NetCDF(network Common Data Form)网络通用数据格式是由美国大学大气研究协会(University Corporation for Atmospheric Research,UCAR)的Unidata项目科学家针对科学数据的特点开发的,是一种面向数组型并适于网络的数据的描述和编码标准。
NetCDF官方介绍
netcdf4-python官方文档
1 netCDF数据结构
NetCDF文件后缀一般为.nc或.nc4,netCDF存储为包含两个部分的单个文档:
- 文件头,包含维度(dimensions), 属性(attributes)和变量(variables)的所有信息,但不包含变量数据(variable data)
- 数据部分,由固定大小数据(fixed-size data,存储有限维度变量的数据)和可变大小数据(variable-size data,存储具有无限维度变量的数据
综上所述,一个典型的NetCDF文件的数据结构如下所示:
netCDF 文档有五种类型(NETCDF3_CLASSIC、NETCDF3_64BIT_OFFSET、NETCDF3_64BIT_DATA、NETCDF4_CLASSIC 和 NETCDF4)。
1.1 维度(Dimensions)
netCDF的维度具有名称和长度,维度的长度可以为任意正整数,只是在经典的netCDF数据集中只有1个维度可以具有无限长度,而在netCDF4中可以使用任意数量的无限维。这样的维度称为无限维度或者记录维度,具有无限维度的变量可以沿该维度增长至任意长度。无限维度索引就像传统面向记录的文件的记录编号。
netCDF经典数据集最多可以具有一个无限维度(不是必要的)。如果一个变量具有无限维度,这个维度必须是最重要的。因此任何无限维度都必须是CDL形状中的第一个维度和相应C数组声明中的第一个维度。而在netCDF4数据集中可以有多个无限维度,并且在变量维度列表中的顺序没有限制。要沿无限维度增长变量,请使用任何netCDF写入数据写入函数写入数据,并将无限维度的索引指定为所需的记录编号,netCDF库将写入所需的记录数量(使用填充值填充任何干预记录,除非关闭该功能)。如纬度,经度,高度和时间,前三个分配固定的长度,时间赋予UNLIMITED,这意味着它是无限的维度。
1.2 变量(Variables)
变量用于将大量数据存储在netCDF数据集中,变量表示一组具有相同类型的值。标量被当作0维数据,一个变量具有名称、数据类型和形状,形状有创建变量时指定的维度列表描述。变量还可能具有关联的属性,这些属性可以在创建变量后添加、删除或更改。
1.3 坐标变量(Coordinate Variables)
变量与维度同名是合法的,这些变量对于netCDF库没有特殊意义,但是有一个约定,就是使用此库的软件应该应以特殊方式处理此类变量。与维度同名的变量称为坐标变量,它通常定义为该维度对应的物理坐标。
1.4 属性(Attributes)
NetCDF 属性用于存储有关数据的数据(辅助数据或元数据),在许多方面类似于存储在传统数据库系统中的数据字典和架构中的信息。大多数属性提供有关特定变量的信息。属性比变量或维度更具动态性;它们可以被删除,并在创建后更改其类型、长度和值,而 netCDF 接口不提供删除变量或更改其类型或形状的方法。
1.5 基于Panoply软件查看nc数据信息
可基于Panoply软件查看nc数据信息,如下:
Panoply软件的安装可参见另一博客-【Python工具】Panoply介绍及安装步骤。
2 netCDF数据处理(netCDF4)
目前netCDF4支持以下版本:NETCDF3_CLASSIC,NETCDF3_64BIT_OFFSET,NETCDF3_64BIT_DATA,NETCDF4_CLASSIC和NETCDF4。
- 其中,NETCDF3_CLASSIC是原始的NetCDF二进制格式,缺陷是文件大小不能超过2G,之后的格式没有此限制。
- NETCDF4_CLASSIC和NETCDF4格式支持HDF5,能够读取HDF5的库也可以处理这两种格式,因此使用h5py可以读取NETCDF4_CLASSIC和NETCDF4格式的文件,但不能新建该格式的文件。

准备工作:安装netcdf4库
pip install netCDF4
# 或者使用conda
conda install -c conda-forge netCDF
