前言:
在下载欧洲专利局Global Dossier中的专利审查文件时,想到可以利用Python批量下载,省去一些重复劳动的时间。以下载一篇美国专利(US2021036638A1)的审查档案为例,该专利的审查档案地址为:European Patent Register
探索记录:
初涉Python,本人是个纯纯的小白,爬虫也是看入门书籍了解到了皮毛😅,因此也是走一步看一步,出现问题自己慢慢在网上找答案。经过大量试错,最终总结了下方的探索历程,要是有大佬能够看出有啥更方便的渠道,还望不吝赐教。
1.Ajax异步加载应对方式:
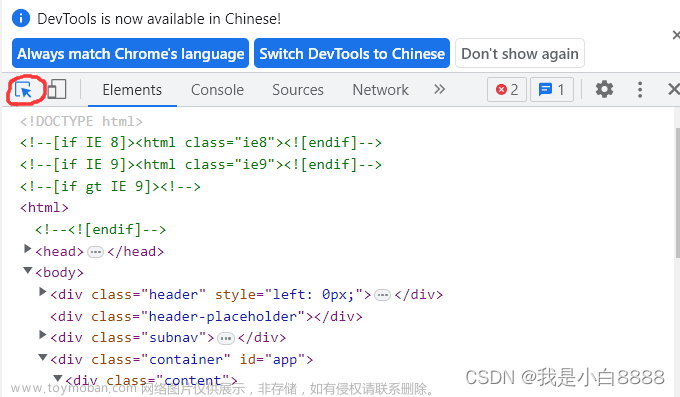
进入审查档案网址European Patent Register,按F12打开开发者工具后,发现文件位置处于<tbody>下的<tr标签中>

但是采用request+beautifulsoup模块的方式解析网站时,并不能正确地解析出该网站的内容。经过在网上的查找,应该是这个网站采用了Ajax技术异步加载,也就是我们要解析的内容不是网页原本存在的,而是后期加载进网页中的,简单的request+beautifulsoup的组合拳无法解析ajax加载的内容(个人浅薄的理解,英语专业的我也不知道Ajax技术具体是啥😤,本段解释仅供参考。)
那么,如何解析Ajax加载的内容呢?又经过查询,Ajax的请求位置可以通过开发者工具中的【网络】查看。实际加载的部分就是下图红框的部分。

双击打开后,可以看到它请求的网址是:https://register.epo.org/retrievetoc?apn=US.201916968098.A&d-16544-s=0&d-16544-o=1&lng=en

打开这个网址后,可以看到里面的内容是这样的
此时我们再用request+beautifulsoup就可以解析这个网站啦✌。
2.利用Selenium下载嵌入网页的PDF
解析网站后,我遇到了第二个问题,即这个网站中的文件链接并不是以'.pdf'结尾的链接,也就是我无法用request.get()的方式来直接访问下载PDF。于是我又进入了疯狂查找相关信息阶段。

最后,我发现Stack Overflow中有大量的关于此类PDF下载的处理方法,其中大多数都是采用禁用谷歌浏览器的“PDF Viewer”并设置PDF总是在外部打开的方式下载嵌入网页的PDF(web embeded PDF)。于是我也依样画葫芦,照着站内大佬的代码修改了一下(原代码网址:Downloading a PDF using Selenium, Chrome and Python - Stack Overflow)。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
def download_pdf(url):
download_dir=r'文件下载地址'
chrome_options = Options()
chrome_options.add_experimental_option('prefs', {
"download.default_directory": download_dir,
"download.prompt_for_download": False,
"download.directory_upgrade": True,
"plugins.always_open_pdf_externally": True #PDF始终在外部打开
}
)
#chrome_options.add_experimental_option('detach', True) #webdriver打开浏览器后保持开启,一般用于测试出错用
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
url=r"https://register.epo.org/documentView?number=US.202217672556.A&documentId=LL16AX4LGREENX1"
download_pdf(url)运行上述代码后,我得到了如下网页:

捏麻的这不还是不行嘛👿。PDF Viewer确实被禁用了,但是没有像我想象的一样PDF文件会直接下载到我指定的文件夹中。当然也有可能是我后面少了一些代码导致没有下载文件。于是我又开始查了。
3.爬虫之Iframe
上方网页中我看到了正中间醒目的【打开】按钮,我点击了一下发现直接就开始下载PDF文件了。自然而然我想到能不能用webdriver的click()来触发下载按钮。

在开发者工具中按钮对应的id是"open-button",于是我写了下方代码:
driver.find_element(by=By.ID,value='open-button').click()
结果出现了no such element: Unable to locate element:的报错。
怎么会事呢?我继续百度一下,然后找到了下面老哥的文章。
Python Selenium 元素定位正确,但始终报找不到元素错误Message: no such element: Unable to locate element: {“method“:xxx}_番茄Salad的博客-CSDN博客
大佬文章中提到了iframe,解释说“如果有嵌套的iframe的话,需要一层一层的从主页面逐层进入了。” iframe这不就是我上面网页button标签的父标签名嘛,因此我在代码前加入了大佬提到的driver.switch_to.frame("myIframe")。果然后面的代码顺利运行。至此在欧专局爬取PDF审查档案的目标就算成功了。至于文件命名及遍历下载可以在最初的ajax网页中分析文件名来实现。在此就不赘述了。
总结:
首先,是上述代码的汇总:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
def download_pdf(url):
download_dir=r''
chrome_options = Options()
chrome_options.add_experimental_option('prefs', {
"download.default_directory": download_dir,
"download.prompt_for_download": False,
"download.directory_upgrade": True,
"plugins.always_open_pdf_externally": True #PDF始终在外部打开
}
)
chrome_options.add_experimental_option('detach', True) #webdriver打开浏览器后保持开启
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
driver.switch_to.frame("myIframe") #由于PDF始终在外部打开,打开PDF文件地址后不会显示PDF,而会出现“打开”按钮,该按钮在iframe中。本句将driver转到Iframe中
driver.find_element(by=By.ID,value='open-button').click() #定位Iframe中的按钮标签,并点击下载再叠个甲:本人为Python新手,使用python主要是为了方便个人工作,并不是专业的编程人员。代码编写可能会有形式不规范的地方,望各位观众海涵。文章来源:https://www.toymoban.com/news/detail-744661.html
最后再感谢一下番茄Salad老哥提供的Iframe解决方法。本来是没打算写这种班门弄斧的文章的,但是国内论坛上好像没有免费的对该类问题比较综合的回答,故写了一下,也方便自己日后参考。文章来源地址https://www.toymoban.com/news/detail-744661.html
到了这里,关于Python 利用Selenium爬取嵌入网页的PDF(web embedded PDF)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!