一、GUI自动化基础
1、基础概念
1.GUI自动化也就是模拟人的操作来完成基础的功能测试。
2.GUI自动化测试中,需要明白测试脚本和数据的解耦。即实现数据驱动的测试,让操作相同但是数据不同的测试通过一套脚本来实现。
3.在写脚本中要注意“页面对象模型” 的核心理念:以页面为单位来封装页面上的控件以及控件的部分操作。测试用例使用页面对象来完成具体的界面操作。
2、测试数据
创建测试数据的方法:
- API调用(即调用功能接口创建数据)
- 数据库操作
- 综合运用API调用和数据库操作
1.对于相对稳定,很少有修改的数据,可以预先创建数据。
2.对于一次性使用的,经常要改的,状态经常变化的数据,可以在测试中实时创建数据。
3、GUI测试不稳定的因素
- 非预计的弹窗,如杀毒检测弹窗等-----对弹窗进行检测,然后实现关闭弹窗的操作
- 页面控件属性的变化----------采用组合属性定位控件,和模糊匹配技术提高定位识别率
- 被测系统的A/B测试(即一个系统的两套环境测试,如测试环境和线上环境)------脚本区分A/B系统
- 随机的页面延迟造成控件识别失败----------实行重试机制
- 测试数据问题
二、selenium介绍
selenium是一个web自动化测试工具,可以直接调用浏览器,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器),可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏等。我们可以使用selenium很容易完成之前编写的爬虫。
pip install selenium 安装selenium
pip show selenium 查看包版本
pip uninstall selenium卸载包
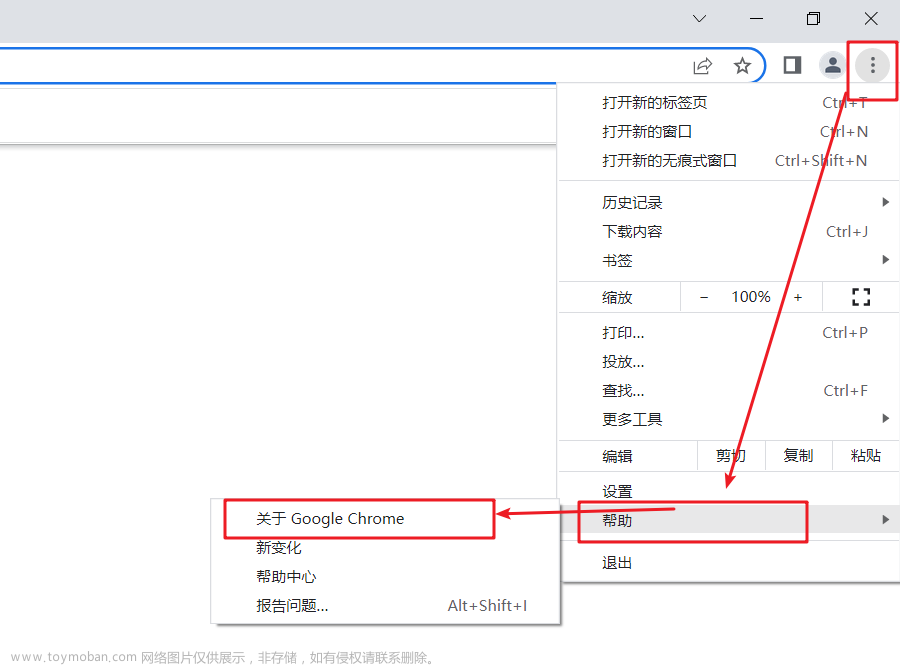
谷歌驱动版本下载路径(根据自己的浏览器版本适配):https://registry.npmmirror.com/binary.html?path=chromedriver/
1、工作原理
利用浏览器原生的API,封装成一套更加面向对象的selenium webdriver API,直接操作浏览器页面里的元素,甚至操作浏览器本身(截图,窗口大小,启动,关闭等)

- webdriver本质是一个web-server ,对外提供webapi,其中封装了浏览器的各种功能
- 不同的浏览器使用各自不同的webdriver(浏览器驱动)
2、无头浏览器与有头浏览器的使用场景
- 开发过程中需要查看运行过程中的各种情况,所以通常使用有头浏览器
- 在项目完成部署的时候,平台通常用的系统都是服务器版的操作系统,服务器版的操作系统必须使用无头浏览器才能正常运行。
2.1无头浏览器的创建
selenium控制谷歌浏览器也存在无界面模式。
开启无界面模式的方法:
1.实例化配置对象:opt=webdriver.ChromeOptions()
2.配置对象添加开启无界面模式的命令:opt.add_argument(‘–headless’)
3.配置对象添加禁用gpu的命令
opt.add_argument(‘–disable-gpu’)
4.实例化带有配置对象的driver对象driver=webdriver.Chrome(chrome_options=opt)
driver.get(url)
#coding:utf-8
from time import sleep
from selenium import webdriver
url='https://www.baidu.com'
#创建配置对象
opt=webdriver.ChromeOptions()
#添加配置参数
opt.add_argument('--headless')
opt.add_argument('--disable-gpu')
#创建浏览器对象的时候添加配置对象
driver=webdriver.Chrome(chrome_options=opt)
driver.get(url)
driver.save_screenshot('baidu.jpg')
