1. 幂等性
用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。 举个最简单的例子,那就是支付,用户购买商品后支付,支付扣款成功,但是返回结果的时候网络异常, 此时钱已经扣了,用户再次点击按钮,此时会进行第二次扣款,返回结果成功,用户查询余额发现多扣钱 了,流水记录也变成了两条。在以前的单应用系统中,我们只需要把数据操作放入事务中即可,发生错误立即回滚,但是再响应客户端的时候也有可能出现网络中断或者异常等等。
消息幂等性,其实就是保证同一个消息不被消费者重复消费两次
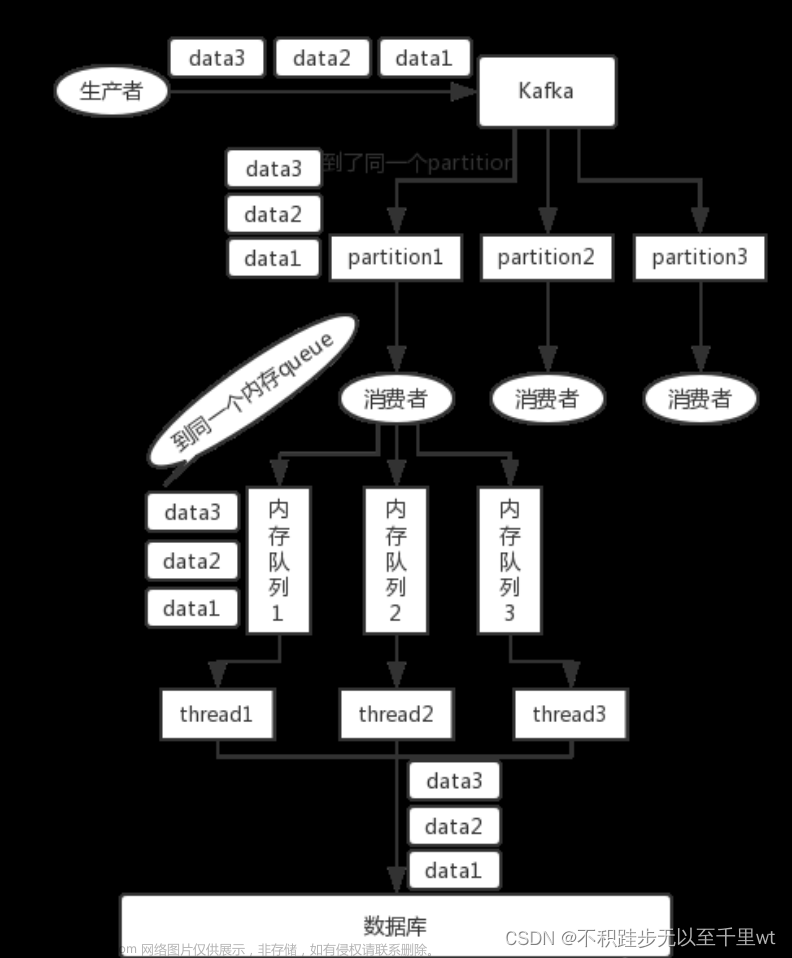
1.1 消息重复消费&重复投递
- 重复投递:
- 生产在往MQ发送消息时,MQ收到消息并持久化到本地后,进行发布确认告诉生产者,消息已经被持久化的过程中出现网络中断,生产者没有收到消息发布确认的消息,故而重新发送一条消息
- 重复消费:
- 消费者在消费 MQ 中的消息时,MQ 已把消息发送给消费者,消费者在给 MQ 返回 ack 时网络中断, 故 MQ 未收到确认信息,该条消息会重新发给其他的消费者,或者在网络重连后再次发送给该消费者,但实际上该消费者已成功消费了该条消息,造成消费者消费了重复的消息。
1.2 解决思路
MQ 消费者的幂等性的解决一般使用全局 ID 或者写个唯一标识,比如时间戳或者 UUID ,订单消费者消费 MQ 中的消息也可利用 MQ 的该 id 来判断,或者可按自己的规则生成一个全局唯一 id,每次消费消息时用该 id 先判断该消息是否已消费过。
1.3 消费端的幂等性保障
在海量订单生成的业务高峰期,生产端有可能就会重复发生了消息,这时候消费端就要实现幂等性, 这就意味着我们的消息永远不会被消费多次,即使我们收到了一样的消息。
业界主流的幂等性有两种操作:
- 方式1: 消息全局 ID 或者写个唯一标识(如时间戳、UUID 等) :每次消费消息之前根据消息 id 去判断该消息是否已消费过,如果已经消费过,则不处理这条消息,否则正常消费消息,并且进行入库操作。(消息全局 ID 作为数据库表的主键,防止重复)。
- 这里可以结合业务,根据业务的唯一ID+消息的业务需求,拼接成唯一ID。在插入的时候通过主键校验来避免重复投递,在消费的时候通过状态判断来避免重复消费
- 方式2: 利用 Redis 的 setnx 命令:给消息分配一个全局 ID,消费该消息时,先去 Redis 中查询有没消费记录,无则以键值对形式写入 Redis ,有则不消费该消息。
1.4 唯一 ID 代码演示
1.4.1 配置:
spring.rabbitmq.host=192.168.0.68
spring.rabbitmq.port=5672
spring.rabbitmq.username=admin
spring.rabbitmq.password=admin
spring.rabbitmq.virtual-host=/
# 开启消息发布确认机制
spring.rabbitmq.publisher-confirm-type=correlated
# 发布消息返回监听回调
spring.rabbitmq.publisher-returns=true
# 指定消息确认模式
spring.rabbitmq.listener.simple.acknowledge-mode=manual
# 未正确路由的消息发送到备份队列
# 使用备份交换机模式,mandatory 将无效,即就算 mandatory设 置为 false,路由失败的消息同样会被投递到绑定的备份交换机
spring.rabbitmq.template.mandatory=true
1.4.2 队列和交换机配置:
@Configuration
public class RevisitConfig {
/**
* 创建 direct 队列
* */
@Bean
Queue DirectQueue01() {
return new Queue("DirectQueue-01",true);
}
/**
* 创建 direct 交换机
* */
@Bean
DirectExchange DirectExchange01() {
return new DirectExchange("DirectExchange-01");
}
/**
* 绑定 direct 队列和交换机
* */
@Bean
Binding bindingDirect01() {
return BindingBuilder.bind(DirectQueue01()).to(DirectExchange01()).with("DirectRouting01");
}
}
1.4.3 自定义消息应答回调方法
@Component
@Slf4j
public class MyCallback implements RabbitTemplate.ConfirmCallback, RabbitTemplate.ReturnCallback {
@Autowired
private RabbitTemplate rabbitTemplate;
//依赖注入 rabbitTemplate 之后再设置它的回调对象
// 此注解会在其他注解执行完成后再执行,所以rabbitTemplate先注入,再执行此初始化方法
@PostConstruct
public void init() {
// 设置rabbitTemplate的ConfirmCallBack为我们重写后的类
rabbitTemplate.setConfirmCallback(this);
rabbitTemplate.setReturnCallback(this);
