一. 准备好Pytorch模型和yolov5-6.0项目并配置好环境
首先需要在官网下载yolov5-6.0的项目
1 我们打开yolov的官网,Tags选择6.0版本 2. 下载该压缩包并解压到工程目录下
2. 下载该压缩包并解压到工程目录下
3. 我们这里使用pycharm,专门针对python的IDE,用起来非常方便,下载方式就是官网直接下载,用的是社区版
4. 我们需要安装环境,这里我推荐安装Anaconda在电脑上,这是一个非常方便的包管理工具,可以选择不同版本的python和pip以及基础的tools工具。这里不多说,直接推荐教程
https://blog.csdn.net/whc18858/article/details/127132558?ops_request_misc=&request_id=&biz_id=102&utm_term=pc%E4%B8%8A%E5%AE%89%E8%A3%85Anconda%E5%B9%B6%E9%85%8D%E7%BD%AEpycharm&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-127132558.142v86control,239v2insert_chatgpt&spm=1018.2226.3001.4187
- 配置项目环境,上面教程中也已经提及了怎么配置解释器,对于该项目来说,要配置python3.7。
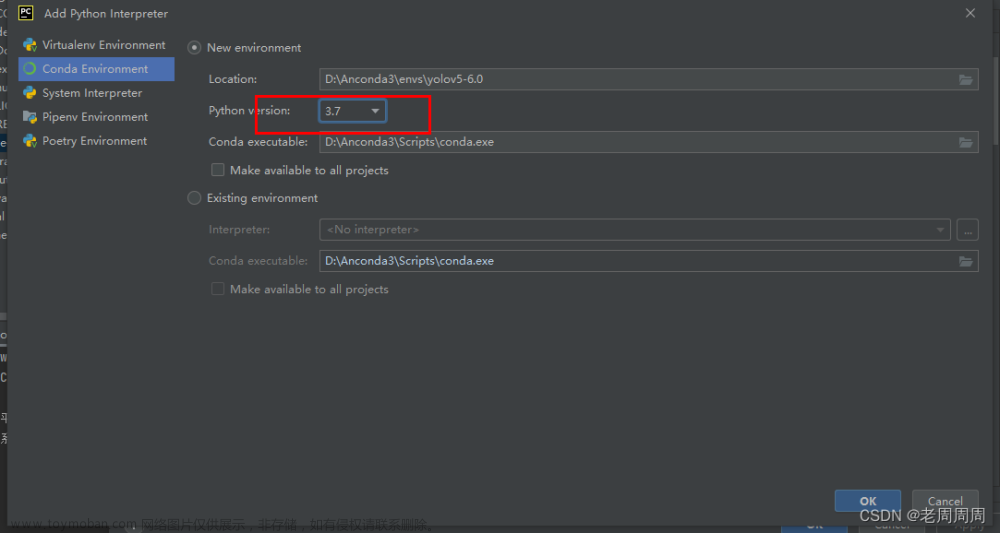
- 等待安装环境后,在终端查看是否是在Anaconda的虚拟环境中,如果是base的话应该是没有进入到该项目的虚拟环境中,这就需要你知道你创建虚拟环境时候的名字,在右下角也能够看到

- 这时候需要我们输入下面进入到该虚拟环境
conda activate yolov5-master

现在我们就进入到该虚拟环境下了,可以进行一顿操作了
- 然后就是喜闻乐见安装各种包环节,这里我们要使用国内的源进行安装下载
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
- 然后我们需要拿我们自己的pytorch模型小试一手,如果没问题就下一步了,有问题就百度或者问ai,一般来说不可能有问题

- 结果输出,效果还行

二. 修改部分项目代码并转换为onnx模型
- 就像网上很多教程说的,想要输出onnx模型需要修改yolo.py中的代码,该代码在models下面

- 这段代码是用PyTorch实现的目标检测算法中的前向传播函数。算法采用的是YOLOv5的变种。主要的思路是对输入的特征图进行多尺度的卷积和处理,然后把处理结果拼接在一起得到最终的检测结果

- 需要改为下面的代码:
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
return x
- 还需要修改一下export.py中的配置,其实不改的话也事,只需要在使用的时候加上就行

