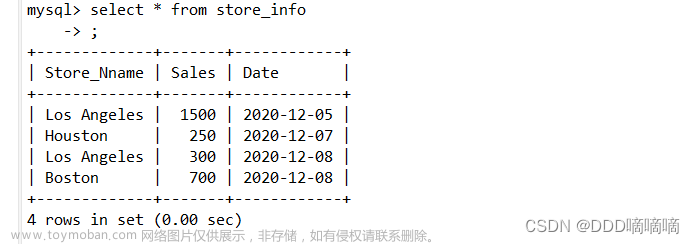
插入数据
insert
我们需要一次性往数据库表中插入多条记录,可以从以下三个方面进行优化。
- 批量插入数据
一条insert语句插入多个数据,但要注意,每个insert语句最好插入500-1000行数据,就得重新写另一条insert语句
Insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');- 手动控制事务
我们可以手动控制事务,在多条insert语句之间收起开启和提交事务,防止一次insert之后就提交事务浪费性能
start transaction;
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
insert into tb_test values(4,'Tom'),(5,'Cat'),(6,'Jerry');
insert into tb_test values(7,'Tom'),(8,'Cat'),(9,'Jerry');
commit;- 主键顺序插入,性能要高于乱序插入
主键乱序插入 : 8 1 9 21 88 2 4 15 89 5 7 3
主键顺序插入 : 1 2 3 4 5 7 8 9 15 21 88 89大批量插入数据
如果一次性需要插入大批量数据(比如: 几百万的记录),使用insert语句插入性能较低,此时可以使 用MySQL数据库提供的load指令进行插入。操作如下

可以执行如下指令,将数据脚本文件中的数据加载到表结构中:
-- 客户端连接服务端时,加上参数 -–local-infile
mysql –-local-infile -u root -p
-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
-- 执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/sql1.log' into table tb_user fields
terminated by ',' lines terminated by '\n' ;
主键优化
数据组织方式
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表 (index organized table IOT)。

行数据,都是存储在聚集索引的叶子节点上的。在InnoDB引擎中,数据行是记录在逻辑结构 page 页中的,而每一个页的大小是固定的,默认16K。 那也就意味着, 一个页中所存储的行也是有限的,如果插入的数据行row在该页存储不小,将会存储到下一个页中,页与页之间会通过指针连接。

主键顺序插入效果
- 从磁盘中申请页, 主键顺序插入

2. 第一个页没有满,继续往第一页插入

3.当第一个也写满之后,再写入第二个页,页与页之间会通过指针连接

4.当第二页写满了,再往第三页写入

主键乱序插入效果
页分裂
假如1#,2#页都已经写满了,存放了如图所示的数据
 此时再插入id为50的记录,因为要维持主键在内存的顺序,应该插入在47之后,47所在的页所剩的内存并不足以放下50这条记录,此时会开辟一个新的页
此时再插入id为50的记录,因为要维持主键在内存的顺序,应该插入在47之后,47所在的页所剩的内存并不足以放下50这条记录,此时会开辟一个新的页
 但是并不会直接将50存入3#页,而是会将1#页后一半的数据,移动到3#页,然后在3#页,插入50。
但是并不会直接将50存入3#页,而是会将1#页后一半的数据,移动到3#页,然后在3#页,插入50。

移动数据,并插入id为50的数据之后,那么此时,这三个页之间的数据顺序是有问题的。 1#的下一个 页,应该是3#, 3#的下一个页是2#。 所以,此时,需要重新设置链表指针。

页合并
目前表中已有数据的索引结构(叶子节点)如下:

当我们对已有数据进行删除时,具体的效果如下: 当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用。跟操作系统删除磁盘空间是类似的,只是逻辑删除,允许其它程序对该空间的数据进行覆盖。
在我们删除记录达到MERGE_THRESHOLD(默认为页的50%,可自己设置),InnoDB会开始寻找最靠近的页(前 或后)看看是否可以将两个页合并以优化空间使用。