2.2 selenium使用代理ip
1.实例化配置对象:opt=webdriver.ChromeOptions()
2.配置对象添加使用代理ip的命令
opt.add_argument(‘–proxy-server=http://202.20.13.12:9090’)
#更换ip代理,必须重启浏览器
3.实例化带有配置对象的driver对象:
driver=webdriver.Chrome(‘./chromedriver’,chrome_options=opt)
2.3 selenium替换user-agent
替换user-agent的方法:
1.实例化配置对象:opt=webdriver.ChromeOptions()
2.配置对象添加替换UA的命令:
opt.add_argument(‘–user-agent=Mozilla/5.0 HAHAHA’)
3.实例化带有配置对象的driver对象:
driver=webdriver.Chrome(‘./chromedriver’,chrome_options=opt)
3、定位路径
定位路径:绝对路径和相对路径
相对路径:
1.以//开始,目标元素所在的标签名开始 。
2.找到目标元素,右击->copy->xpath即可。
3. *通配符,//*匹配标签名;//*[@id=’ ']表示匹配属性名 。
4. 使用索引,注意层级关系。
绝对路径:/html/xxx/xx
4、8种定位元素方式
定位方式:8种:id,name,class_name,tag_name,link_text,partial_link_text,xpath,css
定位元素时,优先按id,name,classname定位;当只有确定该元素的标签为页面唯一时,可用tag_name定位,以上几种方式都无法定位时,可以采用css,xpath定位。
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get(“http://www.baidu.com”)
time.sleep(5)
#输入想要搜索的值
#driver.find_element_by_id(“kw”).send_keys(“你好呀”) #通过id查找
#driver.find_element_by_name(“wd”).send_keys(“hello”) #通过name查找
#driver.find_element_by_class_name(“s_ipt”).send_keys(“hello”) #通过class查找
#driver.find_element_by_link_text(“登录”).click() #通过超链接查找
#driver.find_element_by_partial_link_text(“About”).click() #通过超链接的部分关键字查找
#当获取的是多个值时,方法记得用复数形式:find_elements_by
listinput=driver.find_elements_by_tag_name(“input”) #通过标签查找
for resultlist in listinput:
if resultlist.get_attribute(“type”)==“text”:
resultlist.send_keys(“圣诞快乐”)
#点击“百度一下”按钮
driver.find_element_by_id(“su”).click()
time.sleep(3)
#driver.find_element_by_xpath(“//*[@id=‘1’]/h3/a[1]/em”).click() #通过xpath查找
#time.sleep(5)
driver.quit()
注意:
1.当页面元素有id属性的是有优先使用id来定位
2.cssSelector执行速度快,推荐使用
3.定位超链接用linkText或partialLinkText,注意超链接文本经常发生改变,所以不推荐使用
4.xpath功能最强悍,但是执行速度慢:需要查找整个DOM,尽量少用
5、切换
5.1 切换frame
注意是否有多个frame嵌套使用!!!
