目录
一、Doris简介
一)概述
二)使用场景
三)架构
二、Doris安装部署
一)安装要求
2.1.1 Linux操作系统
2.1.2 软件需求
2.1.3 开发测试环境
2.1.4 生产环境
2.1.5 内部端口使用说明
二)部署
2.2.1 操作系统
2.2.2 Doris安装包
2.2.3 解压安装包
2.2.4 配置FE
2.2.5 配置BE
三、Doris数据表设计
一)基本概念
3.1.1 Row & Column
3.1.2 Tablet & Partition
3.1.3 ENGINE(引擎)
二)字段类型
三)数据模型
3.3.1 Aggregate模型
3.3.2 Unique模型
3.3.3 Duplicate模型
四)分区和分桶
3.4.1 分区(partiton)
3.4.2 分桶(Bucket)
3.4.3 复合分区与单分区
3.4.4 多列分区
3.4.5 PROPERTIES
3.4.6 动态分区
五)Rollup & 物化视图
3.5.1 Rollup(上卷)
3.5.2 物化视图
四、Flink读写Doris
一)准备工作
二)流的方式读写 Doris
三)SQL的方式读写Doris
一、Doris简介
一)概述
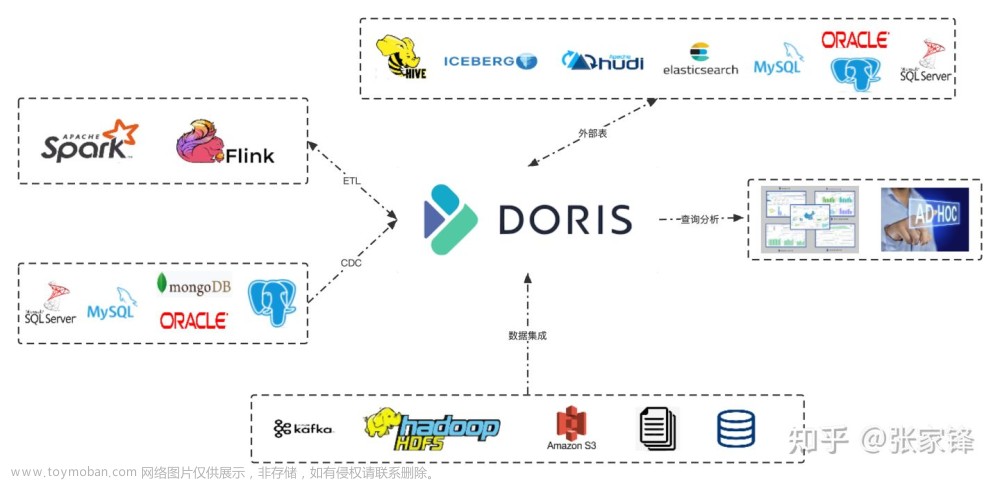
由百度大数据部研发(之前叫百度 Palo,2018年贡献到 Apache 社区后,更名为 Doris )
Apache Doris是一个现代化的MPP (Massively Parallel Processing,即大规模并行处理)分析型数据库产品,仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。
- 其架构简洁、易于运维、支持10PB以上的超大数据集、可以满足多种数据分许需求(固定历史报表、实时数据分析、交互式数据分析、探索式数据分析等)
二)使用场景

- 报表分析
实时看板 (Dashboards)
面向企业内部分析师和管理者的报表
面向用户或者客户的高并发报表分析(Customer Facing Analytics)
- 即席查询(Ad-hoc Query)——快
面向分析师的自助分析,查询模式不固定,要求较高的吞吐。
- 统一数仓构建
一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。
- 数据湖联邦查询
通过外表的方式联邦分析位于 Hive、Iceberg、Hudi中的数据,在避免数据拷贝的前提下,查询性能大幅提升。
三)架构

两类进程:
1)Frontend(FE)
主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。
主要角色:
Leader & Follower:用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务
Observer:用来扩展查询节点,同时起到元数据备份的作用。如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加 observer 的节点。observer 不参与任何的写入,只参与读取
2)Backend(BE)
主要负责数据存储、查询计划的执行。
数据的可靠性由 BE 保证,BE 会对整个数据存储多副本或者是三副本。
二、Doris安装部署
一)安装要求
2.1.1 Linux操作系统

2.1.2 软件需求

2.1.3 开发测试环境

2.1.4 生产环境

2.1.5 内部端口使用说明

二)部署
这里做测试使用,仅在单台机器上运行,不分发多节点
2.2.1 操作系统
需保证单台机器磁盘空间至少6G,df -h查询

1)设置系统最大打开文件句柄数
sudo vim /etc/security/limits.conf
添加(注意*不能漏)
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 655362)设置最大虚拟块的大小
sudo vim /etc/sysctl.conf
vm.max_map_count=20000003)配置完成后重启虚拟机
2.2.2 Doris安装包
下载路径:Download - Apache Doris

