1. DFS
1. 排列数字(3分钟)
每次遍历dfs参数是 遍历的坑位
原题链接
import java.util.*;
public class Main{
static int N = 10,n;
static int[] path = new int[N];
static boolean[] st = new boolean[N];
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
dfs(0);
}
public static void dfs(int u){
if(u == n){
for(int i = 0 ; i < n ; i ++ ){
System.out.print(path[i] + " ");
}
System.out.println();
return;
}
for(int i = 1 ; i <= n ; i ++ ){
if(!st[i]){
path[u] = i;
st[i] = true;
dfs(u + 1);
st[i] = false;
//path[u] = 0;
}
}
}
}
2. n-皇后问题
原题链接文章来源:https://www.toymoban.com/news/detail-743418.html
方法 1. 按行遍历(过程中有回溯、剪枝)
思想:
- 每次递归中,遍历一行的元素,如果可以放皇后,就递归到下一行,下一行中不行了,就返回来,回溯,
import java.util.*;
public class Main
{
static Scanner in = new Scanner(System.in);
static int N = 20;
static boolean[] col = new boolean[N], dg = new boolean[N], udg = new boolean[N];
static char[][] chs = new char[N][N];
static int n = 0;
static void dfs(int u)
{
if (u == n)
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
System.out.print(chs[i][j]);
}
System.out.println();
}
System.out.println();
return;
}
for (int i = 0; i < n; i++)
{
if (!col[i] && !dg[i - u + n] && !udg[i + u])
{
chs[u][i] = 'Q';
col[i] = dg[i - u + n] = udg[i + u] = true;
dfs(u + 1);
col[i] = dg[i - u + n] = udg[i + u] = false;
chs[u][i] = '.';
}
}
}
public static void main(String[] args)
{
n = in.nextInt();
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++) chs[i][j] = '.';
dfs(0);
}
}
方法2. 按每个元素遍历(没有减枝)
// 不同搜索顺序 时间复杂度不同 所以搜索顺序很重要!
#include <iostream>
using namespace std;
const int N = 20;
int n;
char g[N][N];
bool row[N], col[N], dg[N], udg[N];
// 因为是一个个搜索,所以加了row
// s表示已经放上去的皇后个数
void dfs(int x, int y, int s)
{
// 处理超出边界的情况
if (y == n) y = 0, x ++ ;
if (x == n) { // x==n说明已经枚举完n^2个位置了
if (s == n) { // s==n说明成功放上去了n个皇后
for (int i = 0; i < n; i ++ ) puts(g[i]);
puts("");
}
return;
}
//和上面按行遍历的差别就是,这里没有循环
// 分支1:放皇后
if (!row[x] && !col[y] && !dg[x + y] && !udg[x - y + n]) {
g[x][y] = 'Q';
row[x] = col[y] = dg[x + y] = udg[x - y + n] = true;
dfs(x, y + 1, s + 1);
row[x] = col[y] = dg[x + y] = udg[x - y + n] = false;
g[x][y] = '.';
}
// 分支2:不放皇后
dfs(x, y + 1, s);
}
int main() {
cin >> n;
for (int i = 0; i < n; i ++ )
for (int j = 0; j < n; j ++ )
g[i][j] = '.';
dfs(0, 0, 0);
return 0;
}
2. BFS(队列)
1. 走迷宫
二刷总结(队列存储一个节点pair<int,int>)
三刷总结 走过的点标记上距离(既可以记录距离,也可以判断是否走过)
- bfs 需要队列
- ==走过的点标记上距离(既可以记录距离,也可以判断是否走过)==没走过的置为-1
- (队列存储一个节点pair<int,int>)
原题链接
原题链接
import java.io.BufferedReader;
import java.io.*;
public class Main {
public static int n,m;
public static int[][] gap = new int[110][110];
public static int[][] dist = new int[110][110];
public static PII[] q = new PII[110*110];
public static int hh,tt;
public static void main(String[] args) throws IOException {
BufferedReader rd = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter wt = new BufferedWriter(new OutputStreamWriter(System.out));
String[] s = rd.readLine().split(" ");
n = Integer.parseInt(s[0]);
m = Integer.parseInt(s[1]);
for (int i = 0; i < n; i++) {
String[] st = rd.readLine().split(" ");
for (int j = 0 ; j < m ;j ++ ) {
gap[i][j] = Integer.parseInt(st[j]);
dist[i][j] = -1;
}
}
System.out.println(bfs());
wt.close();
}