- 这里我们在终端输入:
python export.py --weights best.pt --img 640 --batch 1 --opset 12

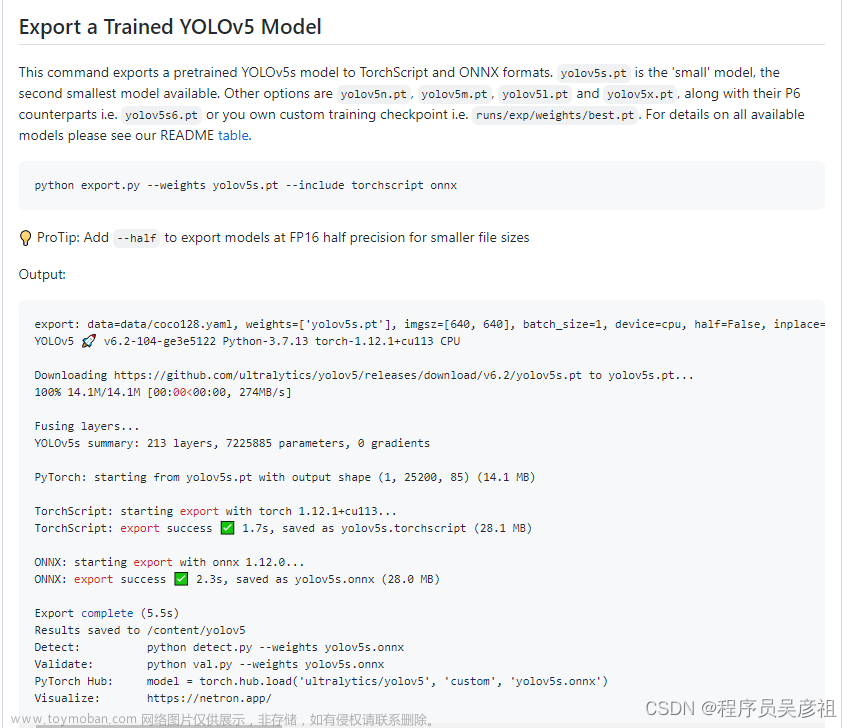
6. 这里说明我们已经转换完成了,可以查看一下该onnx模型的网络结构,使用Netron
这里观察一下自己模型的输入输出是否有问题,这里没有什么问题,准备进行下一步
三. onnx模型转换为rknn模型
- 根据firefly官网的关于使用NPU的说明,我们需要先下载所需要的包,这里我们使用的是RK_NPU_SDK_1.2.0,这里面几乎含有了所有我们需要的东西

2. 下载好包,我们就需要准备环境了。通过firefly官方对于npu的说明,RKNN-Toolkit2只能用在x86 64的ubuntu系统上,版本最好是18.04,也就是说在PC上安装虚拟机,或者专门找一个x86 64 ubuntu系统的电脑,是不是很折磨。这里我们已经找了一台ubuntu方便用来转换模型,这里我们用vscode远程连接该平台,FileZilla Client方便将onnx模型文件转入该平台,这里我已经准备好了,只需要你的onnx,RK_NPU_SDK_1.2.0以及一个素材图片,为了避免出问题,我建议测试图片使用640*640的。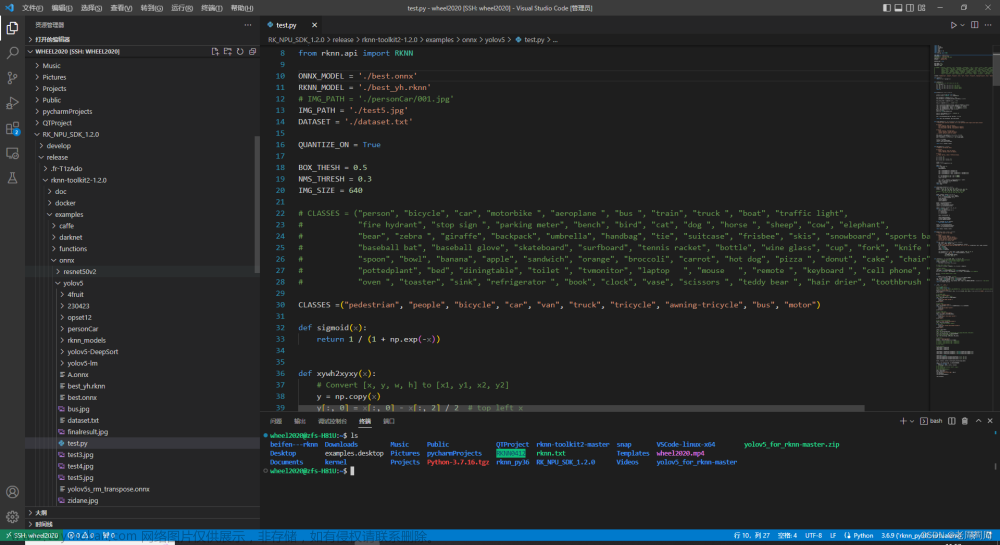
3. 这里建议是在虚拟环境中安装rknn的环境
4. 我们需要安装RKNN-Toolkit2 工具以及依赖,如何安装呢,看官网
https://wiki.t-firefly.com/zh_CN/ROC-RK3568-PC-SE/usage_npu.html
- 安装完后就可以开始转换了。目录如下:

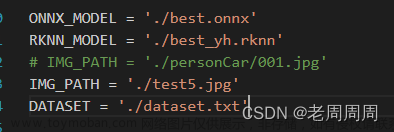
- 需要修改一下路径,包括onnx的路径以及将要生成的rknn的路径名称,测试图片的位置
- 填入自己的检测目标类class