Windows x86_64架构 cpu(intel,amd),执行命令:
cat /proc/cpuinfo | grep avx2
有avx2字样 --> X64 (avx2)
无avx2 --> X64 (no avx2)
Apple --> ARM64
2.2.3 解压安装包
mkdir -p /opt/module/doris
1)安装FE,并修改目录名
tar -xvf apache-doris-fe-1.2.4.1-bin-arm.tar.xz -C /opt/module/doris
mv /opt/module/doris/apache-doris-fe-1.2.4.1-bin-arm /opt/module/doris/fe
2)安装BE,并修改目录名
tar -xvf apache-doris-be-1.2.4.1-bin-arm.tar.xz -C /opt/module/doris
mv /opt/module/doris/apache-doris-be-1.2.4.1-bin-arm /opt/module/doris/be
3)安装其他依赖(Java udf函数),并修改目录名
tar -xvf apache-doris-dependencies-1.2.4.1-bin-arm.tar.xz -C /opt/module/doris
mv /opt/module/doris/apache-doris-dependencies-1.2.4.1-bin-arm /opt/module/doris/dependencies
cp /opt/module/doris/dependencies/java-udf-jar-with-dependencies.jar /opt/module/doris/be/lib
2.2.4 配置FE
1)修改FE配置文件
vim /opt/module/doris/fe/conf/fe.conf
# web 页面访问端口
http_port = 7030
# 配置文件中指定元数据路径:默认在 fe 的根目录下,可以不配
# meta_dir = /opt/module/doris/fe/doris-meta
# 修改绑定 ip
priority_networks = 192.168.10.102/24这里的ip根据ifconfig查询

2)启动FE
前台启动(建议首次启动使用前台,便于查看运行信息,检测是否正常启动)
/opt/module/doris/fe/bin/start_fe.sh
或后台启动
/opt/module/doris/fe/bin/start_fe.sh --daemon
3)登录FE Web页面
http://hadoop102:7030
用户:root
首次登录未设置密码,无密码

前台运行报WARN拒绝连接可以暂时不用管
2.2.5 配置BE
1)修改BE配置文件
vim /opt/module/doris/be/conf/be.conf
webserver_port = 7040
# 不配置存储目录, 则会使用默认的存储目录
storage_root_path = /opt/module/doris/doris-storage1;/opt/module/doris/doris-storage2.SSD,10
priority_networks = 192.168.10.102/24
mem_limit=40%注意:存储路径需先创建
mkdir -p /opt/module/doris/doris-storage1
mkdir -p /opt/module/doris/doris-storage2.SSD
否则启动be时可能报错
WARNING: Logging before InitGoogleLogging() is written to STDERR
W1122 10:39:14.840314 15925 options.cpp:69] path can not be canonicalized. may be not exist.
W1122 10:39:14.840378 15925 options.cpp:148] failed to parse store path /opt/module/doris/dor
W1122 10:39:14.840394 15925 options.cpp:69] path can not be canonicalized. may be not exist.
W1122 10:39:14.840399 15925 options.cpp:148] failed to parse store path /opt/module/doris/dor
W1122 10:39:14.840402 15925 options.cpp:152] fail to parse storage_root_path config. value=[/
F1122 10:39:14.840407 15925 doris_main.cpp:345] parse config storage path failed, path=/opt/m
*** Check failure stack trace: ***
*** Query id: 0-0 ***
*** Aborted at 1700620754 (unix time) try "date -d @1700620754" if you are using GNU date ***
*** Current BE git commitID: Unknown ***
*** SIGABRT unkown detail explain (@0x3e800003e35) received by PID 15925 (TID 0x7f24f5e5fd40)
0# doris::signal::(anonymous namespace)::FailureSignalHandler(int, siginfo_t*, void*) at /ro
1# 0x00007F24F51922F0 in /lib64/libc.so.6
2# __GI_raise in /lib64/libc.so.6
3# __GI_abort in /lib64/libc.so.6
4# 0x000056120BA27EAD in /opt/module/doris/be/lib/doris_be
5# 0x000056120BA20EED in /opt/module/doris/be/lib/doris_be
6# google::LogMessage::SendToLog() in /opt/module/doris/be/lib/doris_be
7# google::LogMessage::Flush() in /opt/module/doris/be/lib/doris_be
8# google::LogMessageFatal::~LogMessageFatal() in /opt/module/doris/be/lib/doris_be
9# main at /root/doris/be/src/service/doris_main.cpp:403
10# __libc_start_main in /lib64/libc.so.6
11# _start in /opt/module/doris/be/lib/doris_be
bin/start_be.sh: line 246: 15925 Aborted ${LIMIT:+${LIMIT}} "${DORIS_HOME}/li

2)在FE中添加BE节点
使用mysql-client连接到FE
mysql -hhadoop102 -P9030 -uroot

设置密码:
SET PASSWORD FOR 'root' = PASSWORD('000000');

添加BE节点:
ALTER SYSTEM ADD BACKEND "hadoop102:9050";
3)启动BE
前台启动(建议首次启动使用前台,便于查看运行信息,检测是否正常启动)
/opt/module/doris/be/bin/start_be.sh
或后台启动
/opt/module/doris/be/bin/start_be.sh --daemon
启动be后,fe前台无WARN
4)重新进入fe mysql-client,查看BE节点状态
mysql -h hadoop102 -P 9030 -uroot -p000000
SHOW PROC '/backends'\G

