/home/lee/.ssh
命令依次为:
cd /home/name/.ssh/ls对于root用户,查看/root/.ssh有没有authorized_keys文件
cd /root/.ssh/ls若有,直接执行
cat id_rsa.pub >> authorized_keys若没有,则先创建“authorized_keys”文件,并修改权限为“600”:
touch authorized_keyschmod 600 authorized_keys然后执行
cat id_rsa.pub >> authorized_keys最后测试一下自身免密登录:
ssh localhost如果出现:

则修改/etc/ssh/ssh_config文件中的配置(sudo vi /etc/ssh/ssh_config 或sudo vim /etc/ssh/ssh_config或sudo gedit /etc/ssh/ssh_config,root用户不需要加sudo),添加如下两行配置:
StrictHostKeyChecking no
UserKnownHostsFile /dev/null注:普通用户和root用户的免密登录配置是独立的,也就是说,如果以上操作都是在普通用户下进行的,那么root用户下就不能免密登录(得需要免密),反之也是这样。如果两种用户都要免密,那么就要还需在root模式下执行以上操作
3.主机之间免密登录(假设A:192.168.75.111,B:192.168.75.113。A登录名为lee,host名为Node1;B登录名为lee,host名为Node3)
首先,A生成密钥:
ssh-keygen -t rsa然后一直回车;
然后查看A主机生成密钥文件,默认在用户目录中的.ssh文件夹内(在普通用户下生成的公钥,密钥文件只在普通用户的.ssh文件里,root用户里的没有,反之也是如此):
普通用户:/home/lee/.ssh/ (cd /home/lee/.ssh/回车,ls,回车)
对于root用户,位于/root/.ssh下(cd /root/.ssh/,回车,ls,回车)
其中:id_rsa为私钥文件,id_rsa.pub为公钥文件
接下来,即把A生成的公钥给B的管理密码登录权限的authorized_keys文件(才能实现A免密登录B)。这就意味着B也要生成密钥(authorized_keys在.ssh文件夹里。只有生成密钥,才会创建.ssh文件夹)。
打开B的终端,生成密钥(ssh-keygen -t rsa),查看有无authorized_keys文件(一般没有),创建authorized_keys文件并修改权限为“600”(touch authorized_keys
chmod 600 authorized_keys),即跟上边的操作一样。
然后很关键的一步:把A的公钥追加到B的authorized_keys文件里
打开A的终端,
普通用户:进入/home/lee/.ssh/ (cd /home/lee/.ssh/,回车)
Root 用户:进入/root/.ssh(cd /root/.ssh/,回车)
利用scp命令把A的公钥发到B的tmp(可以自己选一个)文件夹下:
执行(192.168.75.113为B的IP地址):
scp id_rsa.pub 192.168.75.113:/tmp打开B的终端,把A的公钥id_rsa.pub复制到B的.ssh文件夹下(普通用户在/home/lee/.ssh/,root用户在/root/.ssh)
普通用户执行:
cat /tmp/id_rsa.pub>>/home/lee/.ssh/authorized_keys或
cp /tmp/id_rsa.pub /home/lee/.ssh/authorized_keysroot用户执行:
cat /tmp/id_rsa.pub>>/root/.ssh/authorized_keys或
cp /tmp/id_rsa.pub /root/.ssh/authorized_keys最后测试一下,成功:(可以有4种测试方法:ssh ip地址、ssh 登录名@IP地址、ssh 登录名@host名、ssh host名):
ssh 192.168.75.113相当于(因为在前面已经做过地址与host名的映射了)
ssh Node1
注:普通用户和root用户的免密登录配置是独立的,也就是说,如果以上操作都是在普通用户下进行的,那么root用户下就不能免密登录(得需要免密),反之也是这样。如果两种用户都要免密,那么就要还需在root模式下执行以上操作。
同样实现B对A的免密登录,也是同上
4.总结(master,salve1,slave2本机的ssh免密登录以及相互之间的免密登录,登录名均为lee)
自身免密登录:
首先生成公钥、私钥(三个节点都要这样做):
ssh-keygen -t rsa然后一直回车;
然后创建“authorized_keys”文件,并修改权限为“600”:
touch authorized_keyschmod 600 authorized_keys然后执行
cat id_rsa.pub >> authorized_keys最后测试一下自身免密登录:
ssh localhost如果出现:
则修改/etc/ssh/ssh_config文件中的配置(sudo vi /etc/ssh/ssh_config 或sudo vim /etc/ssh/ssh_config或sudo gedit /etc/ssh/ssh_config,root用户不需要加sudo),添加如下两行配置:
StrictHostKeyChecking no
UserKnownHostsFile /dev/null不同主机之间的免密登录 :
将master的公钥发送到slave1:
scp id_rsa.pub 192.168.75.112:/tmp打开slave1的终端,把master的公钥id_rsa.pub复制到slave1的.ssh文件夹下(普通用户在/home/lee/.ssh/,root用户在/root/.ssh)
普通用户执行:
cat /tmp/id_rsa.pub>>/home/lee/.ssh/authorized_keys或
cp /tmp/id_rsa.pub /home/lee/.ssh/authorized_keysroot用户执行:
cat /tmp/id_rsa.pub>>/root/.ssh/authorized_keys或