嵌套的frame元素定位也是一样,一层一层套即可。要注意看frame之间的关系,若是同一层级的,要先跳出当前frame到上一个parent_frame,然后再切换到要操作的frame中即可。
例:
原html代码:
<frame src="" id="index_main" name="main" scrolling="Yes" noresize="noresize">
<iframe id="Editor1" src="" frameborder="0" scrolling="no" >
<iframe id="eWebEditor" width="100%" height="100%" scrolling="yes" frameborder="0" src="">
<input type="text" id="TeacherTxt" name="Teacher" size="12" maxlength="12" >
</iframe>
</iframe>
</iframe>
定位代码:
chrome .switchTo().frame( "index_main" );
chrome .switchTo().frame( "Editor1" );
chrome .switchTo().frame( "eWebEditor" );
chrome.findElement(By.id(" TeacherTxt ")).sendKeys("测试Iframe");
chrome.switchTo().defaultContent();
注意;最后只需要退出一次,直接到主界面即可。
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get(“https://music.163.com/#/discover/toplist?id=19723756”)
time.sleep(5)
#/ 错误演示 注意:在html中嵌套多个frame时直接定位是不行的
t=driver.find_element_by_id(“song-list-pre-cache”)
正确演示:
确认系统中是否用到frame/iframe
1.F12中确认 :目标元素网上找iframe/frame
2.页面观察,有框的地方,下拉的时候很有可能有frame
driver.switch_to.frame(“g_iframe”)
#id也可以替换成name,其他定位语句
driver.switch_to.frame(“contentFrame”)
t=driver.find_element_by_id(“song-list-pre-cache”)
print(t.text)
#跳出frame层
driver.switch_to.frame()
#跳转到父层
driver.switch_to.parent_frame()
#跳转到最开始的 ,主层
driver.switch_to.default_content()
driver.switch_to.default_content()
driver.find_element_by_link_text(“歌单”).click()
time.sleep(10)
driver.quit()
5.2切换浏览器窗口
获取整个浏览器窗口,并跳转到对应窗口
for handle in wd.window_handles:
wd.switch_to.window(handle)
if 'Bing' in wd.title:
#判断如果是要操作的窗口,那就跳出循环
break
mainwindow=wd.current_window_handles #获取当前窗口句柄
6、选择框操作
6.1 radio选择框
获取当前选中的元素:
element=wd.find_element_by_css_selector(‘#s_radio input[checked=checked]’)
print('当前选中的是; '+element.get_attribute(‘value’))
#点选茄子按钮
wd.find_element_by_css_selector(‘#s_radio input[value=‘茄子’]’).click()
6.2 checkbox选择框
elements=wd.find_elements_by_css_selector(‘#s_radio input[checked=checked]’)
for element in elements:
element.click()
6.3 select 多选框
对于select多选框,要选中某几个选项,要注意先去掉原来已经选中的选项。
所有option标签对象都存在select.options里,是个列表。
方法:
1.select_by_index() #根据option索引定位,从0开始
2.select_by_value() #根据option属性value值定位
3.select_by_visible_test() #根据option显示文本来定位
from selenium.webdriver.support.ui import Select
创建Select对象
select=Select(wd.find_element_by_id('ss_multi'))
清除所有已选中的选项
select.deselect_all()
选择某几个选项
select.select_by_visible_text('小雷')
select.select_by_visible_text('小红')
#循环选择列表中的每一个值
for option in select.options:
option.click()
time.sleep(2)
7、cookie的处理
selenium可以帮助处理页面的cookie,比如获取、删除。
- 获取:driver.get_cookies()返回的是列表,其中包含的是完整的cookies信息,如:name,value,path等。如果想把获取的cookie信息和requests模块配合使用,需要转换为name,value作为键值对的cookie字典。