还可以在Navicat中查看
先创建连接

再新建查询


Alive为true表示该BE节点存活
三、Doris数据表设计
一)基本概念
3.1.1 Row & Column
在Doris中,数据都以关系表(Table)的形式进行逻辑上的描述
- Row:行,用户的一行数据
- Column:列,用于描述一行数据中不同的字段,可以分为Key、Value,分别对应维度列和指标列。
说明:
① AGGREGATE KEY数据模型中,所有没有指定聚合方式(SUM、REPLACE、MAX、MIN)的列视为Key列,其余则为Value列
② 列定义时,Key列必须在所有Value列之前,尽量选择整型(效率高),不同类型字段长度够用即可,所有列的总字节长度(包括Key和Value)不能超过100KB
3.1.2 Tablet & Partition
在Doris的存储引擎中,用户数据首先被划分成若干个分区(Partition),划分的规则通常是按照用户指定的分区列进行范围划分,比如按时间划分。
而在每个分区内,数据被进一步的按照Hash的方式分桶,分桶的规则是要找用户指定的分桶列的值进行Hash后分桶。
- Tablet:切片,每个分桶就是一个数据分片,也是数据划分的最小逻辑单元,独立存储,互相之间没有交集。同时也是数据移动、复制等操作的最小物理存储单元
- Partition:分区,可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个分区进行
3.1.3 ENGINE(引擎)
Doris支持的引擎:OLAP / MYSQL / BROKER / HIVE
说明:
① 默认olap,由Doris负责数据管理和存储
② 其他 ENGINE 类型,如 mysql、broker、es、hive等,本质上只是对外部其他数据库或系统中的表的映射,以保证 Doris 可以读取这些数据。而 Doris 本身并不创建、管理和存储任何非 olap ENGINE 类型的表和数据
二)字段类型
| TINYINT |
1字节 |
范围:-2^7 + 1 ~ 2^7 - 1 |
| SMALLINT |
2字节 |
范围:-2^15 + 1 ~ 2^15 - 1 |
| INT |
4字节 |
范围:-2^31 + 1 ~ 2^31 - 1 |
| BIGINT |
8字节 |
范围:-2^63 + 1 ~ 2^63 - 1 |
| LARGEINT |
16字节 |
范围:-2^127 + 1 ~ 2^127 - 1 |
| FLOAT |
4字节 |
支持科学计数法 |
| DOUBLE |
12字节 |
支持科学计数法 |
| DECIMAL[(precision, scale)] |
16字节 |
保证精度的小数类型。默认是 DECIMAL(10, 0) precision: 1 ~ 27 scale: 0 ~ 9 其中整数部分为 1 ~ 18,不支持科学计数法 |
| DATE |
3字节 |
范围:0000-01-01 ~ 9999-12-31 |
| DATETIME |
8字节 |
范围:0000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| CHAR[(length)] |
定长字符串。长度范围:1 ~ 255。默认为1 |
|
| VARCHAR[(length)] |
变长字符串。长度范围:1 ~ 65533 |
|
| BOOLEAN |
与TINYINT一样,0代表false,1代表true |
|
| HLL |
1~16385字节 |
hll列类型,不需要指定长度和默认值、长度根据数据的聚合 程度系统内控制,并且HLL列只能通过配套的hll_union_agg、Hll_cardinality、hll_hash进行查询或使用 |
| BITMAP |
bitmap列类型,不需要指定长度和默认值。表示整型的集合,元素最大支持到2^64 - 1 |
|
| STRING |
变长字符串,0.15版本支持,最大支持2147483643 字节(2GB-4),长度还受be 配置`string_type_soft_limit`, 实际能存储的最大长度取两者最小值。只能用在value 列,不能用在 key 列和分区、分桶列 |
三)数据模型
准备数据库:
create database test_db;
use test_db;
建表语法:
HELP CREATE TABLE; --建表帮助命令 查看详细参数 查看列的基本类型
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...]
[, index_definition1[, index_definition12,]])
[ENGINE = [olap|mysql|broker|hive|es]]
[key_desc]
[COMMENT "table comment"];
[partition_desc]
[distribution_desc]
[rollup_index]
[PROPERTIES ("key"="value", ...)]
[BROKER PROPERTIES ("key"="value", ...)];3.3.1 Aggregate模型
1)数据表模式
| ColumnName |
Type |
AggregationType |
Comment |
| user_id |
LARGEINT |
用户id |
|
| date |
DATE |
数据灌入日期 |
|
| city |
VARCHAR(20) |
用户所在城市 |
|
| age |
SMALLINT |
用户年龄 |
|
| sex |
TINYINT |
用户性别 |
|
| last_visit_date |
DATETIME |
REPLACE |
用户最后一次访问时间 |
| cost |
BIGINT |
SUM |
用户总消费 |
| max_dwell_time |
INT |
MAX |
用户最大停留时间 |
| min_dwell_time |
INT |
MIN |
用户最小停留时间 |
2)转为建表语句
CREATE TABLE IF NOT EXISTS test_db.example_site_visit
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
properties(
"replication_num"="1"
);3)插入数据
insert into test_db.example_site_visit values\
(10000,'2017-10-01','北京',20,0,'2017-10-01 06:00:00' ,20,10,10),\
(10000,'2017-10-01','北京',20,0,'2017-10-01 07:00:00',15,2,2),\
(10001,'2017-10-01','北京',30,1,'2017-10-01 17:05:45',2,22,22),\
(10002,'2017-10-02','上海',20,1,'2017-10-02 12:59:12' ,200,5,5),\
(10003,'2017-10-02','广州',32,0,'2017-10-02 11:20:00',30,11,11),\
(10004,'2017-10-01','深圳',35,0,'2017-10-01 10:00:15',100,3,3),\
(10004,'2017-10-03','深圳',35,0,'2017-10-03 10:20:22',11,6,6);4)查询数据

