概念
图遍历和图搜索是解决图论问题时常用的两种基本操作。
- 图遍历是指从图中的某一个节点出发,访问图中所有的节点,确保每个节点都被访问到且不会重复访问。图遍历有两种主要方式:深度优先搜索(DFS)和广度优先搜索(BFS)
- 图搜索是指在图中寻找特定目标的过程。搜索可能是无目标的(即只是为了遍历整个图),也可能是有目标的,希望找到特定的节点或路径。最常用的有目标图搜索算法是Dijkstra算法(用于找到单源最短路径)和A*算法(结合了BFS和启发式搜索,用于找到最优路径)。
图遍历
深度优先搜索 (DFS)
深度优先搜索(Depth First Search,DFS)是一种用于遍历或搜索树或图的算法。它从起始顶点开始,沿着一条路径直到不能继续为止,然后返回到最近的一个未访问过的节点,继续相同的过程,直到所有节点都被访问过。

function DFS(node):
if node is not visited:
mark node as visited
for each neighbor of node:
DFS(neighbor)
DFS 适用场景
- 寻找路径:DFS 在寻找路径方面非常强大,可以用于解决迷宫问题、寻找图中两个节点之间的路径等。
- 拓扑排序:DFS 可以用于在有向图中进行拓扑排序,例如在编译器优化、任务调度等领域中应用广泛。
- 检测环路:DFS 可以用于检测图中是否存在环路,对于拓扑排序来说,有向无环图 (DAG) 才有拓扑排序的结果。
- 生成最小生成树:DFS 可以用于生成最小生成树,例如在 Prim 算法中。
DFS 优缺点
优点:
- 节省空间:相比较于 BFS,DFS 使用递归实现时,不需要额外的数据结构来保存访问状态,因此可能会更节省空间。
- 发现深层次的节点:DFS 会尽可能深地探索某一条分支,因此在找到目标节点或解之前,会一直沿着一条路径向下探索。
缺点:
-
可能陷入死循环:如果图中包含循环,且没有合适的终止条件,DFS 可能会陷入无限循环。可能
-
找到的不是最短路径:由于 DFS 是尽可能深地探索某一条分支,所以找到的路径不一定是最短路径。
广度优先搜索 (BFS)
广度优先搜索(Breadth First Search,BFS)也是一种用于遍历或搜索树或图的算法。它从起始顶点开始,首先访问所有与起始顶点相邻的节点,然后逐层向下访问。

function BFS(start):
create a queue Q
enqueue start into Q
mark start as visited
while Q is not empty:
current = dequeue from Q
for each neighbor of current:
if neighbor is not visited:
mark neighbor as visited
enqueue neighbor into Q
BFS 适用场景
- 寻找最短路径:BFS 可以用于寻找图中两个节点之间的最短路径,因为它会逐层扩展,所以找到的路径一定是最短的。
- 最小生成树 (Prim 算法):BFS 也可以用于 Prim 算法中生成最小生成树的过程。
BFS 优缺点
优势:
- 找到最短路径:BFS 适用于需要找到最短路径的情况,因为它会优先访问距离起点更近的节点。
- 避免陷入死循环:BFS 通常不容易陷入死循环,因为它会逐层扩展,不会无限制地向下探索。
缺点:
- 可能占用更多内存:BFS 通常需要一个队列来保存待访问节点,可能会占用比DFS更多的内存。
- 不一定能找到最深层次的节点:BFS 在发现目标节点时,不一定会沿着一条深度较大的路径找到它。
DFS & BFS 异同点
相同点:
DFS 和 BFS 都是图遍历算法,用于访问图中的所有节点,确保每个节点都被访问到。
不同点:
-
搜索方式:
- DFS:尽可能深地探索某一条分支,直到不能继续为止,然后回溯。
- BFS:先访问与起始节点直接相邻的所有节点,然后逐层向下访问。 -
适用场景:
- DFS 适用于寻找路径、拓扑排序、检测环路等问题。
- BFS 适用于寻找最短路径、最小生成树等问题。 -
找到的路径:
- DFS 找到的路径不一定是最短路径。
- BFS 一定能找到最短路径。 -
空间复杂度:
- DFS 可能会节省一些空间,特别是使用递归实现时。
- BFS 通常会占用更多的内存,因为需要一个队列来保存待访问节点。
总的来说,选择使用DFS还是BFS取决于具体的问题和需求。如果需要寻找最短路径或最优解,通常选择BFS。如果问题需要深度搜索或者对内存消耗有限制,可能会选择DFS。
图搜索
图搜索根据目标可以分为,目标节点搜索和目标路径搜索。
Dijkstra算法