public static int bfs(){
hh = 0 ; tt = -1; //队列的头节点=0,尾节点 = 0;
dist[0][0] = 0; // 我们首先站在的是第一个点,所以值距离设置为0
q[++tt] = new PII(0,0); //然后将第一个点下标存入q队列中
//利用向量的方法进行让他上下左右判断是否能够前进
int[] dx = {-1,0,1,0};//上(-1,0) 下(1,0)
int[] dy = {0,1,0,-1};//左(0,-1) 右(0,1)
while(hh <= tt){
PII t = q[hh++]; //每一次将头结点拿出来
for(int i = 0 ; i < 4 ; i ++ ){//然后进行下一步要往哪里走,这里可能有多重选择可走
int x = t.first + dx[i]; //这里进行x轴向量判断
int y = t.second + dy[i];//这里进行y轴向量的判断
//如果x,y满足在地图中不会越界,然后地图上的点g是0(表示可以走),
//然后这里是没走过的距离d是-1;
if(x >= 0 && x < n && y >= 0 && y < m && gap[x][y] == 0 && dist[x][y] == -1){
//将现在可以走的点(x,y)加上上一个点计数距离的点加上一,就是现在走到的点的距离
dist[x][y] = dist[t.first][t.second] + 1;
q[++tt] = new PII(x,y);//然后将这一个可以走的点存入队列尾
}
}
}
return dist[n-1][m-1]; //最后返回的是地图走到尽头最后一个位置的位置统计的距离
}
static class PII {
int first;
int second;
public PII(int first,int second) {
this.first = first;
this.second = second;
}
}
}
★ ★ 例题2. 八数码
原题链接
二刷总结
- 字符串存储二维数组
- 每种情况对应一个移动距离,正好就用map
- 字符串有find函数,map有count函数
- map的count就可以判别 该位置是否走过
补充一点就是,一种情况只能走过一次!不可能走走走地出现与之前一样的情况,这不就是白走了嘛- 先swap才能接着判断
import java.util.*;
public class Main{
public static void swap(char[] arr,int x,int y){
char temp = arr[x];
arr[x] = arr[y];
arr[y] = temp;
}
public static int bfs(String start ,String end){
Map<String,Integer> map = new HashMap<>();// 用来存储每种方式走过的距离
Queue<String> q = new LinkedList<>();//队列,用来存储内容
q.offer(start);//将初试元素插入到队列的尾部
map.put(start,0);//将初始状态的值对应map中value值对应0;表示还没有进行前进;
int[] dx = {-1,0,1,0},dy = {0,1,0,-1};//表示前进方向;上下左右
//如果队列不是空的继续循环
while(!q.isEmpty()){
String t = q.poll();//将队头元素返回并抛出
int k = t.indexOf('x');//找到x再String中的下标
int x = k / 3 ; int y = k % 3;//然后进行以为数组转化成二维的操作下标操作
if(t.equals(end)) return map.get(t); //如果进行过程中跟结束end相同的就提前结束
for(int i = 0 ; i < 4 ; i ++ ){//这里进行四种方案
int a = x + dx[i],b = y + dy[i];
if(a >= 0 && a < 3 && b >= 0 && b < 3){ //如果这种情况没有超出边界
//将这种情况的字符串转化成字符数组,能够有下标进行交换
char[] arr = t.toCharArray();
//然后交换x跟没有超出边界的值进行交换,二维转成一维下标x*3+y;
swap(arr, k, a * 3 + b);
//然后将字符数组转化成字符串
String str = new String(arr);
if(map.get(str) == null){ //如果这种情况对应的value值是null,说明还没有走过
map.put(str,map.get(t) + 1);//然后将这种情况对应进行上一步的距离加上1
q.offer(str);//然后将新的情况插入到队尾中
}
}
//思路:
//比如走到距离为2即第二步时候,上下左右四种情况都可行的情况下,将每一中情况都
//插入到队列尾部,然后queue[] = {2[1],2[1],2[1],2[1],3[1],3[1],3[2],3[4]};
//队列会执行从前面开始2执行完之后可能会有3种情况往队列尾插入,
//然后这样依次每一层进行搜索遍历
//因为步数小的都会先插入到队列中,队列原则"先进先出"原则,所以肯定会把所有的
//第二步执行完之后才会执行前面第二步执行过程中产生的三步,然后一直执行到最后第n步
}
}
return -1; //如果执行完之后没有结果,那么返回-1;
}
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
String start = "";
for(int i = 0 ; i < 9 ; i ++ ){
String s = scan.next();
start += s;
}
String end = "12345678x";
System.out.println(bfs(start,end));
}
}
3. 树与图的dfs
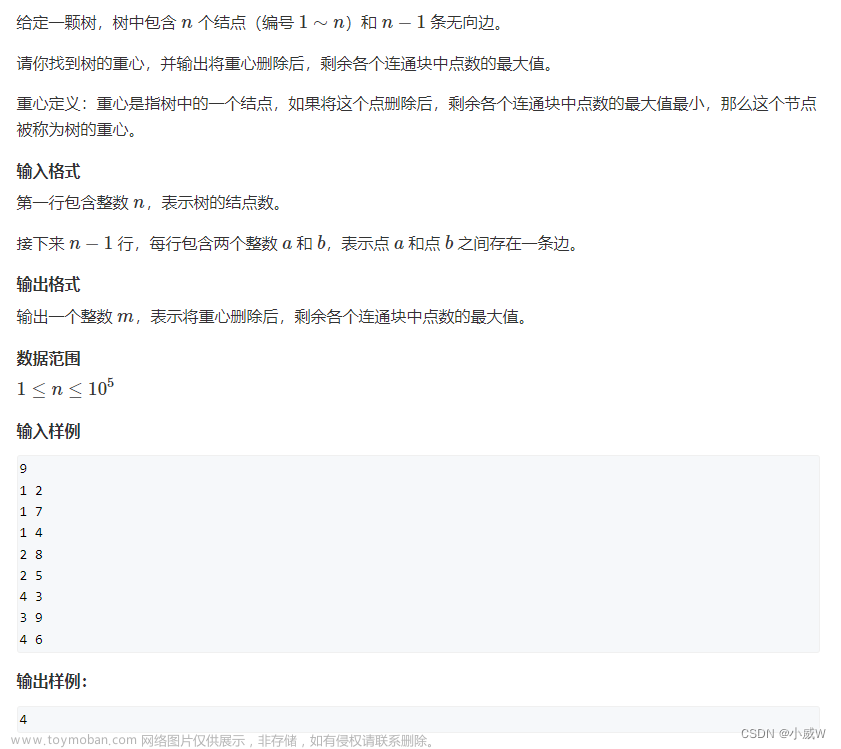
1. 树的重心
原题链接
二刷总结
1. 如何找根节点?用无向图遍历,则不需要根节点
2. 把dfs 中需要算出来的写出来,就清晰怎么写了
void add(int a,int b)
{
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
- 遍历过的点标记一下,不再遍历,因为无向图可能往回遍历
import java.util.*;
public class Main{
static int N = 100010,M = N * 2,idx,n;
static int[] h = new int[N];
static int[] e = new int[M];//存的是双倍,所以是M
static int[] ne = new int[M];//存的是双倍,所以是M
static boolean[] st = new boolean[N];
static int ans = N; //一开始将最大值赋值成N,最大了
/***
* 邻接表,存储方法
* 邻接表不用管执行顺序,只需要知道每个节点能够执行到每个多少个节点就行