插入7行数据,仅显示6条,user_id,date,city,age,sex相同的前两条数据被聚合计算
5)说明
① AggregationType (聚合类型)目前只有REPLACE/SUM/MIN/MAX四种
② 没有设置聚合类型的叫 key(维度列), 设置了聚合类型的叫 value(指标列),导入数据时会按照key对value使用其聚合类型进行聚合
③ 同一个导入批次中的数据,对于 REPLACE 这种聚合方式,替换顺序不做保证。而对于不同导入批次中的数据,可以保证,后一批次的数据会替换前一批次
④ 经过聚合,Doris 中最终只会存储聚合后的数据,明细数据会丢失,不能够再查询到聚合前的明细数据,想要保留明细数据不聚合, 保证每条数据的 多个key中有一个 不一样即可
3.3.2 Unique模型
key唯一(后面的数据覆盖前面的,保证幂等性),底层是aggregate中的replace
1)数据表模式
| ColumnName |
Type |
IsKey |
Comment |
| user_id |
BIGINT |
Yes |
用户id |
| username |
VARCHAR(50) |
Yes |
用户昵称 |
| city |
VARCHAR(20) |
No |
用户所在城市 |
| age |
SMALLINT |
No |
用户年龄 |
| sex |
TINYINT |
No |
用户性别 |
| phone |
LARGEINT |
No |
用户电话 |
| address |
VARCHAR(500) |
No |
用户住址 |
| register_time |
DATETIME |
No |
用户注册时间 |
2)转为建表语句(默认除了key都为replace)
CREATE TABLE IF NOT EXISTS test_db.user
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`phone` LARGEINT COMMENT "用户电话",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
properties(
"replication_num"="1"
)3)插入数据
insert into test_db.user values\
(10000,'wuyanzu','北京',18,0,12345678910,'北京朝阳区','2017-10-01 07:00:00'),\
(10000,'wuyanzu','北京',19,1,12345678910,'北京朝阳区','2017-10-01 08:00:00'),\
(10000,'zhangsan','北京',20,0,12345678910,'北京海淀区','2017-11-15 06:10:20');4)查询数据

插入3行数据,仅显示2条,user_id,usesr_name作为key,相同的key数据被后面的数据覆盖
5)说明
表结构等价于以下聚合模型
| ColumnName |
Type |
AggregationType |
Comment |
| user_id |
BIGINT |
用户id |
|
| username |
VARCHAR(50) |
用户昵称 |
|
| city |
VARCHAR(20) |
REPLACE |
用户所在城市 |
| age |
SMALLINT |
REPLACE |
用户年龄 |
| sex |
TINYINT |
REPLACE |
用户性别 |
| phone |
LARGEINT |
REPLACE |
用户电话 |
| address |
VARCHAR(500) |
REPLACE |
用户住址 |
| register_time |
DATETIME |
REPLACE |
用户注册时间 |
即 Unique 模型完全可以用聚合模型中的 REPLACE 方式替代,其内部的实现方式和数据存储方式也完全一样
3.3.3 Duplicate模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求
1)数据表模式
| ColumnName |
Type |
SortKey |
Comment |
| timestamp |
DATETIME |
Yes |
日志时间 |
| type |
INT |
Yes |
日志类型 |
| error_code |
INT |
Yes |
错误码 |
| error_msg |
VARCHAR(1024) |
No |
错误详细信息 |
| op_id |
BIGINT |
No |
负责人id |
| op_time |
DATETIME |
No |
处理时间 |
2)转为建表语句(默认除了key都为replace)
CREATE TABLE IF NOT EXISTS test_db.example_log
(
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
`type` INT NOT NULL COMMENT "日志类型",
`error_code` INT COMMENT "错误码",
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
`op_id` BIGINT COMMENT "负责人id",
`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`)
DISTRIBUTED BY HASH(`timestamp`) BUCKETS 10
properties(
"replication_num"="1"
);3)插入数据
insert into test_db.example_log values\
('2017-10-01 08:00:05',1,404,'not found page', 101, '2017-10-01 08:00:05'),\
('2017-10-01 08:00:05',1,404,'not found page', 101, '2017-10-01 08:00:05'),\
('2017-10-01 08:00:05',2,404,'not found page', 101, '2017-10-01 08:00:06'),\
('2017-10-01 08:00:06',2,404,'not found page', 101, '2017-10-01 08:00:07');4)查询数据

插入4行数据,显示4条,数据完全按照导入文件中的数据进行存储,不会有任何聚合
5)说明
① 即使两行数据完全相同,也都会保留
② 指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序
③ 适用于既没有聚合需求,又没有主键唯一性约束的原始数据的存储
四)分区和分桶
3.4.1 分区(partiton)
Doris支持两层的数据划分:
第一层是 Partition,支持 Range和List的划分方式
第二层是 Bucket(Tablet),仅支持Hash的划分方式
也可以仅使用一层分区,只支持Bucket划分
1)Range Partition(范围分区)
说明:
① 分区列通常为时间列 PARTITION BY RANGE(`date`),便于管理新旧数据
② 指定界限,生成一个左闭右开的区间
VALUES LESS THAN (...) 仅指定上界,系统会将前一个分区的上界作为该分区的下界
VALUES [...) 指定上下界
建表(以VALUES LESS THAN为例):
CREATE TABLE IF NOT EXISTS test_db.example_range_tb
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=OLAP
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "1",
"storage_cooldown_time" = "2024-01-01 12:00:00"
);建表完成后,会自动生成分区
show partitions from example_range_tb; -- 查看表的所有分区信息


分区为:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201703: [2017-03-01, 2017-04-01)
插入数据:
insert into test_db.example_range_tb values (10000,'2017-01-01','北京',20,0,'2017-01-01 06:00:00',20,10,10);、
insert into test_db.example_range_tb values (20000,'2017-11-01','北京',20,0,'2017-11-01 06:00:00',20,10,10);第一条数据会进入p201701分区,查看分区信息会发现改分区DataSize变大


第二条数据没有对应的分区则会报错

查询该表:

第一条数据成功被记录
增加一个分区:
alter table example_range_tb add partition p201705 values less than ('2017-06-01');查看分区信息发生变化:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201703: [2017-03-01, 2017-04-01)
p201705: [2017-04-01, 2017-06-01)