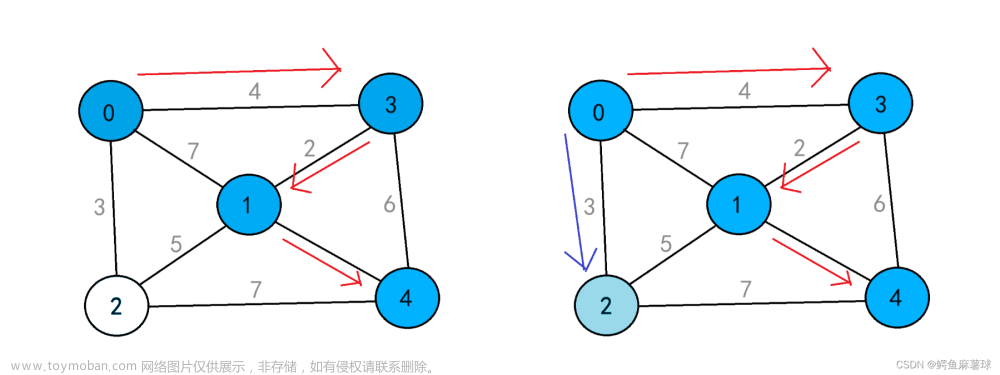
给定一个带权有向图 G=(V,E) ,其中每条边的权是一个非负实数。另外,还给定 V 中的一个顶点,称为源。现在我们要计算从源到所有其他各顶点的最短路径长度。这里的长度是指路上各边权之和。这个问题通常称为单源最短路径问题,如下图所示。
算法思想:将图G中所有的顶点V分成两个顶点集合S和T。以v为源点已经确定了最短路径的终点并入S集合中,S初始时只含顶点v,T则是尚未确定到源点v最短路径的顶点集合。然后每次从T集合中选择S集合点中到T路径最短的那个点,并加入到集合S中,并把这个点从集合T删除。直到T集合为空为止。

function Dijkstra(Graph, source):
create empty set S
create a set Q containing all nodes
create a map distance and set distance[source] = 0
while Q is not empty:
u = node in Q with smallest distance[u]
remove u from Q
add u to S
for each neighbor v of u:
if distance[u] + weight(u, v) < distance[v]:
distance[v] = distance[u] + weight(u, v)
return distance
算法复杂度:
- 设带权有向图的边数为m,顶点数为n。
- 用数组存储顶点方式实现复杂度为: O ( n 2 ) O(n^2) O(n2)
- 用邻接表存储 + 二叉堆实现复杂度为: O ( ( m + n ) l o g n ) O((m+n)logn) O((m+n)logn)
- 用邻接表存储 + 斐波那契堆实现复杂度为: O ( m + n l o g n ) O(m+nlogn) O(m+nlogn)
A*算法
A*算法结合了启发式搜索和Dijkstra算法的思想,用于在加权图中找到起点到目标节点的最短路径。它使用一个启发式函数来估计从当前节点到目标节点的距离,并根据这个估计值选择下一个要扩展的节点。
适用于带有启发式函数的加权图,找到起点到目标节点的最短路径。
function AStar(Graph, source, target):
create empty set openSet and add source to it
create empty set closedSet
create a map gScore and set gScore[source] = 0
create a map fScore and set fScore[source] = heuristic(source, target)
while openSet is not empty:
current = node in openSet with lowest fScore
if current == target:
return reconstructPath(cameFrom, current)
remove current from openSet
add current to closedSet
for each neighbor of current:
if neighbor is in closedSet:
continue
tentative_gScore = gScore[current] + distance(current, neighbor)
if neighbor is not in openSet or tentative_gScore < gScore[neighbor]:
cameFrom[neighbor] = current
gScore[neighbor] = tentative_gScore
fScore[neighbor] = gScore[neighbor] + heuristic(neighbor, target)
if neighbor is not in openSet:
add neighbor to openSet
return failure
Floyd算法
Floyd算法用于解决所有节点对之间的最短路径问题。它采用动态规划的思想,通过中间节点的遍历来更新任意两个节点之间的最短路径。
通过Floyd计算图G=(V,E)中各个顶点的最短路径时,需要引入一个矩阵S,矩阵S中的元素a[i][j]表示顶点i(第i个顶点)到顶点j(第j个顶点)的距离。
