一、题目描述
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值 target的那两个整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
提示:
2 <= nums.length <= 104-109 <= nums[i] <= 109-109 <= target <= 109- 只会存在一个有效答案
二、题解
2.1 暴力查找
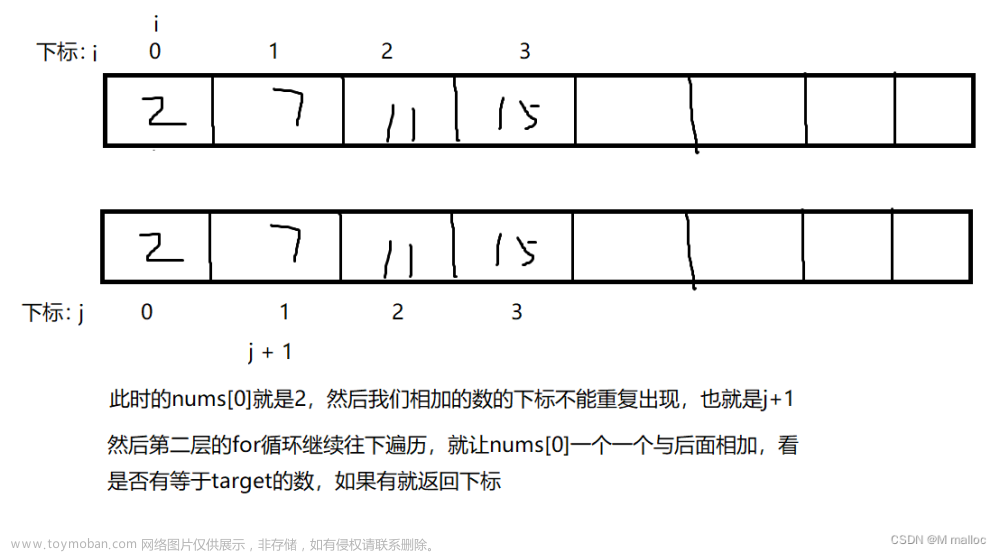
选取数组 nums 中的第一个数 num,用 target 减去,得到 another_num,即 num +another_num = target,在剩余的数中寻找 another_num,如果存在,返回两个数的索引。依次遍历整个数组。
基本思路是这样,但在 “在剩余的数中寻找num2” 这一步,寻找算法的好坏直接影响整体算法的效率。
因为数组中同一个元素不能使用两遍,这就在于 “在剩余的数中寻找num2” 中的 “剩余” 怎么实现了,不能简单地使用 if another_num in nums ,需要将寻找的 num 从查找数组 nums 中剔除,这样查找数组才是剩余的。
外循环确定 num,内循环查找 another_num ,由于内循环从 i+1 开始,保证了查找数组中不包含 num。
但暴力查找效率极低。
2.1.1 Python
def twoSum0(nums, target):
for i in range(len(nums)):
for j in range(i+1,len(nums)):
if nums[i] + nums[j] == target:
return [i,j]
2.1.2 C++
vector<int> twoSum(vector<int>& nums, int target)
{
int n = nums.size();
for (int i = 0; i < n; ++i)
{
for (int j = i + 1; j < n; ++j)
{
if (nums[i] + nums[j] == target)
{
return {i, j};
}
}
}
return {};
}
2.1.3 C
int* twoSum(int* nums, int numsSize, int target, int* returnSize)
{
for (int i = 0; i < numsSize; ++i)
{
for (int j = i + 1; j < numsSize; ++j)
{
if (nums[i] + nums[j] == target)
{
int* ret = malloc(sizeof(int) * 2);
ret[0] = i, ret[1] = j;
*returnSize = 2;
return ret;
}
}
}
*returnSize = 0;
return NULL;
}
2.1.4 复杂度分析
-
时间复杂度: O ( N 2 ) O(N^2) O(N2),其中 N N N 是数组中的元素数量。最坏情况下数组中任意两个数都要被匹配一次。
-
空间复杂度: O ( 1 ) O(1) O(1)。
2.2 哈希表查找
保持数组中的每个元素与其索引相互对应的最好方法是什么?哈希表。
使用 enumerate() 函数获取 nums 列表元素和对应索引,并将 another_num 及其对应的索引存入字典,在原列表 nums 里遍历 num ,在字典里寻找对应 another_num 。
2.2.1 Python
def twoSum1(nums, target):
hashmap = {}
for index, num in enumerate(nums):
another_num = target - num
if another_num in hashmap:
return [hashmap[another_num], index]
else:
hashmap[num] = index
return None
2.2.2 C++
vector<int> twoSum(vector<int>& nums, int target)
{
unordered_map<int, int> hashtable;
for (int i = 0; i < nums.size(); ++i)
{
auto it = hashtable.find(target - nums[i]);
if (it != hashtable.end())
{
return {it->second, i};
}
hashtable[nums[i]] = i;
}
return {};
}
2.2.3 C
struct hashTable
{
int key;
int val;
UT_hash_handle hh;
};
struct hashTable* hashtable;
struct hashTable* find(int ikey)
{
struct hashTable* tmp;
HASH_FIND_INT(hashtable, &ikey, tmp);
return tmp;
}
void insert(int ikey, int ival)
{
struct hashTable* it = find(ikey);
if (it == NULL)
{
struct hashTable* tmp = malloc(sizeof(struct hashTable));
tmp->key = ikey, tmp->val = ival;
HASH_ADD_INT(hashtable, key, tmp);
}
else
{
it->val = ival;
}
}
int* twoSum(int* nums, int numsSize, int target, int* returnSize)
{
hashtable = NULL;
for (int i = 0; i < numsSize; i++)
{
struct hashTable* it = find(target - nums[i]);
if (it != NULL)
{
int* ret = malloc(sizeof(int) * 2);
ret[0] = it->val, ret[1] = i;
*returnSize = 2;
return ret;
}
insert(nums[i], i);
}
*returnSize = 0;
return NULL;
}
2.2.4 复杂度分析
-
时间复杂度: O ( N ) O(N) O(N),其中 N N N 是数组中的元素数量。对于每一个元素 x,我们可以 O ( 1 ) O(1) O(1) 地寻找
target - x。文章来源:https://www.toymoban.com/news/detail-744963.html -
空间复杂度: O ( N ) O(N) O(N),其中 N N N 是数组中的元素数量。主要为哈希表的开销。文章来源地址https://www.toymoban.com/news/detail-744963.html
到了这里,关于[LeetCode] 1.两数之和的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!