- 删除:driver.delete_cookie(‘cookiename’)删除一条cookie;driver.delete_all_cookies()删除所有的cookies
#coding:utf-8
from selenium import webdriver
driver=webdriver.Chrome()
driver.get("https://www.runoob.com/redis/redis-install.html")
# #获取cookies
cookies=driver.get_cookies()
print(cookies)
print('----------------------------------------------------------')
driver.delete_cookie('__gpi')
dict={cookie['name']:cookie['value'] for cookie in cookies}
print(dict)
#一定要退出!不退出会有残留进程。
driver.quit()
给一个网页添加cookies值:
import time
from selenium import webdriver
driver=webdriver.Chrome()
driver.get("http://vip.ytesting.com/loginController.do?login2")
#给网页添加cookies
driver.add_cookie({"name":"sessionid","value":"adadsd"})
time.sleep(2)
driver.refresh()
print(driver.get_cookies())
8、执行js
scrollTo(0,0) 滚动到顶部
scrollTo(0,1000) 滚动到最底层
#coding:utf-8
from time import sleep
from selenium import webdriver
driver=webdriver.Chrome()
driver.implicitly_wait(5)
driver.get("https://www.json.cn/")
#通过js代码模拟拖动下滑页面
js='scrollTo(0,500)'
driver.execute_script(js)
sleep(3)
driver.find_element_by_xpath('/html/body/footer/div/div/div[2]/dd[1]/a').click()
9、三种等待方式
在使用定位元素之间,需要设置一个等待时间,否则会出现前一个元素还未定位到,后面的代码找不到元素。
等待一共有以下三种方式:
9.1 强制等待
time.sleep()
print("等待前的时间:",datetime.now())
time.sleep(5)
print("等待后的时间:",datetime.now())
9.2 隐式等待
当没有找到元素的时候,不立即返回找不到元素的错误,而是周期性(每隔0.5s)重新寻找该元素,直到元素找到,或超出指定最大等待时长,这时候才抛出异常(如果是find_elements之类的方法,则返回空列表)。
webdriver对象的implicity_wait方法(隐式等待):接受一个参数,用来指定最大等待时长。
wd=webdriver.Chrome()
wd.implicitly_wait(10) #添加该代码,后续所有的find_element或者find_elements之类的方法调用都会采用上面的策略,即找不到元素会循环查找,直到找到元素,或超过最大时长为止。
9.3 显式等待
WebDriverWait(driver,10,1).until(ec.presence_of_all_elements_located())
until 代表一直等待直到某个元素出现
until not 直到某个元素消失
参数20表示最长等待20s;1表示每1s检查一次标签是否存在;
ec.presence_of_all_elements_located(By.id,''kw")表示通过id定位标签。
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
located=(By.ID,"kw")
element=WebDriverWait(driver,10,1).until(ec.presence_of_all_elements_located(located))
10、控件操作
10.1 鼠标
ActionChains类提供了一些特殊的动作的模拟,实际的方法可以通过ActionChains类的代码查看。
例如:使用ActionChains来模拟鼠标移动
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
wd=webdriver.Chrome()
wd.implicitly_wait(5)
wd.get('https://www.baidu.com')
ac=ActionChains(wd)
#鼠标移动到元素上
ac.move_to_element(
wd.find_element_by_css_selector('[name="tj"]')
).perform()
双击鼠标:double_click()
action=ActionChains(driver)
attr_a=driver.find_element_by_xpath('/html/body/footer/div/div/div[2]/dd[1]/a')
action.double_click(attr_a).perform()
鼠标拖动:drag_and_drop()
#从起始地拖至目的地
source=driver.find_element_by_id("nc_1__bg")
dst=driver.find_element_by_id("nc_1__helpbtn")
time.sleep(3)
