引入
如果你是一个队伍的队长,现在有 24 个队员,需要将他们分成 6 组,你会怎么分?其实有一种方法是让所有人排成一排,然后从队头开始报数,报的数字就是编号。当所有人都报完数后,这 24 人也被分为了 6 组,看下方。
(你可能会让 1~4 号为第一组,5~8 号为第二组……但是这样有新成员加入时,就很难决定新成员的去向)
编号除以 6 能被整除的为第一组: 6 12 18 24
编号除以 6 余数是 1 的为第二组:1 7 13 19
编号除以 6 余数是 2 的为第三组:2 8 14 20
编号除以 6 余数是 3 的为第四组:3 9 15 21
编号除以 6 余数是 4 的为第五组:4 10 16 22
编号除以 6 余数是 5 的为第六组:5 11 17 23
OK呀,也是分好了。通过这种方式划分小组,无论是往小组中添加成员,还是快速确定成员的小组都非常方便,例如新加一个队员编号为 25 号,就能够很从容地让他加入到第二组。这种编号方式就是高效的散列,或者称为“哈希”,所以我们经常听说的哈希表也叫做散列表。(哈希就是Hash英文的音译,而Hash的意思是散列)
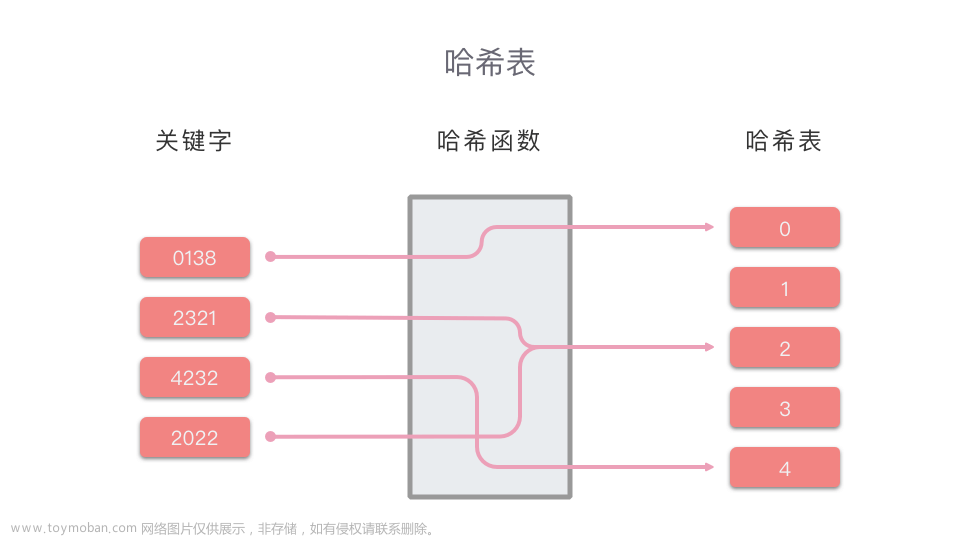
以上的过程是通过把关键码值 key (编号) 映射到表中的一个位置(数组的下标)来访问记录,从而加快了查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
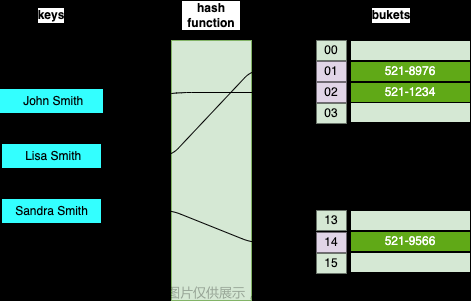
上面的例子中每个人的编号都是一个关键码值 key ,例如 17 通过映射函数(编号%6 )就能得到一个位置 5 ,就能在数组里下标为 5 的位置找到第六组的所有成员,从而快速找到 17 所在的位置,如下图。

到这里你可以想象一下,一个 key 经过了加工得到了所在的地址,知道地址就可以快速访问所在的地方,就比如你知道一个学生的学号,你通过一系列操作你可以得知那个学生所在的宿舍楼,甚至知道所在的宿舍,从而去那个宿舍交流一下。
哈希表概念
散列表-哈希表 它是基于快速存取的角度设计的,“以空间换时间”。
为什么哈希表很快呢?例如在上面的例子中,问你队伍中存在编号为 17 的队员吗?如果你一个一个遍历你要遍历 24次,不能排除任何一个数据。假设数组有序,你使用二分查找一次也只能排除一半的数据,但是你使用哈希表你可以一次排除六分之五的数据,只需要到第六组中去遍历了,假如小组数量变多是不是效率更高了。
键(key):组员的编号,如:1、15、36……每个编号都是独一无二的,具有唯一性,为了快速访问到某一个组员。
值(value):组员存储的信息,可以是一个整型,可以是一个结构体、也可以是一个类。
索引:用 key 映射到数组的下标(0,1,2,3,4,5)用来快速定位并检索数据
哈希桶:用来保存索引的数组(或链表)存放的成员为索引值相同的组员
映射函数:将文件编号映射到索引上,采用求余法。如文件编号 17 % 5,得到索引 2
哈希表的实现
哈希表的数据结构定义
我的哈希桶的实现方式是链表。
#define DEFAULT_SIZE 16 //默认的哈希表大小
typedef struct _ListNode //哈希链表
{
void* date; //值,指向保存的数据
int key; //键
struct _ListNode* next;
}ListNode;
typedef ListNode* List;
typedef ListNode* Element;
typedef struct _HashTable
{
int TableSize;
List* lists; //二级指针,指向指针数组,指针数组里的元素是一级指针,指向了哈希桶
}HashTable; 
我们是用指向HashTable的指针,访问lists二级指针,lists[i]【(*lists + i)】都是指向了ListNode的指针,用lists[i]去访问哈希桶,如果不太明白可以看看哈希表的初始化。
哈希函数
其实哈希函数的参数不仅仅只有整型,例如参数可以是一个字符串,将字符串的首字符的ASCII码返回也是一个函数。只需要对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址就可以了。
如图:
 文章来源:https://www.toymoban.com/news/detail-743410.html
文章来源:https://www.toymoban.com/news/detail-743410.html
int Hash(int key, int TableSize)
{
//根据 key 得到索引,也就得到了哈希桶的位置
return (key % TableSize);
}初始化哈希表
HashTable* initHash(int TableSize)
{
if (TableSize <= 0) //哈希桶的数量不能小于 1
{
TableSize = DEFAULT_SIZE; //使用默认的大小
}
HashTable* Hash = NULL; //指向哈希表结构体
Hash = (HashTable * ) malloc(sizeof(HashTable));
if (Hash == NULL) //防御性编程
{
cout << "哈希表分配内存失败" << endl;
return NULL;
}
//为二级指针分配内存,指向指针数组,每一个指针指向一个哈希桶
Hash->lists = (List*)malloc(sizeof(List) * TableSize);
if (Hash->lists == NULL) //防御性编程
{
cout << "哈希表分配内存失败" << endl;
free(Hash); // 运行到这一步,说明Hash不为空,别忘记释放
return NULL;
}