删除分区:
alter table example_range_tb drop partition p201703;
分区再次发生变化:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)

但注意,其他分区并不会变化范围,而是出现空洞(在p201702和p201705之间),如果数据插入改空洞范围则会丢失
说明:
① 分区的删除不会改变已存在分区的范围,删除分区可能出现空洞
② 通过 VALUES LESS THAN 语句增加分区时,分区的下界紧接上一个分区的上界
2) List Partition(列表分区)
分区列支持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值,只有当数据为目标枚举值之一才能进入分区
CREATE TABLE IF NOT EXISTS test_db.example_list_tb
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) NOT NULL COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
PARTITION BY LIST(`city`)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),
PARTITION `p_jp` VALUES IN ("Tokyo")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "1",
"storage_cooldown_time" = "2024-01-01 12:00:00"
); 分区为:
分区为:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_jp: ("Tokyo")
插入数据:
insert into test_db.example_list_tbl values (10000,'2017-01-01','Beijing',20,0,'2017-01-01 06:00:00',20,10,10);
insert into test_db.example_list_tbl values (20000,'2017-01-01','shenzhen',20,0,'2017-01-01 06:00:00',20,10,10);第一条数据进入p_cn分区,第二条数据报错
其他操作与range partition同理
3.4.2 分桶(Bucket)
建表时指定分桶:DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
说明:
① 如果使用了 Partition,则 DISTRIBUTED ... 语句描述的是数据在各个分区内的划分规则,如果不使用 Partition,则描述的是对整个表的数据的划分规则
② 分桶列可以是多列,但必须为 Key 列,可以与Partition的列相同或不同
③ 分桶的数量理论上没有上限
④ 分桶列的选择,是在查询吞吐和查询并发之间的一种权衡
如果选择多个分桶列,则数据分布更均匀。如果一个查询条件不包含所有分桶列的等值条件,那么该查询会触发所有分桶同时扫描,这样查询的吞吐会增加,单个查询的延迟随之降低。这个方式适合大吞吐低并发的查询场景。
如果仅选择一个或少数分桶列,则对应的点查询可以仅触发一个分桶扫描。此时,当多个点查询并发时,这些查询有较大的概率分别触发不同的分桶扫描,各个查询之间的IO影响较小(尤其当不同桶分布在不同磁盘上时),所以这种方式适合高并发的点查询场景。
3.4.3 复合分区与单分区
复合分区:分区和分桶
适用于有时间维度或类似带有有序值的维度、历史数据删除需求、解决数据倾斜问题
单分区:仅分桶(所有数据在一个分区, 数据只做 hash 分布)
3.4.4 多列分区
以range partition为例,指定 `date`(DATE 类型) 和 `id`(INT 类型) 作为分区列
PARTITION BY RANGE(`date`, `id`)
(
PARTITION `p201701_1000` VALUES LESS THAN ("2017-02-01", "1000"),
PARTITION `p201702_2000` VALUES LESS THAN ("2017-03-01", "2000"),
PARTITION `p201703_all` VALUES LESS THAN ("2017-04-01")
)得到分区结果:
p201701_1000: [(MIN_VALUE, MIN_VALUE), ("2017-02-01", "1000") )
p201702_2000: [("2017-02-01", "1000"), ("2017-03-01", "2000") )
p201703_all: [("2017-03-01", "2000"), ("2017-04-01", MIN_VALUE))
最后一个分区用户缺省只指定了 `date` 列的分区值, `id` 列的分区值会默认填充MIN_VALUE
插入数据时,分区列值会按照顺序依次比较,当第一列处于边界的时候,由第二列决定,最终得到对应的分区
数据 --> 分区
2017-01-01, 200 --> p201701_1000
2017-01-01, 2000 --> p201701_1000
2017-02-01, 100 --> p201701_1000
2017-02-01, 2000 --> p201702_2000
2017-02-15, 5000 --> p201702_2000
2017-03-01, 2000 --> p201703_all
2017-03-10, 1 --> p201703_all
2017-04-01, 1000 --> 无法导入
2017-05-01, 1000 --> 无法导入
list partition同理
3.4.5 PROPERTIES
1)replication_num 副本数
默认副本数为3,如果 BE 节点数量小于3,则需指定副本数小于等于 BE 节点数量
2)storage_medium 初始存储媒介
3)storage_cooldown_time 到期时间
例如:
"storage_medium" = "SSD",
"storage_cooldown_time" = "2020-11-20 00:00:00"
表示数据存放在 SSD 中,并且在 2020-11-20 00:00:00 到期后,会自动迁移到 HDD 存储上
3.4.6 动态分区
对表级别的分区实现生命周期管理(TTL),减少用户的使用负担,只支持Range Partition
可以在建表时设定动态分区的规则,FE启动一个后台线程,根据用户指定的规则创建或删除分区
建表时指定:
CREATE TABLE tbl1
(...)
PROPERTIES
(
"dynamic_partition.prop1" = "value1",
"dynamic_partition.prop2" = "value2",
...
)运行时修改:
ALTER TABLE tbl1 SET
(
"dynamic_partition.prop1" = "value1",
"dynamic_partition.prop2" = "value2",
...
)主要参数(以 dynamic_partition. 为前缀):
| dynamic_partition.enable |
是否开启动态分区特性,可指定true或false,默认为true 如果为 FALSE,则 Doris 会忽略该表的动态分区规则。 |
| dynamic_partition.time_unit |
动态分区调度的单位,可指定HOUR、DAY、WEEK、MONTH。 HOUR,后缀格式为 yyyyMMddHH,分区列数据类型不能为 DATE。 DAY,后缀格式为 yyyyMMdd。 WEEK,后缀格式为yyyy_ww。即当前日期属于这一年的第几周。 MONTH,后缀格式为 yyyyMM。 |
| dynamic_partition.time_zone |
动态分区的时区,如果不填写,则默认为当前机器的系统的时区 |
| dynamic_partition.start |
动态分区的起始偏移,为负数。根据 time_unit 属性的不同,以当天(星期/月)为基准,分区范围在此偏移之前的分区将会被删除。如果不填写默认值为Interger.Min_VALUE 即-2147483648,即不删除历史分区 |
| dynamic_partition.end |
动态分区的结束偏移,为正数。根据 time_unit 属性的不同,以当天(星期/月)为基准,提前创建对应范围的分区 |
| dynamic_partition.prefix |
动态创建的分区名前缀 |
| dynamic_partition.buckets |
动态创建的分区所对应分桶数量 |
| dynamic_partition.replication_num |
动态创建的分区所对应的副本数量,如果不填写,则默认为该表创建时指定的副本数量。 |
| dynamic_partition.start_day_of_week |
当 time_unit 为 WEEK 时,该参数用于指定每周的起始点。取值为 1 到 7。其中 1 表示周一,7 表示周日。默认为 1,即表示每周以周一为起始点 |