- 根据NPU1.2.0里面doc中的说明,需要修改rknn.config,下面的outputs要删除,如下图所示:

根据自己的情况修改该参数,刚开始只需要填入一个平台名字即可
rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], target_platform='rk3568', optimization_level=3, quantized_dtype='asymmetric_quantized-8')
- 后面把输出给保存出来

end = time.time()
print (end-start,"s")
cv2.imwrite("finalresult.jpg", img_1)
cv2.waitKey(0)
cv2.destroyAllWindows()
rknn.release()
- 改完开始运行转换,还能确定onnx模型是否有问题

这里位置没什么问题,anchor特别大,不过onnx模型没问题
四. 测试rknn模型精度并在qt上部署
- opencv多平台编译参考我的另一篇RK3568+QT5+OpenCV Debian10母板开发环境搭建自记录
PS:改源后我们只下载一个东西,libjasper-dev 使用sudo apt-get install 来下载安装,(在后面测试时发现不安装编译的话后续在qtcreator中build会出现问题)随后继续换回到阿里镜像,下载编译opencv的依赖,安装完后确定一下
要注意,编译后的opencv我一般也是放在opt下面,并且给opt文件夹 777权限
2. 参考上面的文档之后你应该已经安装了qtcreator,接下来就需要一个测试程序来测试,这里用江流儿大佬改的代码测试,
https://blog.csdn.net/sxj731533730/article/details/127029969文章来源:https://www.toymoban.com/news/detail-745399.html
我们简单粗暴的创建一个控制台程序项目即可,将全部代码塞到cpp中,并且创建头文件rknn_api.h,这个文件在RK_NPU_SDK1.2.0里面有 文章来源地址https://www.toymoban.com/news/detail-745399.html
文章来源地址https://www.toymoban.com/news/detail-745399.html
- 除了必要的rknn_api.h,还需要.so库支持,库也在RK_NPU_SDK1.2.0里面,我们需要把它跟板子上的so库替换且备份,需要跟api版本相对应。