cp /tmp/id_rsa.pub /root/.ssh/authorized_keys最后测试一下(可以有4种测试方法:ssh ip地址、ssh 登录名@IP地址、ssh 登录名@host名、ssh host名)
同样地,重复上方操作,注意ip地址的改变
master还要发给slave2,
slave1要发给master和slave2,
slave2要发给master和slave1
十、最终配置与调试
1.修改配置文件
先找到目录:
cd /usr/local/hadoop/etc/hadoop(0) 修改hadoop-env.sh
vim hadoop-env.sh添加java路径:
export JAVA_HOME=/usr/local/jdk
(1)修改文件workers
需要把所有数据节点的主机名写入该文件,每行一个,默认为 localhost(即把本机作为数据节点),所以,在伪分布式配置时,就采用了这种默认的配置,使得节点既作为名称节点也作为数据节点。在进行分布式配置时,可以保留localhost,让Master节点同时充当名称节点和数据节点,或者也可以删掉localhost这行,让Master节点仅作为名称节点使用。
vim workers本教程master节点仅作为名称节点使用,因此将workers文件中原来的localhost删除,只添加如下内容:
slave1
slave2(2)修改文件core-site.xml
vim core-site.xml或更方便的:
gedit core-site.xml把core-site.xml文件修改为如下内容:
<configuration>
<!--指定namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!--用来指定使用hadoop时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<!--用来设置检查点备份日志的最长时间-->
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
</property>
</configuration>(3)修改文件hdfs-site.xml(gedit命令更方便)
vim hdfs-site.xml对于Hadoop的分布式文件系统HDFS而言,一般都是采用冗余存储,冗余因子通常为3,也就是说,一份数据保存三份副本。但是,本教程有2个slave节点作为数据节点,即集群中有2个数据节点,数据能保存2份,所以 ,dfs.replication的值设置为 2。hdfs-site.xml具体内容如下:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<!--指定hdfs保存数据的副本数量-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--指定hdfs中namenode的存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<!--指定hdfs中datanode的存储位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>(4)修改文件mapred-site.xml(gedit命令更方便)
“/usr/local/hadoop/etc/hadoop”目录下有一个mapred-site.xml.template,需要修改文件名称,把它重命名为mapred-site.xml,(命令:mv mapred-site.xml.template mapred-site.xml)(也可能不需要重命名)
vim mapred-site.xml然后,把mapred-site.xml文件配置成如下内容:
<configuration>
<!-- 指定MR运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
</configuration>(5)修改文件 yarn-site.xml(gedit命令更方便)
vim yarn-site.xml把yarn-site.xml文件配置成如下内容:
<configuration>
<!--指定Yarn的ResourceManager地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!--指定Yarn的NodeManager获取数据的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--Yarn打印工作日志-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>2.将配置好的Hadoop分发到其他主机
上述5个文件全部配置完成以后,需要把master节点上的“/usr/local/hadoop”文件夹复制到各个节点上:
scp -r /usr/local/hadoop root@slave1:/usr/local/scp -r /usr/local/hadoop root@slave2:/usr/local/3.格式化namenode
hdfs namenode -format4.启动hadoop
先启动HDFS:
start-dfs.sh再启动YARN:
start-yarn.sh启动后可以在Web页面查看hadoop信息:
http://mini1:50070为了防止start-dfs.sh后报错:
在/usr/local/hadoop/sbin路径下
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root以下警告可以忽略(也可能没有警告):

5.浏览器web测试
输入文章来源:https://www.toymoban.com/news/detail-742669.html
master:9870 文章来源地址https://www.toymoban.com/news/detail-742669.html
文章来源地址https://www.toymoban.com/news/detail-742669.html
到了这里,关于大数据开源框架环境搭建(四)——HDFS完全分布式集群的安装部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!