假设图G中顶点个数为N,则需要对矩阵S进行N次更新。初始时,矩阵S中顶点a[i][j]的距离为顶点 i 到顶点 j 的权值;如果 i 和 j 不相邻,则a[i][j]=∞。 接下来开始,对矩阵 S 进行N次更新。
第1次更新时,如果"a[i][j]的距离" > “a[i][0]+a[0][j]”(a[i][0]+a[0][j]表示" i 与 j 之间经过第1个顶点的距离"),则更新a[i][j]为"a[i][0]+a[0][j]“。 同理,第k次更新时,如果"a[i][j]的距离” > “a[i][k]+a[k][j]”,则更新a[i][j]为"a[i][k]+a[k][j]"。更新N次之后,操作完成!

function FloydWarshall(Graph):
let dist be a matrix of size VxV, initialized with infinity
for each edge (u, v) in Graph:
dist[u][v] = weight(u, v)
for k from 1 to V:
for i from 1 to V:
for j from 1 to V:
if dist[i][k] + dist[k][j] < dist[i][j]:
dist[i][j] = dist[i][k] + dist[k][j]
return dist
Bellman-Ford算法
Bellman-Ford算法用于在带有负权边的图中找到单源最短路径。它通过对边进行松弛操作来逐步优化到达每个节点的最短距离。解题思路就是假设有一条边
{begin,end,value},如果dis[begin] + value < dis[end],我们可以更新dis[end]的值为dis[begin] + value
Bellman-Ford不能计算有负权回路的图,因为在负权回路中,如果一直转圈的话,值就会一直变小。
 文章来源:https://www.toymoban.com/news/detail-743222.html
文章来源:https://www.toymoban.com/news/detail-743222.html
function BellmanFord(Graph, source):
create a list of size V called distance and set distance[source] = 0
for i from 1 to V-1:
for each edge (u, v) in Graph:
if distance[u] + weight(u, v) < distance[v]:
distance[v] = distance[u] + weight(u, v)
for each edge (u, v) in Graph:
if distance[u] + weight(u, v) < distance[v]:
return "Graph contains a negative-weight cycle"
return distance
SPFA算法
SPFA算法也用于在带有负权边的图中找到单源最短路径。它采用了队列来优化Bellman-Ford算法,通过动态选择要松弛的节点,减少了不必要的松弛操作,提高了算法的效率。文章来源地址https://www.toymoban.com/news/detail-743222.html
function SPFA(Graph, source):
create a queue Q
enqueue source into Q
create a set visited and add source to it
create a map distance and set distance[source] = 0
while Q is not empty:
current = dequeue from Q
remove current from visited
for each neighbor of current:
if distance[current] + weight(current, neighbor) < distance[neighbor]:
distance[neighbor] = distance[current] + weight(current, neighbor)
if neighbor is not in visited:
enqueue neighbor into Q
add neighbor to visited
return distance
到了这里,关于【图】:常用图搜索(图遍历)算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!