* 比如案例中4 3 , 4 6 ,头结点4插入两个节点3和6,所以执行到4就能够执行3和6,
* 固定的,邻接表就是这样子的
***/
public static void add(int a,int b){
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
//返回的是当前子树的数量,比如1下面的所有数量包括自己就是9
public static int dfs(int u){
int res = 0;//连通块中的最大值这个其实就是ans,到时候跟ans比较大小,小的话就赋值给ans的
st[u] = true;//将这个删除的点标记,下次不在遍历
int sum = 1;//将删除的点也算上是初始值就是1;到时候有利于求n-sum;
//单链表遍历
for(int i = h[u];i != -1 ; i = ne[i]){
int j = e[i];//然后将每一个的指向的点用变量表示出来
if(!st[j]){ //然后如果是没用过,没被标记过的,就可以执行
int s = dfs(j);//然后递归他的邻接表上面所有能够抵达的点
//然后返回的数量是他所删除的点下面的连通块的大小
res = Math.max(res,s); //然后和res比较一下大小,谁大谁就是最大连通块
sum += s; //这里是将每递归一个点,就增加一个返回的s,就可以将这个值作为返回值成为最大连通块
}
}
/***
* 因为邻接表表中只是往下面执行,删除的点的上面的连通块可能是最大的连通块,
* 所以需要用总数减去我们下面所统计出来的最大的连通块
* 然后将最大的连通块的值赋值给res
* **/
res = Math.max(res,n-sum);
//然后将每个次的最大值进行比较,留下最小的最大值
ans = Math.min(res,ans);
return sum;
}
public static void main(String[] ags){
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
//这里是将每一个头节点都赋值成-1
for(int i = 1 ; i < N ; i++ ){
h[i] = -1;
}
//案例输入输出
for(int i = 0 ; i < n - 1 ; i ++){
int a = scan.nextInt();
int b = scan.nextInt();
//因为是无向边,所以就两个数同时指向对方
add(a,b);
add(b,a);
}
dfs(1);//从1开始
//最后输出的是最小的最大值
System.out.println(ans);
}
}
4. 树与图的bfs(最短路)
1. 图中点的层次( 无权最短路 )
原题链接
原题链接
import java.util.Scanner;
public class Main{
static int N = 100010,n,m,idx,hh,tt;
static int[] h = new int[N],e = new int[N],ne = new int[N];
static int[] d = new int[N],q = new int[N];
//这个是单链表的模板
public static void add(int a,int b){
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
public static int bfs(){
hh = 0 ; tt = -1;
d[1] = 0; // 第一个点是距离为0
q[++tt] = 1; //然后将第一个点加进去
//如果队列不是空的
while(hh <= tt){
int t = q[hh++]; //取出队头
//然后遍历一下单链表
for(int i = h[t] ; i != -1 ; i = ne[i]){
int s = e[i]; //然后这个点用一个变量表示
if(d[s] == -1){ //如果这个点是没走过的
d[s] = d[t] + 1; //然后将这个点距离加上1
q[++tt] = s;//然后将第二步的点加入到队尾中
}
}
}
return d[n]; //最后返回1到n的最短距离d
}
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
m = scan.nextInt();
//这里需要将距离跟头结点都赋值成-1
for(int i = 1 ; i < N ; i++){
h[i] = -1;
d[i] = -1;
}
for(int i = 0 ; i < m ; i ++ ){
int a = scan.nextInt();
int b = scan.nextInt();
add(a,b);
}
System.out.println(bfs());
}
}
5. 拓扑排序
1. 有向图的拓扑排序 ✔12.24
做题总结
- 拓扑是一个宽搜
- 遍历顺序是 度为0(可能有多个为0的)
- 可以用q[] 表示队列,这样就用一个队列就可以存储拓扑的结果和 遍历的过程了(也就是拓扑排序的遍历过程,就是答案顺序)
原题链接
import java.util.*;
public class Main{
static int N = 100010,n,m,hh,tt,idx;
static int[] e = new int[N],ne = new int[N],h = new int[N];
static int[] q = new int[N];
static int[] d = new int[N];
public static void add(int a,int b){
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
public static boolean bfs(){
hh = 0 ; tt = -1;
for(int i = 1 ; i <= n ; i ++ ){
if(d[i] == 0){ //首先将所有入度为0的点全部插入q队列中
q[++tt] = i;
}
}
while(hh <= tt){
int t = q[hh++]; //拿出队头
for(int i = h[t] ; i != -1; i = ne[i]){ //遍历一下队列中所有的边
int s = e[i]; //然后将这个边拿出来
d[s] -- ; //将这个边的入度数减1
if(d[s] == 0){
q[++tt] = s; //如果减完之后s的入度数为0;就将他插入队列中
}
}
}
return tt == n - 1; //最后返回,如果队列中的tt等于n-1个数,说明就是正确的的
}
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
m = scan.nextInt();
for(int i = 0 ; i < N ; i ++ ){
h[i] = -1;
}
while(m -- > 0){
int a = scan.nextInt();
int b = scan.nextInt();
add(a,b);
d[b] ++;
}
if(bfs()){
