背景
由于是公司项目,所以不方便给出代码或者视频,只能列一些自己画的流程图。

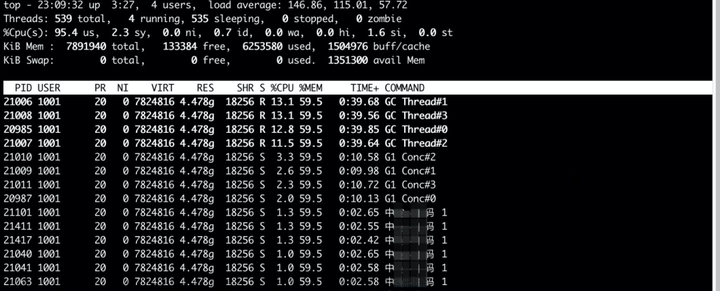
大致情况如上,前端有7个显示区。在对其进行滚动翻页的时候,存在以下问题:
1. 连续滚轮翻页,每次所有显示区刷新完,进行下一次翻页用时较久。(说人话就是,平均耗时翻页时间长)
2. 连续滚轮翻页,会出现一下子翻不动,然后连续刷新很多层的情况。且有的显示区更新快,有的层更新更新很慢。
分析
通过分析代码,调查log发现,翻页切换平均耗时在600ms。其主要的业务逻辑如下:
1.前端线程发送同步翻页命令给后端
2.后端进行处理,共7个显示区。前三个每个耗时30ms左右,后4个业务处理平均需要100ms。在后端处理过程中,已完成的场景数据,已经异步发送给前端。
3.前端等到后端处理完数据,根据接收数据,进行前端绘制,耗时110ms左右。

问题
主要问题有三个:
1.后端处理逻辑耗时太长了,特别是后4个场景。
2.前端等到后端逻辑处理完,才可以UI渲染,中间白白等待,耗时过长
3.在前端连续翻页情况下,有可能出现,第一次翻页的场景还没渲染完(只渲染了几个区域,或者一个都没有),就开始发送下一次渲染。造成“卡很久,然后一下次渲染好几帧的现象”。
解决
优化有3点:
1.以空间换时间。把耗时的即时计算操作,提前计算好,存储在内存中。那么在翻页过程中,就只是拷贝数据。
2.将图像刷新从同步改成异步。
2.1前端发送命令变成异步(这里最初同步是有一些业务需求,需要改造)
2.2我们的后端框架的刷新逻辑由两部分组成:数据序列化+发送。如果采用同步,后面4个场景的序列化的总时间,大概需要200ms。如下图所示。如果采用异步,那前端阻塞的时间,就几乎可以忽略不急

3.同步机制
前两点优化以后,翻页速度非常快。主要耗时只在后端序列化+发送数据+前端处理,可以达到200ms左右一次翻页。但存在异步刷新的问题。具体情况如下:

1.第一次翻页后,后端发送给前端数据,前端还只收到前两个场景的数据,并渲染。
2.前端收到翻页指令,接着发送翻页。后端发送7个场景,因为前几个场景,数据少,很快又发到了前端。
3.前端渲染第二次翻页的前几个数据
4.前端渲染第一次和第二次的剩余数据。
解决:文章来源:https://www.toymoban.com/news/detail-743819.html
后端在收到翻页指令以后,先等待自己上一次所有场景都刷新完,再接着序列化、发送。这样前端数据就能最大程度的进行渲染了,不会出现错位。
总结
最后的流程图如下,从最初600ms左右延迟的卡顿翻页,如今变成200ms左右的稳定翻页,优化效果非常不错。 文章来源地址https://www.toymoban.com/news/detail-743819.html
文章来源地址https://www.toymoban.com/news/detail-743819.html
到了这里,关于记一次翻页性能优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!