for (int i = 0; i < TableSize; i++)
{
Hash->lists[i] = (ListNode*)malloc(sizeof(ListNode));
if (Hash->lists[i] == NULL) //防御性编程
{
for (int j = 0; j < i; j++)
{
free(Hash->lists[j]);
}
free(Hash->lists);
free(Hash);
return NULL;
}
else
{
memset(Hash->lists[i], 0, sizeof(ListNode)); //将指向的节点初始化,全部变成0
}
}
return Hash;
}查找这个键在哈希表中是否存在
Element Find(HashTable* hash, int key)
{
int i = 0;
List list = NULL;
Element e = NULL; //Element 和 List 本质一样
i = Hash(key, hash->TableSize); //确定哈希桶位置
list = hash->lists[i]; //指向哈希桶
e = list->next;
while (e != NULL && e->key != key)
{
e = e->next;
}
return e; //存在就返回这个节点,不存在就返回 NULL
}哈希表插入元素
//哈希表插入元素,键key和值(*date)
void insertHash(HashTable* hash, int key, void* date)
{
Element e = NULL , temp = NULL; //temp为指向新加节点
List lists = NULL;
e = Find(hash, key);
if (e == NULL)
{
temp = (ListNode*)malloc(sizeof(ListNode));
if (temp == NULL) //防御性编程
{
cout << "为新加节点分配内存失败" << endl;
return;
}
lists = hash->lists[Hash(key, hash->TableSize)]; //指向新加节点所在的哈希桶
//采用前插法,插入节点
temp->date = date;
temp->key = key;
temp->next = lists->next;
lists->next = temp;
}
else
{
cout << "此键已经存在于哈希表" << endl;
}
}哈希表删除元素
void deleteHash(HashTable* hash, int key)
{
int i = 0;
i = Hash(key, hash->TableSize);
Element e = NULL,last = NULL;
List l = NULL;
l = hash->lists[i];
last = l;
e = l->next;
while (e != NULL && e->key != key)
{
last = e; //last保存着要删除的节点的上一个节点
e = e->next;
}
if (e != NULL) //存在这个元素
{
last->next = e->next;
free(e);
}
else
{
;
}
}哈希表元素中提取数据
void* getDate(Element e)
{
return e ? e->date : NULL;
}销毁哈希表
void destoryHash(HashTable* hash)
{
int i = 0;
List l = NULL;
Element tmp = NULL,next = NULL;
for (int i = 0; i < hash->TableSize; i++)
{
l = hash->lists[i];
tmp = l->next;
while (tmp != NULL)
{
next = tmp->next;
free(tmp);
tmp = next;
}
free(l);
}
free(hash->lists);
free(hash);
}全部代码
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#define DEFAULT_SIZE 16 //默认的哈希表大小
typedef struct _ListNode //哈希链表
{
void* date; //值,指向保存的数据
int key; //键
struct _ListNode* next;
}ListNode;
typedef ListNode* List;
typedef ListNode* Element;
typedef struct _HashTable
{
int TableSize;
List* lists;
}HashTable;
//哈希函数
int Hash(int key, int TableSize)
{
//根据 key 得到索引,也就得到了哈希桶的位置
return (key % TableSize);
}
//初始化哈希表
HashTable* initHash(int TableSize)
{
if (TableSize <= 0) //哈希桶的数量不能小于 1
{
TableSize = DEFAULT_SIZE; //使用默认的大小
}
HashTable* Hash = NULL; //指向哈希表
Hash = (HashTable * ) malloc(sizeof(HashTable));
if (Hash == NULL)
{
cout << "哈希表分配内存失败" << endl;
return NULL;
}
//为哈希桶分配内存,为指针数组,每一个指针指向一个哈希桶