| dynamic_partition.start_day_of_month |
当 time_unit 为 MONTH 时,该参数用于指定每月的起始日期。取值为 1 到 28。其中 1 表示每月1号,28 表示每月28号。默认为 1,即表示每月以1号位起始点。暂不支持以29、30、31号为起始日,以避免因闰年或闰月带来的歧义 |
| dynamic_partition.create_history_partition |
默认为 false。当置为 true 时,Doris 会自动创建所有分区,当期望创建的分区个数大于 max_dynamic_partition_num 值时,操作将被禁止。当不指定 start 属性时,该参数不生效。 |
| dynamic_partition.hot_partition_num |
指定最新的多少个分区为热分区。对于热分区,系统会自动设置其 storage_medium 参数为SSD,并且设置 storage_cooldown_time。 hot_partition_num 是往前 n 天和未来所有分区 我们举例说明。假设今天是 2021-05-20,按天分区,动态分区的属性设置为:hot_partition_num=2, end=3, start=-3。则系统会自动创建以下分区,并且设置 storage_medium 和 storage_cooldown_time 参数: p20210517:["2021-05-17", "2021-05-18") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59 p20210518:["2021-05-18", "2021-05-19") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59 p20210519:["2021-05-19", "2021-05-20") storage_medium=SSD storage_cooldown_time=2021-05-21 00:00:00 p20210520:["2021-05-20", "2021-05-21") storage_medium=SSD storage_cooldown_time=2021-05-22 00:00:00 p20210521:["2021-05-21", "2021-05-22") storage_medium=SSD storage_cooldown_time=2021-05-23 00:00:00 p20210522:["2021-05-22", "2021-05-23") storage_medium=SSD storage_cooldown_time=2021-05-24 00:00:00 p20210523:["2021-05-23", "2021-05-24") storage_medium=SSD storage_cooldown_time=2021-05-25 00:00:00 |
| dynamic_partition.reserved_history_periods |
需要额外保留的历史分区的时间范围。当dynamic_partition.time_unit 设置为 "DAY/WEEK/MONTH" 时,需要以 [yyyy-MM-dd,yyyy-MM-dd],[...,...] 格式进行设置。当dynamic_partition.time_unit 设置为 "HOUR" 时,需要以 [yyyy-MM-dd HH:mm:ss,yyyy-MM-dd HH:mm:ss],[...,...] 的格式来进行设置。如果不设置,默认为 "NULL"。 我们举例说明。假设今天是 2021-09-06,按天分类,动态分区的属性设置为: time_unit="DAY", \ end=3, \ start=-3, \ reserved_history_periods="[2020-06-01,2020-06-20],[2020-10-31,2020-11-15]"。 则系统会自动保留: ["2020-06-01","2020-06-20"], ["2020-10-31","2020-11-15"] 或者 time_unit="HOUR", \ end=3, \ start=-3, \ reserved_history_periods="[2020-06-01 00:00:00,2020-06-01 03:00:00]". 则系统会自动保留: ["2020-06-01 00:00:00","2020-06-01 03:00:00"] 这两个时间段的分区。其中,reserved_history_periods 的每一个 [...,...] 是一对设置项,两者需要同时被设置,且第一个时间不能大于第二个时间``。 |
建表示例:
create table student_dynamic_partition1
(
id int,
time date,
name varchar(50),
age int
)
duplicate key(id,time)
PARTITION BY RANGE(time)()
distributed by hash(`id`)
PROPERTIES(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.history_partition_num" = "3", -- 删除该行则会向前创建7个分区
"dynamic_partition.start" = "-7", --与history_partition_num取小
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "10",
"replication_num" = "1"
);创建历史分区:
create_history_partition = true
今天的分区(1) + end(未来的分区) + 过去的分区(start 和 history-num 谁少听谁的)
例如:
假设今天是 2021-05-20,按天分区
动态分区的属性设置为:create_history_partition=true, end=3, start=-3, history_partition_num=1,则系统会自动创建以下分区:
p20210519、p20210520、p20210521、p20210522、p20210523
history_partition_num=5,其余属性与 1 中保持一直,则会自动创建:
p20210517、p20210518、p20210519、p20210520、p20210521、p20210522、p20210523
history_partition_num=-1 即不设置历史分区数量,其余属性与 1 中保持一致,则会自动创建:
p20210517、p20210518、p20210519、p20210520、p20210521、p20210522、p20210523
补充:动态分区表与手动分区表相互转换
对于一个表来说,动态分区和手动分区可以自由转换,但二者不能同时存在,有且只有一种状态
1)手动分区转换为动态分区
如果一个表在创建时未指定动态分区,可以通过ALTER TABLE在运行时修改动态分区相关属性来转化为动态分区,具体示例可以通过HELP ALTER TABLE查看。
注意:如果已设定dynamic_partition.start,分区范围在动态分区起始偏移之前的历史分区将会被删除
2)动态分区转换为手动分区
ALTER TABLE tbl_name SET ("dynamic_partition.enable" = "false")关闭动态分区功能后,Doris将不再自动管理分区,需要用户手动通过ALTER TABLE 的方式创建或删除分区
五)Rollup & 物化视图
3.5.1 Rollup(上卷)
在多维分析中是“上卷”的意思,将数据按某种指定的粒度进行进一步聚合(从细粒度到粗粒度)
在 Doris 中,将用户通过建表语句创建出来的表称为 Base 表,保存着按用户建表语句指定的方式存储的基础数据
在 Base 表之上,可以创建任意多个 ROLLUP 表,这些 ROLLUP 的数据是基于 Base 表产生的,并且在物理上是独立存储的
作用:在Base表的基础上,获得更粗粒度的聚合数据
1)Aggregate和Unique模型中的Rollup
alter table example_site_visit add rollup rollup_cost_userid(user_id,cost);可以通过explain查看执行计划,是否使用到了rollup
explain SELECT user_id, sum(cost) FROM example_site_visit GROUP BY user_id;
2)Duplicate模型中的Rollup
作为调整列顺序,以命中前缀索引的作用
说明:
① ROLLUP的根本作用是提高某些查询的效率,附属于Base表的一种辅助数据结构,其数据独立存储,更新与Base表同步
② 查询能否命中 ROLLUP 的一个必要条件(非充分条件)是,查询所涉及的所有列(包括 select list 和 where 中的查询条件列等)都存在于该 ROLLUP 的列中,否则,查询只能命中 Base 表。某些类型的查询(如 count(*))在任何条件下,都无法命中 ROLLUP
③ 可以通过DESC table_name ALL 显示Base表和所有已创建的ROLLUP