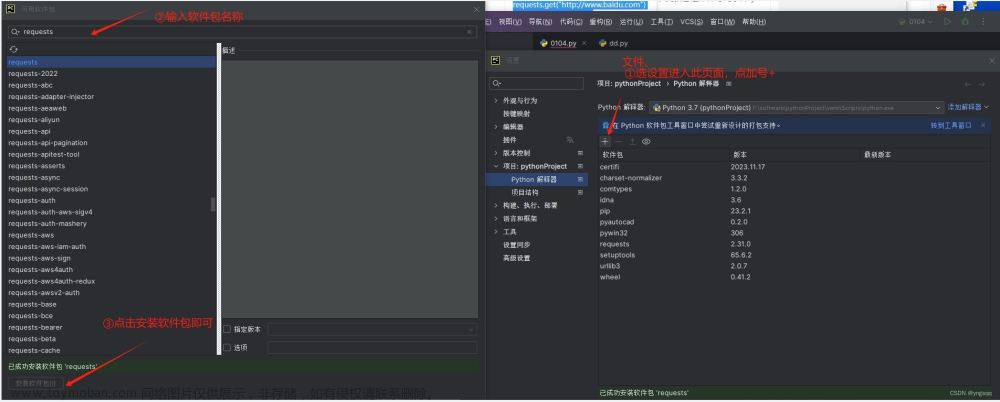
基于pip安装netcdf4库界面如下:
2.1 NetCDF文件的基本信息
2.1.1 创建/打开/关闭netCDF文件
要从 Python打开或创建一个NetCDF文件需要使用netCDF4的Dataset类/构造函数,使用方法类似于Python的open函数,一般需要传入两个参数,一个是要打开或创建的文件的路径(filename);另一个则是打开文件的模式(mode),共有如下几种:
| mode | 说明 |
|---|---|
| r | 只读,文件必须存在,此为默认的 mode |
| r+ | 读写,文件必须存在 |
| w | 创建新文件写,已经存在的文件会被覆盖掉 |
| a | 打开已经存在的文件进行读写,如果不存在则创建一个新文件读写 |
【案例1】 先导入netCDF4模块,后用该模块以只读的方式打开了示例数据。
from netCDF4 import Dataset
rootgrp = Dataset("./demo.nc", "r")
print(rootgrp.data_model)
NETCDF4
rootgrp.close()
netCDF4.Dataset类的返回值rootgrp是一个netCDF4的数据集示例,其既是文件的根目录,也是文件的入口。数据集是组、维度、变量和属性的容器,它们一起描述了数据的含义以及存储在NetCDF文件中的数据字段。数据集的data_model记录了NetCDF 文件的版本,close()方法用于关闭文件。
【案例2】 确保资源能够释放,在文件的读写时使用with语句:
import netCDF4 as nc
with nc.Dataset("./demo.nc", "a") as dataset:
print(dataset.data_model)
2.1.2 NetCDF文件的组
NetCDF在第四个版本中增加了对分层组织数据的支持,即Group,类似于文件系统中的目录。Group是变量、维度和属性以及其他组的容器。数据集是一个特殊的组,一般被称为“根组”,类似于unix文件系统中的根目录。若要在一个数据集或者组下创建新的组,需要使用数据集或组实例的createGroup()方法。该方法只有一个参数,即包含新组名称的Python字符串。
2.1.3 NetCDF文件的维度
NetCDF根据维度定义所有变量的大小,因此在创建任何变量之前,必须先创建它们使用的维度。在实践中不常使用的一个特例是标量变量,它没有维度。
维度是使用数据集或组实例的createDimension()方法创建的。第一个参数的类型为Python字符串,用于设置维度的名称,第二个参数是非负整数值或None,用于设置维度的大小。要创建不限制大小的维度(可追加的尺寸),第二个参数需设置为None或0。
time = rootgrp.createDimension("time", None)
lat = rootgrp.createDimension("lat", 73)
lon = rootgrp.createDimension("lon", 144)
说明:案例中时间和级别维度都是无限的。拥有多个无限维度是NetCDF 4的一个新特性,在NetCDF 3文件中只能有一个无限维度,而且必须是变量的第一个(最左边的)维度。
2.1.4 NetCDF文件的变量
若要创建NetCDF变量,需要使用数据集或组实例的createVariable()方法。createVariable()方法有两个强制参数,变量名(Python字符串)和变量数据类型。除创建标量变量外,不能省略dimensions关键字,其用于指定变量的维度,由包含维度名称的元组(之前用createDimension创建的)给出。
变量原始数据类型对应numpy数组的dtype属性,可以将数据类型指定为numpy的dtype对象,或者可以转换为numpy的dtype对象的任何对象。
有效的数据类型说明符包括:“f4”(32位浮点)、“f8”(64位浮点)、“i4”(32位有符号整数)、“i2”(16位有符号整数)、“i8”(64位有符号整数)、“i1”(8位有符号整数)、“u1”(8位无符号整数)、“u2”(16位无符号整数)、“u4”(32位无符号整数)、“u8”(64位无符号整数)或“S1”(单字符字符串)。只有当文件格式为NetCDF 4时,才能使用无符号整数类型和64位整数类型。