ActionChains(driver).drag_and_drop(source,dst).perform()
鼠标悬停:move_to_element()
more=driver.find_element_by_xpath("/html/body/div[1]/div[1]/div[3]/div/a")
time.sleep(3)
ActionChains(driver).move_to_element(more).perform()
鼠标滑动到指定元素:
target2=browser.find_element_by_css_selector("body > div:nth-child(8) > div > div.ant-modal-wrap.ant-modal-centered > div > div.ant-modal-content > div.ant-modal-body > form > div:nth-child(12)")
browser.execute_script("arguments[0].scrollIntoView();",target2)
perform()执行以上所有方法。必须调用该方法,才会执行鼠标事件
10.2 键盘操作
一定要记得导入:from selenium.webdriver.common.keys import Keys
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.keys import Keys
driver=webdriver.Chrome()
driver.implicitly_wait(5)
url='http://www.baidu.com'
driver.get(url)
cont=driver.find_element_by_id('kw')
cont.send_keys('12345')
time.sleep(2)
#删除键
cont.send_keys(Keys.BACK_SPACE)
#输入空格键
cont.send_keys(Keys.SPACE)
cont.send_keys('--------')
time.sleep(2)
#全选,复制
cont.send_keys(Keys.CONTROL,'a')
cont.send_keys(Keys.CONTROL,'c')
cont.send_keys(Keys.CONTROL,'v')
cont.send_keys(Keys.CONTROL,'v')
time.sleep(2)
time.sleep(2)
#按下回车键
cont.send_keys(Keys.ENTER)
10.3 冻结界面
在web界面的元素开发者工具的控制台,通过javascript代码冻结界面:
setTimeout(function(){debugger},5000)
#表示在5000ms后,执行debugger命令。即在5s后,会将界面冻结住,停留在debugger界面可供选择元素。
10.4 弹窗
弹出对话框的三种类型:Alert(警告信息),confirm(确认信息),prompt(提示输入)。三种弹框的使用方法都是一样的。
driver.switch_to.alert.text
#打印弹框的文本信息
弹出文本框后,怎么模拟用户点击ok或cancel呢?
点击界面的ok按钮:
driver.switch_to.alert.accept()
点击界面的cancel按钮:
driver.switch_to.alert.dismiss()
driver.switch_to.alert.send_keys(‘123456’)
注意:
有些弹框并非浏览器的alert窗口,而是html元素,这种对话框就需要通过冻结窗口的功能来获取元素了。
学习网站:https://www.byhy.net/
窗口截图
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.keys import Keys
driver=webdriver.Chrome()
driver.implicitly_wait(5)
url='https://www.baidu.com/s?wd=%E4%B8%AD%E5%9B%BD%E6%88%90%E5%8A%9F%E5%8F%91%E5%B0%84%E4%B8%80%E7%AE%AD%E5%8D%81%E5%85%AD%E6%98%9F&sa=fyb_n_homepage&rsv_dl=fyb_n_homepage&from=super&cl=3&tn=baidutop10&fr=top1000&rsv_idx=2&hisfilter=1'
driver.get(url)
time.sleep(2)
driver.maximize_window
time.sleep(1)
#给图片重命名
# img_name=time.strftime("%Y%m%d_%H%M%S")
#或者以下方式
img_name=str(time.time()).replace('.',"_") #获取当前时间以s为单位,然后转成以下格式即可
#把图片保存到当前路径下,也可以指定文件
driver.get_screenshot_as_file("./%s.png" % img_name)
driver.quit()
指定目录:
img_name=time.strftime('%Y%m%d_%H%M%S')
path=os.getcwd()+'/auto_viptesting/error/'+img_name+'.png'
self.driver.get_screenshot_as_file(path)
11、元素操作
点击元素:element对象.click()
输入元素内容:element.send_keys(‘请输入。。。’)
11.1 获取元素信息
获取元素的文本内容:
element=wd.find_element(By.ID,'kw')
print(element.text)
获取元素属性
element=wd.find_element(By.ID,'kw')
print(element.get_attribute('class'))