}
/**
* 交换机不管是否收到消息都会执行的一个回调方法
*
* @param correlationData 消息相关数据
* @param ack 交换机是否收到消息
* @param cause 未收到消息的原因
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
String id = correlationData != null ? correlationData.getId() : "";
if (ack) {
log.info("交换机已经收到 id 为:{}的消息", id);
} else {
log.info("交换机还未收到 id 为:{}消息,原因:{}", id, cause);
}
}
// 确认消息是否从交换机成功到达队列中,失败将会执行,成功则不执行
@Override
public void returnedMessage(Message message, int replayCode, String replayText, String exchange, String routingKey) {
log.info("消息{},被交换机{}退回,退回原因:{},路由key:", new String(message.getBody()), exchange, replayText, routingKey);
}
}
1.4.4 数据库对象相关配置:
数据库脚本:
CREATE TABLE `message_idempotent` (
`message_id` varchar(50) NOT NULL COMMENT '消息ID',
`message_content` varchar(2000) DEFAULT NULL COMMENT '消息内容',
PRIMARY KEY (`message_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
对象:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class MessageIdempotent extends Model<MessageIdempotent> {
@TableId("message_id")
private String messageId;
@TableField("message_content")
private String messageContent;
}
mapper:
@Mapper
public interface MessageIdempotentMapper extends BaseMapper<MessageIdempotent> {
}
1.4.5 生产者编写:
/**
* 消息幂等性
* */
@GetMapping("/sendMessage")
public void sendMessage(String msg, String id) {
MessageProperties messageProperties = new MessageProperties();
messageProperties.setMessageId(id);
messageProperties.setContentType("text/plain");
messageProperties.setContentEncoding("utf-8");
Message message = new Message(msg.getBytes(), messageProperties);
log.info("生产消息:" + message.toString());
// 消息发送确认回调
CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());
rabbitTemplate.convertAndSend("DirectExchange-01", "DirectRouting01", message, correlationData);
}
访问接口:
http://localhost:8091/shiro/revisit/sendMessage?msg=你好啊&id=1
http://localhost:8091/shiro/revisit/sendMessage?msg=&id=1
日志:(此处有confirmCallback未回调问题待解决,按道理打印完生产消息后应该打印:交换机已经收到 id 为:{}的消息)
2023-04-10 14:31:12.859 INFO 19232 --- [nio-8091-exec-1] c.y.t.r.TestRevisit.RevisitController : 生产消息:(Body:'你好啊' MessageProperties [headers={}, messageId=1, contentType=text/plain, contentEncoding=utf-8, contentLength=0, deliveryMode=PERSISTENT, priority=0, deliveryTag=0])
2023-04-10 14:31:29.002 INFO 19232 --- [nio-8091-exec-2] c.y.t.r.TestRevisit.RevisitController : 生产消息:(Body:'' MessageProperties [headers={}, messageId=1, contentType=text/plain, contentEncoding=utf-8, contentLength=0, deliveryMode=PERSISTENT, priority=0, deliveryTag=0])