维度本身通常也被定义为变量,称为坐标变量。createVariable方法用于创建和返回变量类的实例,该实例可在以后用于访问和设置变量的数据和属性。
times = rootgrp.createVariable("time", "f8", ("time",))
levels = rootgrp.createVariable("level", "i4", ("level",))
latitudes = rootgrp.createVariable("lat", "f4", ("lat",))
longitudes = rootgrp.createVariable("lon", "f4", ("lon",))
# two dimensions unlimited
temp = rootgrp.createVariable("temp", "f4", ("time","level","lat","lon",))
2.1.5 NetCDF文件的属性
NetCDF文件中有两种类型的属性,全局属性和变量属性。全局属性提供一个组或整个数据集的信息。变量属性提供某个变量的信息。通过为数据集或组实例属性赋值来设置全局属性,通过给变量实例属性赋值来设置变量属性。属性可以是字符串、数字或序列。
数据集、组或变量实例的ncattrs()方法可用于检索所有属性的名称。提供这个方法是为了方便,因为使用Python内置的dir()函数将返回一堆私有方法和属性,而用户不能(或者不应该)修改这些方法和属性。此外,数据集、组或变量实例的__dict__属性的返回值是一个Python字典,包含所有NetCDF属性的名称和值。
2.2 NetCDF文件的读写操作
2.2.1 NetCDF文件的写入操作
2.2.2 单个NetCDF文件的读取操作
2.2.3 多个NetCDF文件的读取操作
2.3 NetCDF文件的地理参考
一个NetCDF变量的地理参考与该变量的维度相关联,用于空间定位的维度被称为坐标维度。坐标维度必须是独立变化的维度,同时有一个和其名称相同的变量并且该变量的维度就是这个用于空间定位的维度,这个变量被称为坐标变量。坐标变量最常见的用途是在空间和时间上定位数据,但可以为数据变量所依赖的任何其他连续地球物理量(例如密度、温度、辐射波长、天顶辐射角、海面波频率)或离散类别(例如区域类型、模型级别编号、集成成员编号)提供坐标。
NetCDF文件标准化的约定(COARDS)对坐标变量进行了定义,但相对而言较为简单。因此,一些学者共同制定并开源了NetCDF气候和预报(CF)元数据公约,旨在促进使用NetCDF应用程序编程器接口 NetCDF 创建的文件的处理和共享。CF公约概括并扩展COARDS公约,其目的是要求符合要求的数据集包含足够的元数据,这些元数据是自描述的,即文件中的每个变量都有对其所表示内容的相关描述,包括物理单位(如果适用),并且每个值可以位于空间(相对于基于地球的坐标)和时间中。
CF公约对四种类型的坐标变量进行了特殊处理:纬度、经度、垂直和时间。CF公约不会根据变量的名称判断一个变量是否是坐标变量,而会根据变量的units和positive属性的值判断。由于这种识别坐标类型的方法很复杂,因此CF公约提供了两种产生直接标识的可选方法。属性axis可以附加到坐标变量,并给定值 X、Y、Z或T之一,分别代表经度、纬度、垂直轴或时间轴。或者,standard_name属性可用于直接标识。但请注意,这些可选属性是对必需的COARDS元数据的补充。
要识别通用空间坐标,需要将axis属性附加到这些坐标变量中,并给定值X、Y或Z之一。轴属性的值X和Y应用于标识水平坐标变量。如果同时标识了X轴和Y轴,则X-Y-up应定义一个右手坐标系,即如果从上方观察,从正X方向到正Y方向的旋转是逆时针的。文章来源:https://www.toymoban.com/news/detail-744947.html
2.3.1 地理坐标系下的坐标变量
2.3.2 投影坐标系下的坐标变量
参考
1、知乎-NetCDF(nc)读写与格式转换介绍文章来源地址https://www.toymoban.com/news/detail-744947.html
到了这里,关于【Python实例】netCDF数据介绍及处理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!