3.5.2 物化视图
物化视图是将预先计算(根据定义好的 SELECT 语句)好的数据集,存储在 Doris 中的一个特殊的表,相较于上卷,更为常用。既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询
适用于:
分析需求覆盖明细数据查询以及固定维度查询两方面
查询仅涉及表中的很小一部分列或行
查询包含一些耗时处理操作,比如:时间很久的聚合操作等
查询需要匹配不同前缀索引
优势:
对于经常重复使用的子查询,性能大幅提升
Doris自动维护物化视图的数据,保证与Base表的数据一致性
查询时,会自动匹配到最优物化视图,并直接从物化视图中读取数据
物化视图则在覆盖了 Rollup 的功能的同时,还能支持更丰富的聚合函数
创建原则:
从查询语句中抽象出,多个查询共有的分组和聚合方式作为物化视图的定义
不需要给所有维度组合都创建物化视图
示例:
1)创建一个Base表
create table sales_records(
record_id int,
seller_id int,
store_id int,
sale_date date,
sale_amt bigint
)
distributed by hash(record_id)
properties("replication_num" = "1");2)插入数据
insert into sales_records values(1,2,3,'2020-02-02',10);Base表要有数据才能创建物化视图
3)基于这个Base表的数据提交一个创建物化视图的任务
create materialized view store_amt as
select
store_id,
sum(sale_amt)
from sales_records
group by store_id;4)检查物化视图是否构建完成
SHOW ALTER TABLE MATERIALIZED VIEW FROM test_db; -- 查看库中所有物化视图
desc sales_records all; -- 查询某表的Base表及所有物化视图
5)检验当前查询是否匹配到了合适的物化视图
EXPLAIN SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;6)删除物化视图
语法:
DROP MATERIALIZED VIEW 物化视图名 on Base表名;
DROP MATERIALIZED VIEW store_amt on sales_records;

四、Flink读写Doris
Flink Doris Connector 可以支持通过 Flink 操作(读取、插入、修改、删除) Doris 中存储的数据
注意:修改和删除只支持在 Unique Key 模型上
官网:Apache Doris: Open-Source Real-Time Data Warehouse - Apache Doris
一)准备工作
1)建库建表
create database test;
use test;
CREATE TABLE table1
(
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, citycode, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");2)插入数据
insert into table1 values
(1,1,'jim',2),
(2,1,'grace',2),
(3,2,'tom',2),
(4,3,'bush',3),
(5,3,'helen',3);3)导入Doris连接器依赖
官网:Flink Doris Connector - Apache Doris
中文版:Flink Doris Connector - Apache Doris
<dependency>
<groupId>org.apache.doris</groupId>
<artifactId>flink-doris-connector-1.17</artifactId>
<version>1.4.0</version>
</dependency>二)流的方式读写 Doris
1)Source
官网模板:

使用:文章来源:https://www.toymoban.com/news/detail-743955.html
public class Doris_Read {
public static void main(String[] args) throws Exception {
//todo 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//todo 2.创建DorisSourceBuilder
DorisOptions dorisOptions = DorisOptions.builder()
.setFenodes("hadoop102:7030")
.setTableIdentifier("test_db.user")
.setUsername("root")
.setPassword("000000")
.build();
DorisSource<List<?>> dorisSource = DorisSourceBuilder.<List<?>>builder() //List<?> 表示不能添加数据,只读,可删改
.setDorisOptions(dorisOptions) //连接参数
.setDorisReadOptions(DorisReadOptions.builder().build())
.setDeserializer(new SimpleListDeserializationSchema())
.build();
//todo 3.读取数据
DataStreamSource<List<?>> listDataStreamSource = env.fromSource(dorisSource, WatermarkStrategy.noWatermarks(), "doris-source");
//todo 4.打印输出
listDataStreamSource.print();
//todo 5.启动任务
env.execute();
}
}
2)Sink
必须开启 checkpoint
① 写String数据,tsv默认分隔符\t
官方模板:

使用:

public class Doris_Write_String {
public static void main(String[] args) throws Exception {
//todo 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//修改并行度
env.setParallelism(1);
//todo 开启checkpoint 必须
env.enableCheckpointing(5000L);
//todo 2.从端口读取数据 1 1 a 1
DataStreamSource<String> socketTextStream = env.socketTextStream("hadoop102", 4781);
//todo 3.创建DorisSink
DorisOptions dorisOptions = DorisOptions.builder()
.setFenodes("hadoop102:7030")
.setTableIdentifier("test.table1")
.setUsername("root")
.setPassword("000000")
.build();
DorisSink<String> dorisSink = DorisSink.<String>builder()
.setDorisOptions(dorisOptions)
.setDorisReadOptions(DorisReadOptions.builder().build())
.setDorisExecutionOptions(DorisExecutionOptions.builder()
.setDeletable(false) //是否删除表
.disable2PC() //关闭两阶段提交
.setLabelPrefix("doris-") //事务前缀
.setBufferCount(1024) //批处理 最大buffer
.setCheckInterval(2) //校验时间间隔
.setMaxRetries(3) //最大重试次数
.build())
.setSerializer(new SimpleStringSerializer())
.build();
//todo 4.将数据写出
socketTextStream.sinkTo(dorisSink);
//todo 5.启动任务
env.execute();
}
}

② 写Json数据
官方模板:

使用:
public class Doris_Write_Json {
public static void main(String[] args) throws Exception {
//todo 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//修改并行度
env.setParallelism(1);
//todo 开启checkpoint 必须
env.enableCheckpointing(5000L);
//todo 2.从端口读取数据 {"siteid":2,"citycode":2,"username":"b","pv":1}
DataStreamSource<String> socketTextStream = env.socketTextStream("hadoop102", 4781);
//todo 3.创建DorisSink
DorisOptions dorisOptions = DorisOptions.builder()
.setFenodes("hadoop102:7030")
.setTableIdentifier("test.table1")
.setUsername("root")
.setPassword("000000")
.build();
Properties properties = new Properties();
properties.setProperty("format", "json");
properties.setProperty("read_json_by_line", "true");
DorisSink<String> dorisSink = DorisSink.<String>builder()
.setDorisOptions(dorisOptions)
.setDorisReadOptions(DorisReadOptions.builder().build())
.setDorisExecutionOptions(DorisExecutionOptions.builder()
.setDeletable(false) //是否删除表
.disable2PC() //关闭两阶段提交
.setLabelPrefix("doris-") //事务前缀
.setBufferCount(1024) //批处理 最大buffer
.setCheckInterval(2) //校验时间间隔
.setMaxRetries(3) //最大重试次数
.setStreamLoadProp(properties)
.build())
.setSerializer(new SimpleStringSerializer()) //JsonDebeziumSchemaSerializer.builder().setDorisOptions(dorisOptions).build()
.build();
//todo 4.将数据写出
socketTextStream.sinkTo(dorisSink);
//todo 5.启动任务
env.execute();
}
}

③ 写RowData数据(不常用)
官方模板:

④ 写pojo数据
三)SQL的方式读写Doris
1)读
官网模板:

使用:
public class Doris_Read {
public static void main(String[] args) throws Exception {
//todo 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//todo 创建表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//todo 使用sql读取
tableEnv.executeSql("CREATE TABLE flink_doris ( " +
" siteid INT, " +
" citycode SMALLINT, " +
" username STRING, " +
" pv BIGINT " +
" ) " +
" WITH ( " +
" 'connector' = 'doris', " +
" 'fenodes' = 'hadoop102:7030', " +
" 'table.identifier' = 'test.table1', " +
" 'username' = 'root', " +
" 'password' = '000000' " +
") ");
tableEnv.sqlQuery("select * from flink_doris").execute().print();
}
}
2)写
官网模板:
使用:
public class Doris_SQL {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//修改并行度
env.setParallelism(1);
//todo 开启checkpoint 必须
env.enableCheckpointing(5000L);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
tableEnv.executeSql("CREATE TABLE flink_doris ( " +
" siteid INT, " +
" citycode INT, " +
" username STRING, " +
" pv BIGINT " +
")WITH (" +
" 'connector' = 'doris', " +
" 'fenodes' = 'hadoop102:7030', " +
" 'table.identifier' = 'test.table1', " +
" 'username' = 'root', " +
" 'password' = '000000', " +
" 'sink.properties.format' = 'json', " +
" 'sink.buffer-count' = '4', " +
" 'sink.buffer-size' = '4086'," +
" 'sink.enable-2pc' = 'false', " + // 测试阶段可以关闭两阶段提交,方便测试
" 'sink.properties.read_json_by_line' = 'true' " +
") ");
tableEnv.executeSql("insert into flink_doris values(33, 3, '深圳', 3333)");
}
} 文章来源地址https://www.toymoban.com/news/detail-743955.html
文章来源地址https://www.toymoban.com/news/detail-743955.html
到了这里,关于Apache Doris 学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!