获取整个元素对应的HTML
element=wd.find_element(By.ID,'kw')
print(element.get_attribute('outerHTML'))
获取某个元素内部的HTML文本内容
print(element.get_attribute('innerHTML'))
获取输入框中的文本
element.get_attribute('value')
获取元素文本内容2:
通过WebElement对象的text属性,可以获取元素展示在界面上的文本内容。对于有些文本没有完全展示在界面的,可以通过以下集中方式获取:
element.get_attribute('innerText')或者element.get_attribute('textContent')
11.2 CSS_selector定位方式
element=wd.find_element(By.ID,'kw')
element=wd.find_element_by_css_selector('span') #通过标签名定位
element=wd.find_element_by_css_selector('.plant') #通过css名定位:class=plant
element=wd.find_element_by_css_selector('div') #通过tag_name
element=wd.find_element_by_css_selector('#id') #通过id定位
element=wd.find_element_by_css_selector('#container > div') #定位id为container内的第一层div
# attr1 > attr2 : >代表attr2必须是attr1的直接子元素
# attr1 空格 attr2 : 代表attr2只要是attr1内部元素即可。
element=wd.find_element_by_css_selector('#container #layer1 > div') #定位id为container内的idlayer1的第一个div
**注意:**
定位中的css选择器中的逗号的优先级是最低的,如果要选择同一个id中的单个元素,需要分开写,如下:
#t1 > span , #t1 > p
若是这样写 #t1 > span,p 表示t1下的span和所有的P标签元素
span:nth-child(2) #定位是span标签,并且是父元素的第二个节点元素。
span:nth-last-child(2)#定位span的倒数第二个元素
span:nth-of-type(2)#span的定位第二个元素
h3+span :表示h3标签后紧跟的span标签
h3 ~ span :选择h3后面所有的span
三、UI自动化实例
1、模拟携带cookie操作
login.py
#先登录,获取cookies
# 1、验证登录功能
# 步骤:
# 1.进入http://vip.ytesting.com/loginController.do?login
# 2.输入账号。密码
# 3.点击登录
# 预期结果:登录成功,跳转主界面
import json
import os
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
class main():
global driver
#初始化浏览器驱动
def login_init(self):
driver=webdriver.Chrome()
driver.implicitly_wait(10)
driver.get("http://120.55.190.222:9090/loginController.do?login2")
driver.maximize_window()
return driver
#登录
def login_system(self,driver):
driver.find_element_by_id('userName').send_keys('SQOA001')
driver.find_element_by_id('password').send_keys('sqtest')
try:
driver.find_element_by_id("but_login").click()
time.sleep(5)
login_msg=driver.find_element_by_xpath('/html/body/div[4]/div[1]/div[1]/nav/div/form/div/span').text
if login_msg=='欢迎登录松勤VIP管理系统':
print('恭喜你,登录成功')
#将cookie从字典转换成字符串
login_cookies=json.dumps(driver.get_cookies())
print(login_cookies)
print("-------------------------------")
with open('./auto_viptesting/cookies.txt','w') as f:
f.write(login_cookies)
print('b保存成功')
except Exception as e:
print(e)
img_name=time.strftime('%Y%m%d_%H%M%S')
path=os.getcwd()+'/auto_viptesting/error/'+img_name+'.png'
print(path)
driver.get_screenshot_as_file(path)
#退出登录
def loginout(self,driver):
driver.find_element_by_xpath('//*[@id="page-wrapper"]/div[1]/nav/ul/li[4]').click()
driver.find_element_by_css_selector('input[value="确定"]').click()
print("账号已退出!")