//队列刚好队头删除的点就是我们的拓扑序列,因为我们只是将hh往后面移动,但是它具体前面的值还在,直接输出就行
for(int i = 0 ; i < n; i ++ ){
System.out.print(q[i] + " ");
}
}else{
System.out.println("-1");
}
}
}
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int N = 1e5+10;
bool st[N];
int e[N],ne[N],idx,h[N];
int b[N];//每个节点的入读
int n,k;
queue<int> q,ans;
void bfs()
{
while(q.size())
{
int f = q.front();
q.pop();
for(int i = h[f]; i != -1; i = ne[i])
{
b[e[i]]--;
if(b[e[i]]==0)
{
ans.push(e[i]);
q.push(e[i]);
}
}
}
}
void add(int a,int b)
{
e[idx] = b,ne[idx] = h[a],h[a] = idx++;
}
int main()
{
memset(h,-1,sizeof h);
cin >> n >> k;
for(int i = 1; i <= k; i++)
{
int a,bb;
cin >> a >> bb;
add(a,bb);
b[bb]++;
}
for(int i = 1; i <= n; i++)
{
if(b[i]==0)
{
//cout << i << endl;
q.push(i);
ans.push(i);
}
}
bfs();
if(ans.size()!=n)
{
cout << -1;
return 0;
}
//cout << ans.size() << endl;
while(ans.size())
{
cout << ans.front() << ' ';
ans.pop();
}
return 0;
}
6. 朴素dijkstra算法

1. Dijkstra求最短路 I(邻接矩阵)✔12.24
原题链接
刷题总结
- 稀疏矩阵 和 疏密矩阵(疏密矩阵 可以用 邻接矩阵存储方式)
- 邻接矩阵直接就可以存储 边距离了
- d存储到1节点的距离
二刷总结
- dijk就是两步 :1. 在dist里选出最小值 2.遍历dist更新
如何选(如下)
int t = -1;
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
import java.util.*;
public class Main{
static int N = 510,n,m, max = 0x3f3f3f3f;
static int[][] g = new int[N][N];//存每个点之间的距离
static int[] dist = new int[N];//存每个点到起点之间的距离
static boolean[] st = new boolean[N];//存已经确定了最短距离的点
public static int dijkstra(){
Arrays.fill(dist,max);//将dist数组一开始赋值成较大的数
dist[1] = 0; //首先第一个点是零
//从0开始,遍历n次,一次可以确定一个最小值
for(int i = 0 ; i < n ; i ++ ){
int t = -1; //t这个变量,准备来说就是转折用的
for(int j = 1 ; j <= n ; j ++ ){
/***
* 因为数字是大于1的,所以从1开始遍历寻找每个数
* 如果s集合中没有这个数
* 并且t == -1,表示刚开始 或者 后面的数比我心找的数距离起点的距离短
* 然后将j 的值赋值给 t
***/
if(!st[j] && (t == -1 || dist[j] < dist[t])){
t = j;
}
}
st[t] = true;//表示这个数是已经找到了确定了最短距离的点
//用已经确认的最短距离的点来更新后面的点
//就是用1到t的距离加上t到j的距离来更新从1到j的长度
for(int j = 1 ; j <= n ; j ++ ){
//
dist[j] = Math.min(dist[j],dist[t] + g[t][j]);
}
}
//如果最后n的长度没有改变,输出-1,没有找到;否则输出最短路n
if(dist[n] == max) return -1;
else return dist[n];
}
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
m = scan.nextInt();
//将他们每个点一开始赋值成一个较大的值
for(int i = 1 ; i <= n ; i ++ ){
Arrays.fill(g[i],max);
}
while(m -- > 0){
int a = scan.nextInt();
int b = scan.nextInt();
int c = scan.nextInt();
g[a][b] = Math.min(g[a][b],c);//这个因为可能存在重边,所以泽出最短的
}
int res = dijkstra();
System.out.println(res);
}
}
7. 堆优化版dijkstra
★ 1. Dijkstra求最短路 II(邻接表)✔12.24
原题链接
while(heap.size())
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.PriorityQueue;
public class Main{
static int N = 100010;
static int n;
static int[] h = new int[N];
static int[] e = new int[N];
static int[] ne = new int[N];
static int[] w = new int[N];
static int idx = 0;
static int[] dist = new int[N];// 存储1号点到每个点的最短距离
static boolean[] st = new boolean[N];
static int INF = 0x3f3f3f3f;//设置无穷大
public static void add(int a,int b,int c)
{
e[idx] = b;
w[idx] = c;
ne[idx] = h[a];
h[a] = idx ++;
}
// 求1号点到n号点的最短路,如果不存在则返回-1
public static int dijkstra()
{
//维护当前未在st中标记过且离源点最近的点
PriorityQueue<PIIs> queue = new PriorityQueue<PIIs>();
Arrays.fill(dist, INF);
dist[1] = 0;
queue.add(new PIIs(0,1));
while(!queue.isEmpty())
{
//1、找到当前未在s中出现过且离源点最近的点
