1 EAR5数据简介
ERA5是ECMWF(欧洲中期天气预报中心)对1950年1月至今全球气候的第五代大气再分析数据集。
- 包含了四个基本变量(日平均温度、降水、比湿度和距离地表2米的气压),这些变量在每日时间尺度上覆盖全球,从而可以对不同地区和时间段进行全面和统一的分析
- 时间分辨率:1940年至今,小时尺度、日尺度、月尺度
- 空间分辨率:0.1°×0.1°(30km)
EAR5数据集的详细介绍及处理可参见另一博客-【数据集】ERA5(欧洲中期天气预报中心)再分析数据介绍及下载。
2 数据集处理
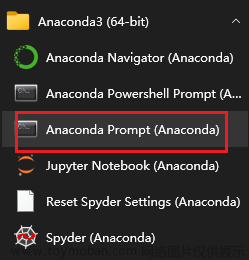
准备工作:xarray库安装
处理ERA5数据的一种常见方法是使用xarray库。
可使用pip list,在cmd控制台查看已安装包(库):
首先,确保已经安装了xarray和netCDF4库,以pip工具(cmd控制台)下载工具箱代码如下:
pip install xarray netCDF4
然后,可以使用xarray的open_dataset()函数加载ERA5数据集:
import xarray as xr
# 加载ERA5数据集
ds = xr.open_dataset('era5_data.nc')
接下来,可以使用xarray的各种功能来处理数据。例如,可以使用sel()函数从数据集中选择特定的经度和纬度:
# 选择经度为-60和纬度为30的数据
ds = ds.sel(longitude=-60, latitude=30)
还可以使用resample()函数对时间进行重新采样:
# 将时间重新采样为每月数据
ds = ds.resample(time='1M').mean()
最后,可以将数据保存到netCDF文件中:文章来源:https://www.toymoban.com/news/detail-743333.html
# 将处理后的数据保存到netCDF文件中
ds.to_netcdf('processed_era5_data.nc')
可根据具体需求,使用xarray的其他功能来处理ERA5数据。文章来源地址https://www.toymoban.com/news/detail-743333.html
2.1 数据预处理-剔除异常值
参考
到了这里,关于【数据集处理】基于Python处理EAR5数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!