driver.refresh()
if __name__=='__main__':
m=main()
driver=m.login_init()
m.login_system(driver)
time.sleep(5)
m.loginout(driver)
handler.py
#获取储存在本地的cookies来模拟登录
from selenium import webdriver
import json
def browser_initial():
""""
浏览器初始化,并打开网站界面(未登录状态)
"""
browser = webdriver.Chrome()
browser.get('http://120.55.190.222:9090/loginController.do?login2')
return browser
def log_damai(browser):
"""
从本地读取cookies并刷新页面,成为已登录状态
"""
with open('./auto_viptesting/cookies.txt', 'r', encoding='utf8') as f:
listCookies = json.loads(f.read())
# 往browser里添加cookies
for cookie in listCookies:
#注意配置不要写错!!!-------踩坑好几次啦
cookie_dict = {
'domain': '120.55.190.222',
'name': cookie.get('name'),
'value': cookie.get('value'),
"expires": '',
'path': '/',
'httpOnly': False,
'HostOnly': False,
'Secure': False
}
#注意:此处是将cookies的内容一个一个添加到浏览器,要在for循环里面
browser.add_cookie(cookie_dict)
browser.refresh() # 刷新网页,cookies才成功
if __name__ == "__main__":
browser = browser_initial()
log_damai(browser)
2、新增客户练习
将所有的功能操作分别提取成方法,简化代码
from email import message
from fileinput import filename, lineno
import json
import logging
import os
import time
from selenium import webdriver
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s - %(message)s',
filemode='a',
filename='log_main_dialog.txt')
class main_dialog():
def login_init(self):
driver=webdriver.Chrome()
driver.get("http://120.55.190.222:9090/loginController.do?login2")
driver.implicitly_wait(10)
driver.maximize_window()
self.driver=driver
logging.info('Chrome init success!')
return driver
#获取上一次登录的cookies,用于其他页面免登录操作
def cookies_songqin(self,driver):
# driver.delete_all_cookies()
with open('./auto_viptesting/cookies.txt','r',encoding='utf8') as f:
liscookies=json.loads(f.read())
logging.warning('Take cookies success')
for cookie in liscookies:
cookie_dict={
'domain': '120.55.190.222',
'expires':'',
'httpOnly': cookie.get('httpOnly'),
"name": cookie.get('name'),
'path': '/',
'secure': cookie.get('secure'),
"value": cookie.get('value')
}
driver.add_cookie(cookie_dict)
logging.warning('Add cookies to Chrome')
driver.refresh()
logging.warning('Add cookies success')
#报错截图
def screencap_png(self):
path=os.getcwd()+'/auto_viptesting/error/'+time.strftime("%Y%m%d_%H%M%S")+'.png'
self.driver.get_screenshot_as_file(path)
#回收站,新增客户
def addCustomer_Recycle(self,driver):
driver.find_element_by_css_selector('#side-menu > li:nth-child(3)').click()
driver.find_element_by_css_selector('#side-menu > li.active > ul > li:nth-child(6) > a').click()
driver.switch_to.frame(driver.find_element_by_css_selector('iframe[class="J_iframe"][name="iframe6"]'))
logging.info('switch to the Recycle station')
#新增客户
driver.find_element_by_id('add').click()
logging.info('click and add information of customers to the Recycle station ')
driver.switch_to.parent_frame()
driver.switch_to.frame(driver.find_element_by_css_selector('div[class="ui_content ui_state_full"] iframe'))
name=driver.find_element_by_css_selector('input[id="aac003"][placeholder="请输入20位以内姓名"]').send_keys('小黑')
driver.find_element_by_css_selector('input[placeholder="请输入联系电话"]').send_keys('17745432183')
driver.find_element_by_css_selector('select[name="crm003"] option[selected="selected"][value="1"]').click()
driver.find_element_by_css_selector('select[name="crm004"]>option[selected="selected"][value="1"]').click()
driver.find_element_by_css_selector('select[name="crm001"]>option[selected="selected"][value="00005331"]').click()
logging.info('customers information of Recycle station has written !')
driver.switch_to.parent_frame()
driver.find_element_by_css_selector('input[value="确定"]').click()
if driver.find_element_by_css_selector('div[class="ui_content ui_state_full"] iframe'):
print('add customers failed')
logging.error('add customers failed')
main_dialog.screencap_png(self)
#检查是否添加成功
elements=driver.find_elements_by_css_selector('td[field="aac003"] a')
for element in elements:
if name==element.text:
print("添加回收站客户成功!")