删除数据,并将页合并之后,再次插入新的数据21,则直接插入3#页

主键设计原则
- 满足业务需求的情况下,尽量降低主键的长度。
- 插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键。
- 尽量不要使用UUID做主键或者是其他自然主键,如身份证号。
- 业务操作时,避免对主键的修改。
order by优化
MySQL的排序,有两种方式:
Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
Using index : 通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要 额外排序,操作效率高。
对于以上的两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index。
执行排序SQL,由于 age, phone 都没有索引,所以此时再排序时,出现Using filesort, 排序性能较低

那我们可以根据我们的业务,如果我们总是需要根据这两个字段来order by排序,那我们可以完全可以为phone和age建立联合索引
create index idx_user_age_phone_aa on tb_user(age,phone);建立索引之后就优化为Using index

这时候如果倒序查,也出现Using index, 但是此时Extra中出现了 Backward index scan,这个代表反向扫描索引,因为在MySQL中我们创建的索引,默认索引的叶子节点是从小到大排序的,而此时我们查询排序 时,是从大到小,所以,在扫描时,就是反向扫描,就会出现 Backward index scan。 在 MySQL8版本中,支持降序索引,我们也可以创建降序索引。

这时候我们需要建立倒序索引,就可优化成Using index,只要我们的排序顺序有对应的索引顺序,就可优化成Using index
优化原则
A. 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
B. 尽量使用覆盖索引。
C. 多字段排序, 一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)。
D. 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小 sort_buffer_size(默认256k)。
group by优化
没有索引的情况,进行分组,可以看见用到了临时表,性能较差

我们在针对于 profession , age, status 创建一个联合索引。

再执行前面相同的SQL查看执行计划。已经优化成using index,如果是单单根据age分组,最后还是会走临时表,group by也符合最左前缀法则

在分组操作中,我们需要通过以下两点进行优化,以提升性能:
A. 在分组操作时,可以通过索引来提高效率。
B. 分组操作时,索引的使用也是满足最左前缀法则的。
limit优化

通过测试我们会看到,越往后,分页查询效率越低,这就是分页查询的问题所在。因为,当在进行分页查询时,如果执行 limit 2000000,10 ,此时需要MySQL排序前2000010 记录,仅仅返回 2000000 - 2000010 的记录,其他记录丢弃,查询排序的代价非常大。
一般分页查询时,通过创建覆盖索引能够比较好地提高性能,也可以通过覆盖索引加子查询形式进行优化。我们也可以通过limit来查询id,由于id是主键索引,效率较高,通过子查询的形式作为临时表,返回排序好的id表,来进行多表联查,总的查询也是走的id索引,性能较高
count优化
概述
MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高; 但是如果是带条件的 count,MyISAM 也慢。InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。这样子效率低
主要的优化思路:
自己计数,可以借助于redis这样的数据库进行,redis本身就有自增长的键,可以满足这一业务,但是如果是带条件的count又比较麻烦了,可以说这一问题还是比较麻烦的
count用法
按照效率排序的话, count( 字段 ) < count( 主键 id) < count(1) ≈ count(*) ,所以 尽量使用 count(*)。
|
count
用
法
|
含义
|
|---|---|
|
count(
主键)
|
InnoDB
引擎会遍历整张表,把每一行的 主键
id
值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(
主键不可能为
null)
|
|
count(
字 段)
|
没有not null 约束
: InnoDB
引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null
,不为
null
,计数累加。
有not null 约束
:
InnoDB
引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加。
|
|
count(
数
字
)
|
InnoDB
引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字
“1” 进去,直接按行进行累加。
|
|
count(*)
|
InnoDB
引擎
并不会把全部字段取出来
,而是专门做了优化,不取值,服务层直接按行进行累加。
|
update优化
当我们执行此句update语句时,锁住的是这一行数据。
update course set name = 'javaEE' where id = 1 ;
update course set name = 'SpringBoot' where name = 'PHP' ;
原因是文章来源:https://www.toymoban.com/news/detail-743459.html
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁 ,并且该索引不能失效,否则会从行锁 升级为表锁 。我们进行dml操作时,尽量根据索引为查找条件,避免升级成表锁,影响并发文章来源地址https://www.toymoban.com/news/detail-743459.html
到了这里,关于Mysql进阶-SQL优化篇的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!