PIIs p = queue.poll();
int t = p.getSecond();
int distance = p.getFirst();
if(st[t]) continue;
//2、将该点进行标记
st[t] = true;
//3、用t更新其他点的距离
for(int i = h[t];i != -1;i = ne[i])
{
int j = e[i];
if(dist[j] > distance + w[i])
{
dist[j] = distance + w[i];
queue.add(new PIIs(dist[j],j));
}
}
}
if(dist[n] == INF) return -1;
return dist[n];
}
public static void main(String[] args) throws IOException{
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
String[] str1 = reader.readLine().split(" ");
n = Integer.parseInt(str1[0]);
int m = Integer.parseInt(str1[1]);
Arrays.fill(h, -1);
while(m -- > 0)
{
String[] str2 = reader.readLine().split(" ");
int a = Integer.parseInt(str2[0]);
int b = Integer.parseInt(str2[1]);
int c = Integer.parseInt(str2[2]);
add(a,b,c);
}
System.out.println(dijkstra());
}
}
class PIIs implements Comparable<PIIs>{
private int first;//距离值
private int second;//点编号
public int getFirst()
{
return this.first;
}
public int getSecond()
{
return this.second;
}
public PIIs(int first,int second)
{
this.first = first;
this.second = second;
}
@Override
public int compareTo(PIIs o) {
// TODO 自动生成的方法存根
return Integer.compare(first, o.first);
}
}
8. Bellman-Ford算法(遍历 边)
1. 有边数限制的最短路 ✔ 12.24
原题链接
做题总结
- b到1的距离 = min(a到1的距离 + a 到 b的距离)
import java.io.*;
import java.util.*;
public class Main{
static int N = 510,M = 10010,n,m,k,max = 0x3f3f3f3f;
static int[] dist = new int[N];//从一号点到n号点的距离
static Node[] edgs = new Node[M];//结构体
static int[] back = new int[N];//备份数组
public static void bellman_ford(){
Arrays.fill(dist,max);//初始化一开始全部都是max
dist[1] = 0;//然后第一个点到距离是0
for(int i = 0 ; i < k ; i++ ){ //因为不超过k条边,所以只需要遍历k次,就可以找出最短距离,反之则没有
back = Arrays.copyOf(dist,n+1);//备份:因为是从1开始存到n,所以需要n+1
for(int j = 0 ; j < m ; j ++ ){ //因为总共m条边,所以遍历m次
Node edg = edgs[j]; //每一条边的结构体
int a = edg.a;
int b = edg.b;
int c = edg.c;
dist[b] = Math.min(dist[b],back[a] + c); //用上面的点来更新后面的点
}
}
//这里为什么是max/2呢?
//因为到不了最后的n点,然后存在负权边能够到达n,将n的值更新了之后,变得比max小,防止出现这种情况
if(dist[n] > max / 2) System.out.println("impossible");
else System.out.println(dist[n]);
}
public static void main(String[] args)throws IOException{
BufferedReader re = new BufferedReader(new InputStreamReader(System.in));
String[] str = re.readLine().split(" ");
n = Integer.parseInt(str[0]);
m = Integer.parseInt(str[1]);
k = Integer.parseInt(str[2]);
for(int i = 0 ; i < m ; i ++){
String[] s = re.readLine().split(" ");
int a = Integer.parseInt(s[0]);
int b = Integer.parseInt(s[1]);
int c = Integer.parseInt(s[2]);
edgs[i] = new Node(a,b,c);
}
bellman_ford();
}
}
//创建一个构造体类
class Node{
int a,b,c;
public Node(int a,int b,int c){
this.a = a;
this.b = b;
this.c = c;
}
}
9. spfa 算法( 往回走 )
1. spfa求最短路 ✔12.24
原题链接
做题总结:
- 和宽搜差不多,只是可能会 返回走(但距离值更新了,就把这个节点入队列再处理一次)
import java.util.*;
public class Main{
static int N = 100010,n,m,hh,tt,idx,INF = 0x3f3f3f3f;
static int[] h = new int[N],e = new int[N],ne = new int[N],w = new int[N];
static int[] q = new int[N],dist = new int[N];
static boolean[] st = new boolean[N];
public static void add(int a,int b,int c){
e[idx] = b;
w[idx] = c;
ne[idx] = h[a];
h[a] = idx++;
}
public static void spfa(){
hh = 0 ; tt =-1;
Arrays.fill(dist,INF); //将dist一开始全部赋值成0x3f3f3f3f