Hash->lists = (List*)malloc(sizeof(ListNode*) * TableSize);
if (Hash->lists == NULL) //防御性编程
{
cout << "哈希表分配内存失败" << endl;
free(Hash); // 运行到这一步,说明Hash不为空,别忘记释放
return NULL;
}
for (int i = 0; i < TableSize; i++)
{
Hash->lists[i] = (ListNode*)malloc(sizeof(ListNode));
if (Hash->lists[i] == NULL) //防御性编程
{
for (int j = 0; j < i; j++)
{
free(Hash->lists[j]);
}
free(Hash->lists);
free(Hash);
return NULL;
}
else
{
memset(Hash->lists[i], 0, sizeof(ListNode)); //将指向的节点初始化
}
}
return Hash;
}
//查找这个键在哈希表中是否存在
Element Find(HashTable* hash, int key)
{
int i = 0;
List list = NULL;
Element e = NULL;
i = Hash(key, hash->TableSize); //确定哈希桶位置
list = hash->lists[i]; //指向哈希桶
e = list->next;
while (e != NULL && e->key != key)
{
e = e->next;
}
return e; //存在就返回这个节点,不存在就返回 NULL
}
//哈希表插入元素,键key和值(*date)
void insertHash(HashTable* hash, int key, void* date)
{
Element e = NULL , temp = NULL; //temp为指向新加节点
List lists = NULL;
e = Find(hash, key);
if (e == NULL)
{
temp = (ListNode*)malloc(sizeof(ListNode));
if (temp == NULL) //防御性编程
{
cout << "为新加节点分配内存失败" << endl;
return;
}
lists = hash->lists[Hash(key, hash->TableSize)]; //指向新加节点所在的哈希桶
//采用前插法,插入节点
temp->date = date;
temp->key = key;
temp->next = lists->next;
lists->next = temp;
}
else
{
cout << "此键已经存在于哈希表" << endl;
}
}
//哈希表删除元素
void deleteHash(HashTable* hash, int key)
{
int i = 0;
i = Hash(key, hash->TableSize);
Element e = NULL,last = NULL;
List l = NULL;
l = hash->lists[i];
last = l;
e = l->next;
while (e != NULL && e->key != key)
{
last = e; //last保存着要删除的节点的上一个节点
e = e->next;
}
if (e != NULL) //存在这个元素
{
last->next = e->next;
free(e);
}
else
{
;
}
}
//哈希表元素中提取数据
void* getDate(Element e)
{
return e ? e->date : NULL;
}
//销毁哈希表
void destoryHash(HashTable* hash)
{
int i = 0;
List l = NULL;
Element tmp = NULL,next = NULL;
for (int i = 0; i < hash->TableSize; i++)
{
l = hash->lists[i];
tmp = l->next;
while (tmp != NULL)
{
next = tmp->next;
free(tmp);
tmp = next;
}
free(l);
}
free(hash->lists);
free(hash);
}
int main(void)
{
const char* elems[] = { "苍老师","一花老师","天老师" };
HashTable *hash = NULL;
hash = initHash(31);
insertHash(hash, 1, (void*)elems[0]);
insertHash(hash, 2, (void*)elems[1]);
insertHash(hash, 3, (void*)elems[2]);
deleteHash(hash, 3);
for (int i = 0; i < 3; i++)
{
Element e = Find(hash, i + 1);
if (e)
{
cout << (const char *)getDate(e) << endl;
}
else
{
cout << "键值为" << i + 1 << "的元素不存在" << endl;
}
}
return 0;
}如果不太理解的话,可以多看看结构体的定义和初始化,谢谢你看到这里!文章来源地址https://www.toymoban.com/news/detail-743410.html
到了这里,关于哈希表----数据结构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!