- 在pro文件中需要加上我们的编译后的opencv库,如下图

- 这里我们放出代码,这个只能对图片进行检测,至于视频或者摄像头要对该代码进行修改
#include <QCoreApplication>
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <queue>
#include "rknn_api.h"
#include "opencv2/core/core.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/highgui/highgui.hpp"
#include <chrono>
#define OBJ_NAME_MAX_SIZE 16
#define OBJ_NUMB_MAX_SIZE 200
#define OBJ_CLASS_NUM 10
#define PROP_BOX_SIZE (5+OBJ_CLASS_NUM)
using namespace std;
typedef struct _BOX_RECT {
int left;
int right;
int top;
int bottom;
} BOX_RECT;
typedef struct __detect_result_t {
char name[OBJ_NAME_MAX_SIZE];
int class_index;
BOX_RECT box;
float prop;
} detect_result_t;
typedef struct _detect_result_group_t {
int id;
int count;
detect_result_t results[OBJ_NUMB_MAX_SIZE];
} detect_result_group_t;
//const int anchor0[6] = {10, 13, 16, 30, 33, 23};
//const int anchor1[6] = {30, 61, 62, 45, 59, 119};
//const int anchor2[6] = {116, 90, 156, 198, 373, 326};
const int anchor0[6] = {3, 4, 4, 8, 9, 6};
const int anchor1[6] = {6, 14, 14, 10, 15, 30};
const int anchor2[6] = {29, 23, 39, 50, 94, 82};
void printRKNNTensor(rknn_tensor_attr *attr) {
printf("index=%d name=%s n_dims=%d dims=[%d %d %d %d] n_elems=%d size=%d "
"fmt=%d type=%d qnt_type=%d fl=%d zp=%d scale=%f\n",
attr->index, attr->name, attr->n_dims, attr->dims[3], attr->dims[2],
attr->dims[1], attr->dims[0], attr->n_elems, attr->size, 0, attr->type,
attr->qnt_type, attr->fl, attr->zp, attr->scale);
}
float sigmoid(float x) {
return 1.0 / (1.0 + expf(-x));
}
float unsigmoid(float y) {
return -1.0 * logf((1.0 / y) - 1.0);
}
int process_fp(float *input, int *anchor, int grid_h, int grid_w, int height, int width, int stride,
std::vector<float> &boxes, std::vector<float> &boxScores, std::vector<int> &classId,
float threshold) {
int validCount = 0;
int grid_len = grid_h * grid_w;
float thres_sigmoid = unsigmoid(threshold);
for (int a = 0; a < 3; a++) {
for (int i = 0; i < grid_h; i++) {
for (int j = 0; j < grid_w; j++) {
float box_confidence = input[(PROP_BOX_SIZE * a + 4) * grid_len + i * grid_w + j];
if (box_confidence >= thres_sigmoid) {
int offset = (PROP_BOX_SIZE * a) * grid_len + i * grid_w + j;
float *in_ptr = input + offset;
float box_x = sigmoid(*in_ptr) * 2.0 - 0.5;
float box_y = sigmoid(in_ptr[grid_len]) * 2.0 - 0.5;
float box_w = sigmoid(in_ptr[2 * grid_len]) * 2.0;
float box_h = sigmoid(in_ptr[3 * grid_len]) * 2.0;
box_x = (box_x + j) * (float) stride;
box_y = (box_y + i) * (float) stride;
box_w = box_w * box_w * (float) anchor[a * 2];
box_h = box_h * box_h * (float) anchor[a * 2 + 1];
box_x -= (box_w / 2.0);
box_y -= (box_h / 2.0);
boxes.push_back(box_x);
boxes.push_back(box_y);
boxes.push_back(box_w);
boxes.push_back(box_h);
float maxClassProbs = in_ptr[5 * grid_len];
int maxClassId = 0;
for (int k = 1; k < OBJ_CLASS_NUM; ++k) {
float prob = in_ptr[(5 + k) * grid_len];
if (prob > maxClassProbs) {
maxClassId = k;
maxClassProbs = prob;
}
}
float box_conf_f32 = sigmoid(box_confidence);
float class_prob_f32 = sigmoid(maxClassProbs);
boxScores.push_back(box_conf_f32 * class_prob_f32);
classId.push_back(maxClassId);
validCount++;
}
}
}
}
return validCount;
}
float CalculateOverlap(float xmin0, float ymin0, float xmax0, float ymax0, float xmin1, float ymin1, float xmax1,
float ymax1) {
float w = fmax(0.f, fmin(xmax0, xmax1) - fmax(xmin0, xmin1) + 1.0);
float h = fmax(0.f, fmin(ymax0, ymax1) - fmax(ymin0, ymin1) + 1.0);
float i = w * h;
float u = (xmax0 - xmin0 + 1.0) * (ymax0 - ymin0 + 1.0) + (xmax1 - xmin1 + 1.0) * (ymax1 - ymin1 + 1.0) - i;
return u <= 0.f ? 0.f : (i / u);
}
int nms(int validCount, std::vector<float> &outputLocations, std::vector<int> &order, float threshold) {
for (int i = 0; i < validCount; ++i) {
if (order[i] == -1) {
continue;
}
int n = order[i];
for (int j = i + 1; j < validCount; ++j) {
int m = order[j];
if (m == -1) {
continue;
}
float xmin0 = outputLocations[n * 4 + 0];
float ymin0 = outputLocations[n * 4 + 1];
float xmax0 = outputLocations[n * 4 + 0] + outputLocations[n * 4 + 2];
float ymax0 = outputLocations[n * 4 + 1] + outputLocations[n * 4 + 3];
float xmin1 = outputLocations[m * 4 + 0];
float ymin1 = outputLocations[m * 4 + 1];
float xmax1 = outputLocations[m * 4 + 0] + outputLocations[m * 4 + 2];
float ymax1 = outputLocations[m * 4 + 1] + outputLocations[m * 4 + 3];
float iou = CalculateOverlap(xmin0, ymin0, xmax0, ymax0, xmin1, ymin1, xmax1, ymax1);