dist[1] = 0; //然后一开始的点距离是0
q[++tt] = 1; //然后将第一个点插入到队列中
st[1] = true;//标记第一个队列中有这个点
while(hh <= tt){
int t = q[hh ++ ]; //然后将队头弹出
st[t] = false; //这里就将这个点在队列中取消标记
for(int i = h[t]; i != -1 ; i = ne[i]){ //遍历所有的点
int j = e[i];
//如果后面的数比前面的数加t-j之间的位权的和要大,就说明应该更新一下最短距离了
if(dist[j] > dist[t] + w[i]){
dist[j] = dist[t] + w[i];
//然后判断一下是不是队列中有这个点
if(!st[j]){
//没有就将这个点插入队列
q[++tt] = j;
//标记对列中有这个点
st[j] = true;
}
}
}
}
//spfa只会更新所有能从起点走到的点,所以如果无解,那么起点就走不到终点,那么终点的距离就是0x3f3f3f3f。
if(dist[n] == INF) System.out.println("impossible");
else System.out.println(dist[n]);
}
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
m = scan.nextInt();
Arrays.fill(h,-1);
while(m -- > 0){
int a = scan.nextInt();
int b = scan.nextInt();
int c = scan.nextInt();
add(a,b,c);
}
spfa();
}
}
10. spfa判断负权回路
原题链接
- 什么是负环

图1中:2 到 3 到 4 到 2 路径长度为 -10
图2中:2 到 3 到 4 到 2 路径长度为 10
图1才叫负环
图2不是负环
-
出现负环会怎么样
但出现负环的时候,如果我们要去求1到n的最短路,那么过程中,一定会在这个负环中一直转圈,导致路程可以变为负无穷 -
怎么判断图中是否有负环?
综上,我们就采取求最小路径的方式(但是本题不是求最短路),当我们求最短路径的过程中,发现有一段路径重复走,那么就说明一定出现了负环
问题来了:怎么判断某段路径在重复走
我们想,1到n号点 最多才可能走了n-1条边
如果我们发现 到某点时 已经走了 大于等于n条边,那么一定就是有负环了
由于我们不知道 1 到 x点最多可能有多少条边,但一定不会超过 n - 1 条边,所以我们就都用 大于等于n条边去判断
例题 spfa判断负环 ✔12.26
原题链接
import java.util.*;
public class Main{
static int N = 2010,M = 10010,n,m,idx;
static int[] h = new int[N],e = new int[M],ne = new int[M],w = new int[M];
static int[] cnt = new int[N]; //存多少边
static int[] dist = new int[N];//存点到起点的距离
static boolean[] st = new boolean[N];//判断队列中是不是有这个数
public static void add(int a,int b,int c){
e[idx] = b;
w[idx] = c;
ne[idx] = h[a];
h[a] = idx++;
}
public static boolean spfa(){
Queue<Integer> queue = new LinkedList<>();
//Arrays.fill(dist,0x3f3f3f3f);
//可能起点到不了负环,所以将所有的点都加入到对列中去
for(int i = 1 ; i <= n ; i++ ){
queue.offer(i);
st[i] = true;//然后标记所有的点
}
while(!queue.isEmpty()){
int t = queue.poll(); //然后将拿出队头
st[t] = false; //然后标记已经不在队列中
for(int i = h[t] ; i != -1 ; i= ne[i]){ //遍历所有的点
int j = e[i];
//如果j到起点的距离 > 上个点t到起点的距离 + t到j的距离,那么就更新dist[j]
if(dist[j] > dist[t] + w[i]){
dist[j] = dist[t] + w[i];
cnt[j] = cnt[t] + 1; // 每一个次更新就将边加上1
//如果边大于n点数,n个点最多只有n-1条边,如果>= n的话,就至少有一个点出现了两次,则说明出线负环
if(cnt[j] >= n) return true;
//然后判断对列中有没有点j,有则插并标记,无则不插
if(!st[j]){
queue.offer(j);
st[j] = true;
}
}
}
}
return false;
}
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
m = scan.nextInt();
Arrays.fill(h,-1);
while(m -- > 0){
int a = scan.nextInt();
int b = scan.nextInt();
int c = scan.nextInt();
add(a,b,c);
}
if(spfa()) System.out.println("Yes");
else System.out.println("No");
}
}
刷题总结
- e,ne,h,idx 用于存储边,所以数值应该与边一样多
- 把所有点都入队列,防止不是连通图
- dist里存储多少都可以,因为我们只需判断负权回路
- 当一个点所走的路径长度大于n,那么就一定有负边,因为最多就是n正常的话。
- 一定要有st数组,判断是否再走这个点
11. floyd算法( 两两之间最短距离 )

1. Floyd求最短路 ✔12.26
原题链接
做题总结
- 用二维数组存储更方便
- 读入存储的时候,读取最小值,并且到自身值为0
- Floyd
import java.util.*;
public class Main{
static int N = 210,n,m,k,INF = 0x3f3f3f3f;
static int[][] g = new int[N][N];
/***floyd算法只需要三重循环就可以解决问题,hh《很简单》
* g[i,j,k] = min(g[i,j,k-1],g[i,k,k-1]+g[k,j,k-1]);
* 原状态是:f[i, j, k]表示从i走到j的路径上除了i, j以外不包含点k的所有路径的最短距离。
* 那么f[i, j, k] = min(f[i, j, k - 1), f[i, k, k - 1] + f[k, j, k - 1]。
* 因此在计算第k层的f[i, j]的时候必须先将第k - 1层的所有状态计算出来,所以需要把k放在最外层。
*
* 这里其实就是将所有k的可能性已经·存好,等待你输入就OK了
