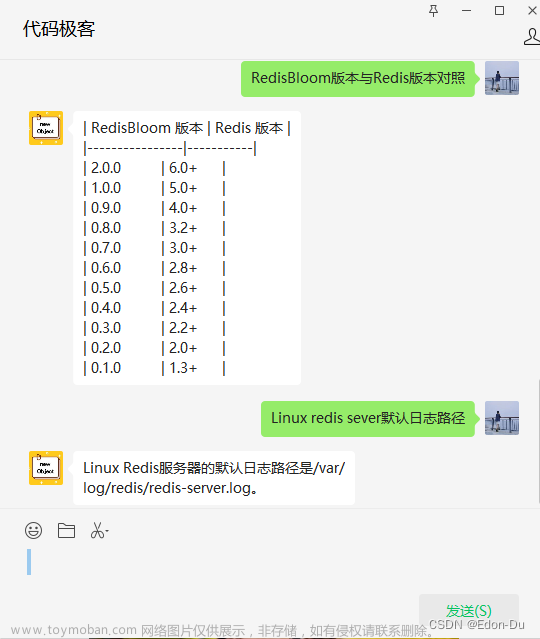
添加图片注释,不超过 140 字(可选)
ChatGPT 操作的两个主要阶段
我们再用谷歌来打个比方。当你要求谷歌查找某些内容时,你可能知道它不会——在你提出要求的那一刻——出去搜索整个网络来寻找答案。相反,谷歌会在其数据库中搜索与该请求匹配的页面。Google 实际上有两个主要阶段:蜘蛛抓取和数据收集阶段,以及用户交互/查找阶段。
粗略地说,ChatGPT 的工作原理是相同的。数据收集阶段称为预训练,而用户响应阶段称为推理。生成式人工智能背后的魔力及其突然爆发的原因是预训练的工作方式突然被证明具有巨大的可扩展性。这种可扩展性是通过最近在经济实惠的硬件技术和云计算方面的创新而实现的。
人工智能预训练的工作原理
一般来说(因为要了解具体细节需要花费大量时间),人工智能使用两种主要方法进行预训练:监督和非监督。对于大多数人工智能项目,直到当前的生成式人工智能系统(如 ChatGPT),都使用了监督方法。
监督预训练是在标记数据集上训练模型的过程,其中每个输入都与相应的输出相关联。
例如,人工智能可以在客户服务对话数据集上进行训练,其中用户的问题和投诉被标记为客户服务代表的适当答复。为了训练人工智能,需要提出诸如“如何重置密码?”之类的问题。将作为用户输入提供,并且诸如“您可以通过访问我们网站上的帐户设置页面并按照提示操作来重置密码”之类的答案将作为输出提供。
在监督训练方法中,整个模型被训练以学习可以准确地将输入映射到输出的映射函数。该过程通常用于监督学习任务,例如分类、回归和序列标记。
正如您可能想象的那样,其扩展方式是有限的。人类培训师必须花很大力气来预测所有的输入和输出。培训可能需要很长时间,并且主题专业知识有限。
变压器架构
Transformer架构是一种用于处理自然语言数据的神经网络。神经网络通过互连节点层处理信息来模拟人脑的工作方式。将神经网络想象成一个曲棍球队:每个球员都有一个角色,但他们在具有特定角色的球员之间来回传递冰球,所有人一起努力得分。文章来源:https://www.toymoban.com/news/detail-744277.html
Transformer 架构在进行预测时,通过使用“自注意力”来权衡序列中不同单词的重要性来处理单词序列。自我注意力类似于读者回顾前一个句子或段落以了解理解书中新单词所需的上下文的方式。转换器查看序列中的所有单词,以了解上下文以及单词之间的关系。文章来源地址https://www.toymoban.com/news/detail-744277.html
到了这里,关于ChatGPT 实际上是如何工作的?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!