if (iou > threshold) {
order[j] = -1;
}
}
}
return 0;
}
int quick_sort_indice_inverse(
std::vector<float> &input,
int left,
int right,
std::vector<int> &indices) {
float key;
int key_index;
int low = left;
int high = right;
if (left < right) {
key_index = indices[left];
key = input[left];
while (low < high) {
while (low < high && input[high] <= key) {
high--;
}
input[low] = input[high];
indices[low] = indices[high];
while (low < high && input[low] >= key) {
low++;
}
input[high] = input[low];
indices[high] = indices[low];
}
input[low] = key;
indices[low] = key_index;
quick_sort_indice_inverse(input, left, low - 1, indices);
quick_sort_indice_inverse(input, low + 1, right, indices);
}
return low;
}
int clamp(float val, int min, int max) {
return val > min ? (val < max ? val : max) : min;
}
int post_process_fp(float *input0, float *input1, float *input2, int model_in_h, int model_in_w,
int h_offset, int w_offset, float resize_scale, float conf_threshold, float nms_threshold,
detect_result_group_t *group, const char *labels[]) {
memset(group, 0, sizeof(detect_result_group_t));
std::vector<float> filterBoxes;
std::vector<float> boxesScore;
std::vector<int> classId;
int stride0 = 8;
int grid_h0 = model_in_h / stride0;
int grid_w0 = model_in_w / stride0;
int validCount0 = 0;
validCount0 = process_fp(input0, (int *) anchor0, grid_h0, grid_w0, model_in_h, model_in_w,
stride0, filterBoxes, boxesScore, classId, conf_threshold);
int stride1 = 16;
int grid_h1 = model_in_h / stride1;
int grid_w1 = model_in_w / stride1;
int validCount1 = 0;
validCount1 = process_fp(input1, (int *) anchor1, grid_h1, grid_w1, model_in_h, model_in_w,
stride1, filterBoxes, boxesScore, classId, conf_threshold);
int stride2 = 32;
int grid_h2 = model_in_h / stride2;
int grid_w2 = model_in_w / stride2;
int validCount2 = 0;
validCount2 = process_fp(input2, (int *) anchor2, grid_h2, grid_w2, model_in_h, model_in_w,
stride2, filterBoxes, boxesScore, classId, conf_threshold);
int validCount = validCount0 + validCount1 + validCount2;
// no object detect
if (validCount <= 0) {
return 0;
}
std::vector<int> indexArray;
for (int i = 0; i < validCount; ++i) {
indexArray.push_back(i);
}
quick_sort_indice_inverse(boxesScore, 0, validCount - 1, indexArray);
nms(validCount, filterBoxes, indexArray, nms_threshold);
int last_count = 0;
/* box valid detect target */
for (int i = 0; i < validCount; ++i) {
if (indexArray[i] == -1 || boxesScore[i] < conf_threshold || last_count >= OBJ_NUMB_MAX_SIZE) {
continue;
}
int n = indexArray[i];
float x1 = filterBoxes[n * 4 + 0];
float y1 = filterBoxes[n * 4 + 1];
float x2 = x1 + filterBoxes[n * 4 + 2];
float y2 = y1 + filterBoxes[n * 4 + 3];
int id = classId[n];
group->results[last_count].box.left = (int) ((clamp(x1, 0, model_in_w) - w_offset) / resize_scale);
group->results[last_count].box.top = (int) ((clamp(y1, 0, model_in_h) - h_offset) / resize_scale);
group->results[last_count].box.right = (int) ((clamp(x2, 0, model_in_w) - w_offset) / resize_scale);
group->results[last_count].box.bottom = (int) ((clamp(y2, 0, model_in_h) - h_offset) / resize_scale);
group->results[last_count].prop = boxesScore[i];
group->results[last_count].class_index = id;
const char *label = labels[id];
strncpy(group->results[last_count].name, label, OBJ_NAME_MAX_SIZE);
// printf("result %2d: (%4d, %4d, %4d, %4d), %s\n", i, group->results[last_count].box.left, group->results[last_count].box.top,
// group->results[last_count].box.right, group->results[last_count].box.bottom, label);
last_count++;
}
group->count = last_count;
return 0;
}
float deqnt_affine_to_f32(uint8_t qnt, uint8_t zp, float scale) {
return ((float) qnt - (float) zp) * scale;
}
int32_t __clip(float val, float min, float max) {
float f = val <= min ? min : (val >= max ? max : val);
return f;
}
uint8_t qnt_f32_to_affine(float f32, uint8_t zp, float scale) {
float dst_val = (f32 / scale) + zp;
uint8_t res = (uint8_t) __clip(dst_val, 0, 255);
return res;
}
int process_u8(uint8_t *input, int *anchor, int grid_h, int grid_w, int height, int width, int stride,
std::vector<float> &boxes, std::vector<float> &boxScores, std::vector<int> &classId,
float threshold, uint8_t zp, float scale) {
int validCount = 0;
int grid_len = grid_h * grid_w;
float thres = unsigmoid(threshold);
uint8_t thres_u8 = qnt_f32_to_affine(thres, zp, scale);
for (int a = 0; a < 3; a++) {
for (int i = 0; i < grid_h; i++) {