***/
public static void floyd(){
for(int k = 1 ; k <= n ; k ++ ){
for(int i = 1 ; i <= n ; i ++ ){
for(int j = 1 ; j <= n ; j ++ ){
g[i][j] = Math.min(g[i][j],g[i][k] + g[k][j]);
}
}
}
}
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
m = scan.nextInt();
k = scan.nextInt();
for(int i = 1 ; i <= n ; i ++ ){
for(int j = 1 ; j <= n ; j ++ ){
if(i == j) g[i][j] = 0; //可能存在询问自身到自身的距离,所以需要存0
else g[i][j] = INF; //然后其他都可以存成INF最大值
}
}
while(m -- > 0 ){
int a = scan.nextInt();
int b = scan.nextInt();
int c = scan.nextInt();
g[a][b] = Math.min(g[a][b],c); //这里可能存在重边,取最小的边
}
floyd();
while(k -- > 0){
int x = scan.nextInt();
int y = scan.nextInt();
int t = g[x][y];
//这里可能最后到不了目标点,但是可能路径上面存在负权边,然后将目标点更新了,所以不是到底== INF
if(t > INF / 2) System.out.println("impossible");
else System.out.println(t);
}
}
}
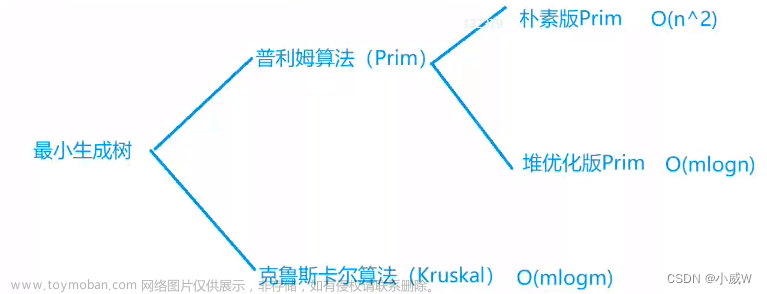
12. 朴素版prim算法
1. Prim算法求最小生成树
1. 有向无向
2. 当t选出来,cnt才+d[t]
原题链接
做题总结
1. 和dijk算法差不多 只是 dist数组存储的是 到联通块的距离
import java.util.*;
import java.io.*;
public class Main{
static int N = 510,M = 100010,INF = 0x3f3f3f3f;
static int n, m;
static int[][] g = new int[N][N];
static int[] dist = new int[N];
static boolean[] st = new boolean[N];
public static int prim(){
Arrays.fill(dist,INF);
int res = 0;
for (int i = 0 ; i < n ; i ++ ){
int t = -1;
for (int j = 1 ; j <= n ; j ++ )
if (!st[j] && (t == -1 || dist[j] < dist[t]))
t = j;
st[t] = true;
if (i != 0 && dist[t] == INF) return INF;
if (i != 0) res += dist[t];
for (int j = 1 ; j <= n ; j ++ )
dist[j] = Math.min(dist[j],g[t][j]);
}
return res;
}
public static void main(String[] args)throws IOException{
BufferedReader bf = new BufferedReader(new InputStreamReader(System.in));
String[] s1 = bf.readLine().split(" ");
n = Integer.parseInt(s1[0]);
m = Integer.parseInt(s1[1]);
for (int i = 0 ; i < N ; i ++ ) Arrays.fill(g[i],INF);
while (m -- > 0){
String[] s2 = bf.readLine().split(" ");
int a = Integer.parseInt(s2[0]);
int b = Integer.parseInt(s2[1]);
int c = Integer.parseInt(s2[2]);
g[a][b] = g[b][a] = Math.min(g[a][b],c);
}
int t = prim();
if (t == INF) System.out.println("impossible");
else System.out.println(t);
}
}
13. Kruskal算法

1. Kruskal算法求最小生成树( 利用并查集 )
只需sum++ 就可以知道一共用了几个并查集
原题链接
原题链接

import java.util.*;
public class Main{
static int N = 200010,n,m,w,INF = 0x3f3f3f3f;
static Edgs[] edgs = new Edgs[N];//创建一个结构体
static int[] p = new int[N];//集合
//并查集模板,所有的集合在过程中全部指向根节点
public static int find(int x){
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
public static void kruskal(){
Arrays.sort(edgs,0,m); //将结构体中的权重数据从小到大排序好
int res = 0;//所有权重之和
int cnt = 0;//加入集合的边数之和
//枚举所有的边
for(int i = 0 ; i < m ; i ++ ){
int a = edgs[i].a;
int b = edgs[i].b;
int w = edgs[i].w;
//判断一下a和b是不是在同一个集合中,不在集合中执行以下操作
a = find(a);b = find(b);
if(a != b){
p[a] = b; //将两个集合合并
res += w;//res增加权重
cnt ++;//边数加1
}
}
//因为有n个点,所以有n-1条边,所以如果小于n-1就是存在不连通的边,所以输出impossible,否则输出权重之和res
if(cnt < n - 1) System.out.println("impossible");
else System.out.println(res);
}
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
m = scan.nextInt();
for(int i = 1 ; i<= n ; i ++ ) p[i] = i;
for(int i = 0 ; i < m ; i ++ ){
int a = scan.nextInt();
int b = scan.nextInt();
int w = scan.nextInt();