logging.info('Check the customers information of Recycle station,and add it success')
else:
main_dialog.screencap_png(self)
print("没有找到添加回收站客户信息,请重新添加")
logging.error("Add information failed, hadn't find the added-customer name")
if __name__=='__main__':
md=main_dialog()
dr=md.login_init()
md.cookies_songqin(dr)
md.addCustomer_Recycle(dr)
扣取图形验证码实现自动登录
1、首先打开网页,全屏截取当前界面(包含验证码)
2、定位到网页的图形验证码,获取图片四边形占位位置,左上角和右下角
3、然后通过该定位点用crop()抠图,抠出验证码图片保存
4、最后通过pytesseract.image_to_string()将图形验证码取出转换成字符串使用。文章来源:https://www.toymoban.com/news/detail-743136.html
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from PIL import Image
import pytesseract
def get_code():
# url="https://www.chaojiying.com/apiuser/login/"
url="https://blog.csdn.net/weixin_45566935/article/details/103232855#:~:text=%E4%B8%80%E3%80%81%E5%9B%BE%E5%BD%A2%E9%AA%8C%E8%AF%81%E7%A0%81%E6%98%AF%E4%BB%80%E4%B9%88%EF%BC%9F%20%E5%9B%BE%E5%BD%A2%E9%AA%8C%E8%AF%81%E7%A0%81%E6%98%AF%E4%B8%80%E4%BA%9B%E6%B2%A1%E6%9C%89%E8%A7%84%E5%88%99%E7%9A%84%E5%9B%BE%E6%96%87%E7%9A%84%E7%BB%84%E5%90%88%EF%BC%8C%E5%8F%82%E8%80%83%E4%B8%8B%E5%9B%BE,%E4%BA%8C%E3%80%81%E5%9B%BE%E5%BD%A2%E9%AA%8C%E8%AF%81%E7%A0%81%E6%9C%89%E4%BB%80%E4%B9%88%E7%94%A8%EF%BC%9F%20%E9%98%B2%E6%AD%A2%E6%81%B6%E6%84%8F%E6%94%BB%E5%87%BB%E8%80%85%E9%87%87%E7%94%A8%E6%81%B6%E6%84%8F%E5%B7%A5%E5%85%B7%E6%89%B9%E9%87%8F%E6%B3%A8%E5%86%8C%E8%B4%A6%E5%8F%B7%E6%88%96%E6%98%AF%E5%A4%A7%E9%87%8F%E9%A2%91%E7%B9%81%E8%B0%83%E7%94%A8%E6%9F%90%E4%BA%9B%E8%AF%B7%E6%B1%82%EF%BC%8C%E7%BB%99%E6%9C%8D%E5%8A%A1%E5%99%A8%E9%80%A0%E6%88%90%E5%8E%8B%E5%8A%9B%EF%BC%8C%E5%8D%A0%E7%94%A8%E5%A4%A7%E9%87%8F%E7%9A%84%E7%B3%BB%E7%BB%9F%E8%B5%84%E6%BA%90%E3%80%82"
chromepath=r"C:\Users\PC\Downloads\chromedriver_win32\chromedriver.exe"
driver=webdriver.Chrome(chromepath)
driver.implicitly_wait(3)
driver.get(url)
time.sleep(2)
t=time.time()
name1=str(t)+".png"
driver.maximize_window()
driver.save_screenshot(name1)
code=driver.find_element(By.XPATH,'//*[@id="content_views"]/p[1]/text()[3]')
# 左上角位置
left=code.location['x']
top=code.location['y']
# 右下角位置
right=code.size['width']+left
bottom=code.size['height']+top
# right=code.size['height']+left
# bottom=code.size['width']+top
#读取全屏截图
img=Image.open(name1)
#获取验证码图片
img_code=img.crop((left,top,right,bottom))
name2=str(t)+".png"
img_code.save(name2)
mycode=pytesseract.image_to_string(name2)
print(mycode)
driver.close()
ps:由于是学习笔记,过程中有用到网络中的一些知识,若有侵权,望告知删除~文章来源地址https://www.toymoban.com/news/detail-743136.html
到了这里,关于Python之GUI自动化---selenium基础的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!