for (int j = 0; j < grid_w; j++) {
uint8_t box_confidence = input[(PROP_BOX_SIZE * a + 4) * grid_len + i * grid_w + j];
if (box_confidence >= thres_u8) {
int offset = (PROP_BOX_SIZE * a) * grid_len + i * grid_w + j;
uint8_t *in_ptr = input + offset;
float box_x = sigmoid(deqnt_affine_to_f32(*in_ptr, zp, scale)) * 2.0 - 0.5;
float box_y = sigmoid(deqnt_affine_to_f32(in_ptr[grid_len], zp, scale)) * 2.0 - 0.5;
float box_w = sigmoid(deqnt_affine_to_f32(in_ptr[2 * grid_len], zp, scale)) * 2.0;
float box_h = sigmoid(deqnt_affine_to_f32(in_ptr[3 * grid_len], zp, scale)) * 2.0;
box_x = (box_x + j) * (float) stride;
box_y = (box_y + i) * (float) stride;
box_w = box_w * box_w * (float) anchor[a * 2];
box_h = box_h * box_h * (float) anchor[a * 2 + 1];
box_x -= (box_w / 2.0);
box_y -= (box_h / 2.0);
boxes.push_back(box_x);
boxes.push_back(box_y);
boxes.push_back(box_w);
boxes.push_back(box_h);
uint8_t maxClassProbs = in_ptr[5 * grid_len];
int maxClassId = 0;
for (int k = 1; k < OBJ_CLASS_NUM; ++k) {
uint8_t prob = in_ptr[(5 + k) * grid_len];
if (prob > maxClassProbs) {
maxClassId = k;
maxClassProbs = prob;
}
}
float box_conf_f32 = sigmoid(deqnt_affine_to_f32(box_confidence, zp, scale));
float class_prob_f32 = sigmoid(deqnt_affine_to_f32(maxClassProbs, zp, scale));
boxScores.push_back(box_conf_f32 * class_prob_f32);
classId.push_back(maxClassId);
validCount++;
}
}
}
}
return validCount;
}
int post_process_u8(uint8_t *input0, uint8_t *input1, uint8_t *input2, int model_in_h, int model_in_w,
int h_offset, int w_offset, float resize_scale, float conf_threshold, float nms_threshold,
std::vector<uint8_t> &qnt_zps, std::vector<float> &qnt_scales,
detect_result_group_t *group, const char *labels[]) {
memset(group, 0, sizeof(detect_result_group_t));
std::vector<float> filterBoxes;
std::vector<float> boxesScore;
std::vector<int> classId;
int stride0 = 8;
int grid_h0 = model_in_h / stride0;
int grid_w0 = model_in_w / stride0;
int validCount0 = 0;
validCount0 = process_u8(input0, (int *) anchor0, grid_h0, grid_w0, model_in_h, model_in_w,
stride0, filterBoxes, boxesScore, classId, conf_threshold, qnt_zps[0], qnt_scales[0]);
int stride1 = 16;
int grid_h1 = model_in_h / stride1;
int grid_w1 = model_in_w / stride1;
int validCount1 = 0;
validCount1 = process_u8(input1, (int *) anchor1, grid_h1, grid_w1, model_in_h, model_in_w,
stride1, filterBoxes, boxesScore, classId, conf_threshold, qnt_zps[1], qnt_scales[1]);
int stride2 = 32;
int grid_h2 = model_in_h / stride2;
int grid_w2 = model_in_w / stride2;
int validCount2 = 0;
validCount2 = process_u8(input2, (int *) anchor2, grid_h2, grid_w2, model_in_h, model_in_w,
stride2, filterBoxes, boxesScore, classId, conf_threshold, qnt_zps[2], qnt_scales[2]);
int validCount = validCount0 + validCount1 + validCount2;
// no object detect
if (validCount <= 0) {
return 0;
}
std::vector<int> indexArray;
for (int i = 0; i < validCount; ++i) {
indexArray.push_back(i);
}
quick_sort_indice_inverse(boxesScore, 0, validCount - 1, indexArray);
nms(validCount, filterBoxes, indexArray, nms_threshold);
int last_count = 0;
group->count = 0;
/* box valid detect target */
for (int i = 0; i < validCount; ++i) {
if (indexArray[i] == -1 || boxesScore[i] < conf_threshold || last_count >= OBJ_NUMB_MAX_SIZE) {
continue;
}
int n = indexArray[i];
float x1 = filterBoxes[n * 4 + 0];
float y1 = filterBoxes[n * 4 + 1];
float x2 = x1 + filterBoxes[n * 4 + 2];
float y2 = y1 + filterBoxes[n * 4 + 3];
int id = classId[n];
group->results[last_count].box.left = (int) ((clamp(x1, 0, model_in_w) - w_offset) / resize_scale);
group->results[last_count].box.top = (int) ((clamp(y1, 0, model_in_h) - h_offset) / resize_scale);
group->results[last_count].box.right = (int) ((clamp(x2, 0, model_in_w) - w_offset) / resize_scale);
group->results[last_count].box.bottom = (int) ((clamp(y2, 0, model_in_h) - h_offset) / resize_scale);
group->results[last_count].prop = boxesScore[i];
group->results[last_count].class_index = id;
const char *label = labels[id];
strncpy(group->results[last_count].name, label, OBJ_NAME_MAX_SIZE);
// printf("result %2d: (%4d, %4d, %4d, %4d), %s\n", i, group->results[last_count].box.left, group->results[last_count].box.top,
// group->results[last_count].box.right, group->results[last_count].box.bottom, label);
last_count++;
}
group->count = last_count;
return 0;
}
void letterbox(cv::Mat rgb,cv::Mat &img_resize,int target_width,int target_height){