edgs[i] = new Edgs(a,b,w);
}
kruskal();
}
}
class Edgs implements Comparable<Edgs>{
int a,b,w;
public Edgs(int a,int b,int w){
this.a = a;
this.b = b;
this.w = w;
}
public int compareTo(Edgs o){
return Integer.compare(w,o.w);
}
}
14. 染色法判别二分图

染色法判定二分图 ✔ 12.28
算法思路 + 做题总结
算法思路
- 通过dfs 一个染1 另一个染2(通过3-c)
- dfs需要有返回值。所以当 下一个返回来的是false,那么就返回false
所以一个dfs中,通过判断有一个return false,并且还有一个根据下一个的return 再return false
做题总结
- 无向图 需要开辟 2倍
原题链接
原题链接
import java.util.*;
public class Main{
static int N = 100010,M = N*2,n,m,idx;
static int[] h = new int[N],e = new int[M],ne = new int[M];
static int[] color = new int[N];
public static void add(int a,int b){
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
public static boolean dfs(int u,int c){
color[u] = c; //首先将点u染色成c
//然后遍历一下该点的所有边、
for(int i = h[u]; i != -1; i = ne[i]){
int j = e[i];
//如果该点还没有染色
if(color[j] == 0){
//那就将该点进行染色,3-c是因为我们是将染色成1和2,如果是1,那就将对应的染成2,就用3来减法得出
if(!dfs(j,3-c)) return false; //如果染完色之后返回false,那就说明里面含有奇数环,那就返回false
}
//如果该点已经染过颜色吗,然后点的颜色跟我c的颜色是一样的,那就说明存在奇数环,返回false
else if(color[j] == c) return false;
}
//最后如果很顺利的染完色,那就说明没有奇数环,那就返回true;
return true;
}
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
m = scan.nextInt();
Arrays.fill(h,-1);
while(m -- > 0){
int a = scan.nextInt();
int b = scan.nextInt();
add(a,b);add(b,a);//因为是无向边,所以双方指向双方的两条边
}
boolean flag = true;
for(int i = 1 ; i <= n ; i ++ ){
//如果该点还没有染色
if(color[i] == 0){
//那就进行染色操作,第一个点可以自行定义1或者2,表示黑白
if(!dfs(i,1)){
flag = false; //如果返回了false,说明有奇数环就将结束,输出No,否则输出Yes
break;
}
}
}
if(flag) System.out.println("Yes");
else System.out.println("No");
}
}
15. 匈牙利算法
二分图的最大匹配 ✔12.29
每次遍历的点 都重新定义确定的女朋友
原题链接文章来源地址https://www.toymoban.com/news/detail-743418.html
import java.util.*;
public class Main{
static int N = 510,M = 100010,n1,n2,m,idx;
static int[] h = new int[N],e = new int[M],ne = new int[M];
static int[] match = new int[M];
static boolean[] st = new boolean[N];
public static void add(int a,int b){
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
public static boolean find(int x){
//每一次遍历一遍传进来的左边集合x对应的右边集合中的点
for(int i = h[x]; i != -1; i = ne[i]){
int j = e[i];
// 判断这个点是不是已经用过了,没用过继续
if(!st[j]){
//这里st的作用大致就是递归时候起到判重的作用,因为下一位男生遍历时候一开始都会将st初始化为false
//然后将这个点标记为有了,然后如果刚好标记之后这个位置的女生已经被上一个男生约定俗成了,
//就递归看看这个男生是不是还有其他可以喜欢的女生,这个时候判重的作用就体现了,因为在这个过程中
//st已经被true标记了,所以上一个男生重新遍历时候遍历到这个女生就知道要让给下一个男生,所以找到
//自己的其他中意的女生,然后将自己与另外以为女生绑定,如果没有其他喜欢的女生,就返回flase,
//然后下一个男生就是单生,或者看看自己还有没有其他喜欢的女生,以此类推,得出最完美结果!!!
st[j] = true;
if(match[j] == 0 || find(match[j])){
match[j] = x; //match是表示女生对应的男生是谁
return true;
}
}
}
return false;
}
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
n1 = scan.nextInt();
n2 = scan.nextInt();
m = scan.nextInt();
Arrays.fill(h,-1);
while(m -- > 0){
int a = scan.nextInt();
int b = scan.nextInt();
add(a,b);
}
//统计最大匹配
int res = 0;
//遍历一下所有左半边集合的点
for(int i = 1 ; i <= n1 ; i ++ ){
//每一次模拟都要将st数组清空,这个判断重复的点,match是物有所主了
//st数组用来保证本次匹配过程中,右边集合中的每个点只被遍历一次,防止死循环。
//match存的是右边集合中的每个点当前匹配的点是哪个,但就算某个点当前已经匹配了某个点,
//也有可能被再次遍历,所以不能起到判重的作用。
Arrays.fill(st,false);
if(find(i)) res ++ ;
}
System.out.println(res);
}
}
到了这里,关于✔ ★ 算法基础笔记(Acwing)(三)—— 搜索与图论(17道题)【java版本】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!