参考:
https://github.com/TabbyML/tabby
Docker | Tabby
Linux Debian上快速安装Docker并运行_Entropy-Go的博客-CSDN博客
Tabby - 本地化AI代码自动补全 - Windows10_Entropy-Go的博客-CSDN博客
1.为什么选择Tabby
已经有好几款类似强劲的代码补全工具,如GitHub Copilot,Codeium等,为什么还要选择Tabby?
Tabby除了和其他工具一样支持联网直接使用之外,还支持本地化部署。
即对内部代码安全性要求很高时,可以采取Tabby项目模型的本地化部署,不用担心本地项目代码隐私泄露,同时有很好的享受GitHub代码库的建议。
部署完成后,如简单粗暴断开外部网络,甚至拔掉网线,依然可以使用。
可以单机使用,也可以公司内部网、局域网内共同使用。

2.决定动手之前,试一试
Playground | Tabby

3.Linux Debian 上直接部署Tabby
前面已经在windows上部署成功,也可以直接在Linux上安装部署
4.Linux Debian上快速安装Docker
Linux Debian上快速安装Docker并运行_Entropy-Go的博客-CSDN博客
5.Git Clone tabby项目代码到本地
git clone https://github.com/TabbyML/tabby.git6.Docker Run下载镜像
Docker | Tabby

本文选择了CPU,打开终端,在clone下来的tabby根目录下,执行下面的命令
CPU
docker run \
-p 8080:8080 -v $HOME/.tabby:/data \
tabbyml/tabby serve --model TabbyML/SantaCoder-1B7.部署成功
$ sudo docker run -p 8080:8080 -v $HOME/.tabby:/data tabbyml/tabby serve --model TabbyML/SantaCoder-1B
2023-07-20T01:57:48.901861Z INFO tabby::serve: crates/tabby/src/serve/mod.rs:131: Listening at 0.0.0.0:8080
检查是否部署成功
浏览器本地访问 http://localhost:8080/

或者在局域网络中使用 http://PC_IP:8080/

8.下载并安装VS Code(Visual Studio Code)
Download Visual Studio Code - Mac, Linux, Windows
安装完成后,打开VS Code,扩展中搜索Tabby并安装

Tabby的管理里面设置上面本地部署的Tabby服务

 VS Code右下角显示Tabby已经可以提供服务
VS Code右下角显示Tabby已经可以提供服务

9.开始高效编码吧
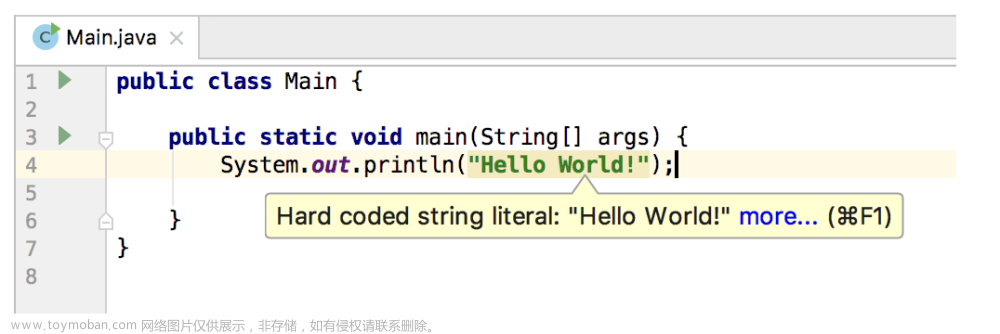
输入注释或者编码时,会自动补全,即灰色斜体部分,如果接收就直接按Tab键,采纳建议,否则正常进行编码


按Tab键接收建议,灰色部分变亮

编码时调用默认tabby并提示补全时,服务器资源消耗大,可以通过top命令查看,可以考虑高性能设备或者GPU加速

10.并行多核CPU处理,加快推理响应
卡顿还有个原因,虽然服务器性能不错,但是tabby默认最多使用4个CPU进行并行模型推理,所以可以尝试增加并行的核数
默认调用4核CPU

可以增加更多核并行处理,
如服务器有16核添加参数,16/4=4, --num-replicas-per-device 4
如服务器有32核添加参数,32/4=8, --num-replicas-per-device 8
$ sudo docker run -p 8080:8080 -v $HOME/.tabby:/data tabbyml/tabby serve --model TabbyML/SantaCoder-1B --num-replicas-per-device 8现在可以按照要求调用更多核CPU,VS Code中输入过程中,提示的更快。

11.CentOS环境安装并运行tabby
同样的,可以在CentOS上安装Docker,可参考
Linux CentOS上快速安装Docker并运行服务_Entropy-Go的博客-CSDN博客
本地服务器有32核,所以添加参数,32/4=8, --num-replicas-per-device 8
$ sudo docker run -p 8080:8080 -v $HOME/.tabby:/data tabbyml/tabby serve --model TabbyML/SantaCoder-1B --num-replicas-per-device 8
2023-07-27T06:56:19.280691Z INFO tabby::serve: crates/tabby/src/serve/mod.rs:131: Listening at 0.0.0.0:8080运行截图:
在vscode中正常编码或者写代码注释时,触发tabby进行多核并行模型推理

按Tab键接受自动补全的代码

同时可以观察到服务器上CPU内存等资源使用情况,触发模型推理时使用率特别高!

12.CentOS扩展Nvidia GPU运行tabby
CentOS扩展Nvidia GPU之后,推理速度超级快,边写边推荐源码,体验非常的丝滑,可以大大提高编码效率。
首先需要安装GPU,驱动,CUDA工具包和Nvidia Docker工具包,也可参考之前写的:
安装GPU,驱动,CUDA工具包
在线安装:
NVIDIA GPU驱动和CUDA工具包 Linux CentOS 7 在线安装指南_Entropy-Go的博客-CSDN博客
下载安装:
Linux CentOS安装NVIDIA GPU驱动程序和NVIDIA CUDA工具包_centos 安装nvcc_Entropy-Go的博客-CSDN博客
安装Nvidia Docker工具包:
centOS 快速安装和配置 NVIDIA docker Container Toolkit_Entropy-Go的博客-CSDN博客
GPU方式运行tabby:
[ xxx ]# docker run -it --gpus all -p 8080:8080 -v $HOME/.tabby:/data tabbyml/tabby serve --model TabbyML/SantaCoder-1B --device cuda
2023-08-17T11:00:25.128496Z INFO tabby_download: crates/tabby-download/src/lib.rs:66: Start downloading model `TabbyML/SantaCoder-1B`
2023-08-17T11:00:31.338937Z INFO tabby::serve: crates/tabby/src/serve/mod.rs:134: Listening at 0.0.0.0:8080
查看GPU使用情况:
[ xxx ]# nvidia-smi
Thu Aug 17 07:43:33 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.86.10 Driver Version: 535.86.10 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:31:00.0 Off | 0 |
| N/A 33C P0 30W / 250W | 4908MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 60875 C /opt/tabby/bin/tabby 4906MiB |
+---------------------------------------------------------------------------------------+
举个栗子:
可以使用中文输入提示词,如
# 设计1个贪吃蛇游戏文章来源:https://www.toymoban.com/news/detail-742730.html
 文章来源地址https://www.toymoban.com/news/detail-742730.html
文章来源地址https://www.toymoban.com/news/detail-742730.html
到了这里,关于基于GitHub代码库训练模型本地化AI代码自动补全 - Tabby Linux Debian/CentOS的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!