float shape_0=rgb.rows;
float shape_1=rgb.cols;
float new_shape_0=target_height;
float new_shape_1=target_width;
float r=std::min(new_shape_0/shape_0,new_shape_1/shape_1);
float new_unpad_0=int(round(shape_1*r));
float new_unpad_1=int(round(shape_0*r));
float dw=new_shape_1-new_unpad_0;
float dh=new_shape_0-new_unpad_1;
dw=dw/2;
dh=dh/2;
cv::Mat copy_rgb=rgb.clone();
if(int(shape_0)!=int(new_unpad_0)&&int(shape_1)!=int(new_unpad_1)){
cv::resize(copy_rgb,img_resize,cv::Size(new_unpad_0,new_unpad_1));
copy_rgb=img_resize;
}
int top=int(round(dh-0.1));
int bottom=int(round(dh+0.1));
int left=int(round(dw-0.1));
int right=int(round(dw+0.1));
cv::copyMakeBorder(copy_rgb, img_resize,top, bottom, left, right, cv::BORDER_CONSTANT, cv::Scalar(0,0,0));
}
int main(int argc, char **argv) {
const char *img_path = "/opt/testPictures/test4.jpg";
//const char *img_path = "/opt/personCar/002.jpg";
const char *model_path = "/opt/model/RK356X/best.rknn";
const char *post_process_type = "fp";//fp
const int target_width = 640;
const int target_height = 640;
const char *image_process_mode = "letter_box";
float resize_scale = 0;
int h_pad=0;
int w_pad=0;
const float nms_threshold = 0.2;
const float conf_threshold = 0.3;
// const char *labels[] = {"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat",
// "traffic light",
// "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse",
// "sheep", "cow",
// "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie",
// "suitcase", "frisbee",
// "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove",
// "skateboard", "surfboard",
// "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl",
// "banana", "apple",
// "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake",
// "chair", "couch",
// "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote",
// "keyboard", "cell phone",
// "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase",
// "scissors", "teddy bear",
// "hair drier", "toothbrush"};
const char *labels[] = {"pedestrian", "people", "bicycle", "car", "van", "truck", "tricycle", "awning-tricycle", "bus", "motor"};
// Load image
cv::Mat bgr = cv::imread(img_path);
if (!bgr.data) {
printf("cv::imread %s fail!\n", img_path);
return -1;
}
cv::Mat rgb;
//BGR->RGB
cv::cvtColor(bgr, rgb, cv::COLOR_BGR2RGB);
cv::Mat img_resize;
float correction[2] = {0, 0};
float scale_factor[] = {0, 0};
int width=rgb.cols;
int height=rgb.rows;
// Letter box resize
float img_wh_ratio = (float) width / (float) height;
float input_wh_ratio = (float) target_width / (float) target_height;
int resize_width;
int resize_height;
if (img_wh_ratio >= input_wh_ratio) {
//pad height dim
resize_scale = (float) target_width / (float) width;
resize_width = target_width;
resize_height = (int) ((float) height * resize_scale);
w_pad = 0;
h_pad = (target_height - resize_height) / 2;
} else {
//pad width dim
resize_scale = (float) target_height / (float) height;
resize_width = (int) ((float) width * resize_scale);
resize_height = target_height;
w_pad = (target_width - resize_width) / 2;;
h_pad = 0;
}
if(strcmp(image_process_mode,"letter_box")==0){
letterbox(rgb,img_resize,target_width,target_height);
}else {
cv::resize(rgb, img_resize, cv::Size(target_width, target_height));
}
// Load model
FILE *fp = fopen(model_path, "rb");
if (fp == NULL) {
printf("fopen %s fail!\n", model_path);
return -1;
}
fseek(fp, 0, SEEK_END);
int model_len = ftell(fp);
void *model = malloc(model_len);
fseek(fp, 0, SEEK_SET);
if (model_len != fread(model, 1, model_len, fp)) {
printf("fread %s fail!\n", model_path);
free(model);
return -1;
}
rknn_context ctx = 0;
int ret = rknn_init(&ctx, model, model_len, 0,0);
if (ret < 0) {
printf("rknn_init fail! ret=%d\n", ret);
return -1;
}
/* Query sdk version */
rknn_sdk_version version;
ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &version,
sizeof(rknn_sdk_version));
if (ret < 0) {
printf("rknn_init error ret=%d\n", ret);
return -1;
}
printf("sdk version: %s driver version: %s\n", version.api_version,
version.drv_version);
/* Get input,output attr */
rknn_input_output_num io_num;
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
if (ret < 0) {
printf("rknn_init error ret=%d\n", ret);
return -1;
}
printf("model input num: %d, output num: %d\n", io_num.n_input,
io_num.n_output);
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (int i = 0; i < io_num.n_input; i++) {
input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]),
sizeof(rknn_tensor_attr));
if (ret < 0) {
printf("rknn_init error ret=%d\n", ret);
return -1;
}
printRKNNTensor(&(input_attrs[i]));
}
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++) {
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]),
sizeof(rknn_tensor_attr));
printRKNNTensor(&(output_attrs[i]));
}
int input_channel = 3;
int input_width = 0;
int input_height = 0;
if (input_attrs[0].fmt == RKNN_TENSOR_NCHW) {
printf("model is NCHW input fmt\n");
input_width = input_attrs[0].dims[0];
input_height = input_attrs[0].dims[1];
printf("input_width=%d input_height=%d\n", input_width, input_height);
} else {
printf("model is NHWC input fmt\n");
input_width = input_attrs[0].dims[1];
input_height = input_attrs[0].dims[2];
printf("input_width=%d input_height=%d\n", input_width, input_height);
}
printf("model input height=%d, width=%d, channel=%d\n", input_height, input_width,
input_channel);
/* Init input tensor */
rknn_input inputs[1];
memset(inputs, 0, sizeof(inputs));
inputs[0].index = 0;
inputs[0].buf = img_resize.data;
inputs[0].type = RKNN_TENSOR_UINT8;
inputs[0].size = input_width * input_height * input_channel;
inputs[0].fmt = RKNN_TENSOR_NHWC;
inputs[0].pass_through = 0;
/* Init output tensor */
rknn_output outputs[io_num.n_output];
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < io_num.n_output; i++) {
if (strcmp(post_process_type, "fp") == 0) {
outputs[i].want_float = 1;
} else if (strcmp(post_process_type, "u8") == 0) {
outputs[i].want_float = 0;
}
}
printf("img.cols: %d, img.rows: %d\n", img_resize.cols, img_resize.rows);
auto t1=std::chrono::steady_clock::now();
rknn_inputs_set(ctx, io_num.n_input, inputs);
ret = rknn_run(ctx, NULL);
if (ret < 0) {
printf("ctx error ret=%d\n", ret);
return -1;
}
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);
if (ret < 0) {
printf("outputs error ret=%d\n", ret);
return -1;
}
/* Post process */
std::vector<float> out_scales;
std::vector<uint8_t> out_zps;
for (int i = 0; i < io_num.n_output; ++i) {
out_scales.push_back(output_attrs[i].scale);
out_zps.push_back(output_attrs[i].zp);
}
detect_result_group_t detect_result_group;
if (strcmp(post_process_type, "u8") == 0) {
post_process_u8((uint8_t *) outputs[0].buf, (uint8_t *) outputs[1].buf, (uint8_t *) outputs[2].buf,
input_height, input_width,
h_pad, w_pad, resize_scale, conf_threshold, nms_threshold, out_zps, out_scales,
&detect_result_group, labels);
} else if (strcmp(post_process_type, "fp") == 0) {
post_process_fp((float *) outputs[0].buf, (float *) outputs[1].buf, (float *) outputs[2].buf, input_height,
input_width,
h_pad, w_pad, resize_scale, conf_threshold, nms_threshold, &detect_result_group, labels);
}
//毫秒级
auto t2=std::chrono::steady_clock::now();
double dr_ms=std::chrono::duration<double,std::milli>(t2-t1).count();
printf("%lf ms\n",dr_ms);
for (int i = 0; i < detect_result_group.count; i++) {
detect_result_t *det_result = &(detect_result_group.results[i]);
printf("%s @ (%d %d %d %d) %f\n",
det_result->name,
det_result->box.left, det_result->box.top, det_result->box.right, det_result->box.bottom,
det_result->prop);
int bx1 = det_result->box.left;
int by1 = det_result->box.top;
int bx2 = det_result->box.right;
int by2 = det_result->box.bottom;
cv::rectangle(bgr, cv::Point(bx1, by1), cv::Point(bx2, by2), cv::Scalar(231, 232, 143)); //两点的方式
char text[256];
sprintf(text, "%s %.1f%% ", det_result->name, det_result->prop * 100);
int baseLine = 0;
cv::Size label_size = cv::getTextSize(text, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int x = bx1;
int y = by1 - label_size.height - baseLine;
if (y < 0)
y = 0;
if (x + label_size.width > bgr.cols)
x = bgr.cols - label_size.width;
cv::rectangle(bgr, cv::Rect(cv::Point(x, y), cv::Size(label_size.width, label_size.height + baseLine)),
cv::Scalar(0, 0, 255), -1);
cv::putText(bgr, text, cv::Point(x, y + label_size.height),
cv::FONT_HERSHEY_DUPLEX, 0.4, cv::Scalar(255, 255, 255), 1, cv::LINE_AA);
cv::imwrite("bgr9.jpg", bgr);
}
ret = rknn_outputs_release(ctx, io_num.n_output, outputs);
if (ret < 0) {
printf("rknn_query fail! ret=%d\n", ret);
goto Error;
}
Error:
if (ctx > 0)
rknn_destroy(ctx);
if (model)
free(model);
if (fp)
fclose(fp);
return 0;
}
- 查看一下效果:

到了这里,关于yolov5-6.0项目部署+自用Pytorch模型转换rknn模型并在RK3568 linux(Debian)平台上使用qt部署使用NPU推理加速摄像头目标识别详细新手教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!