客户端中:
1.4.6 消费者编写:
@RabbitListener(queues = "DirectQueue-01")
public void receiveMessage02(Message message, Channel channel) throws IOException {
String messageId = message.getMessageProperties().getMessageId();
String messageContent = new String(message.getBody(), StandardCharsets.UTF_8);
MessageIdempotent messageIdempotent = new MessageIdempotent();
messageIdempotent.setMessageId(messageId);
messageIdempotent.setMessageContent(messageContent);
try {
if (messageIdempotentMapper.insert(messageIdempotent) <= 0) {
log.info("DirectQueue-01-消费者收到消息,消息ID:" + messageId + " 消息内容:" + messageContent);
// 消息确认
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} else {
log.info("消息 " + messageId + " 已经消费过!");
}
} catch (Exception e) {
log.info("消息 " + messageId + " 已经消费过!");
}
}
结果:
2023-04-10 14:47:06.738 INFO 25416 --- [ntContainer#6-1] c.y.t.r.TestRevisit.RevisitConsumer : DirectQueue-01-消费者收到消息,消息ID:1 消息内容:你好啊
2023-04-10 14:47:06.745 INFO 25416 --- [ntContainer#6-1] c.y.t.r.TestRevisit.RevisitConsumer : 消息 1 已经消费过!
数据库中:
队列中:
1.5 note Redis 原子性
利用 redis 执行 setnx 命令,天然具有幂等性,从而实现不重复消费。利用redis的操作的好处是缓存更快。
代码这里不再演示,无非是一个插入数据库,一个setnx进redis。
2. 消息丢失
2.1 消息丢失的场景

- 第一种:生产者弄丢了数据。生产者将数据发送到 RabbitMQ 的时候,可能数据就在半路给搞丢了,因为网络问题啥的,都有可能。
- 第二种:RabbitMQ 弄丢了数据。MQ还没有持久化自己挂了
- 第三种:消费端弄丢了数据。刚消费到,还没处理,结果进程挂了,比如重启了。
2.2 RabbitMQ消息丢失解决方案

2.2.1 针对生产者
1. 方案1 :开启RabbitMQ事务
可以选择用 RabbitMQ 提供的事务功能,就是生产者发送数据之前开启 RabbitMQ 事务channel.txSelect,然后发送消息,如果消息没有成功被 RabbitMQ 接收到,那么生产者会收到异常报错,此时就可以回滚事务channel.txRollback,然后重试发送消息;如果收到了消息,那么可以提交事务channel.txCommit。
// 开启事务
channel.txSelect
try {
// 这里发送消息
} catch (Exception e) {
channel.txRollback
// 这里再次重发这条消息
}
// 提交事务
channel.txCommit
缺点:
RabbitMQ 事务机制是同步的,你提交一个事务之后会阻塞在那儿,采用这种方式基本上吞吐量会下来,因为太耗性能。
2. 方案2: 使用confirm机制
事务机制和 confirm 机制最大的不同在于,事务机制是同步的,你提交一个事务之后会阻塞在那儿,但是 confirm 机制是异步的
在生产者开启了confirm模式之后,每次写的消息都会分配一个唯一的id,然后如果写入了rabbitmq之中,rabbitmq会给你回传一个ack消息,告诉你这个消息发送OK了;如果rabbitmq没能处理这个消息,会回调你一个nack接口,告诉你这个消息失败了,你可以进行重试。而且你可以结合这个机制知道自己在内存里维护每个消息的id,如果超过一定时间还没接收到这个消息的回调,那么你可以进行重发。
即第一节MyCallback中:
/**
* 交换机不管是否收到消息都会执行的一个回调方法
*
* @param correlationData 消息相关数据
* @param ack 交换机是否收到消息
* @param cause 未收到消息的原因
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
String id = correlationData != null ? correlationData.getId() : "";
if (ack) {
log.info("交换机已经收到 id 为:{}的消息", id);
} else {
log.info("交换机还未收到 id 为:{}消息,原因:{}", id, cause);
}
}
2.2.2 针对RabbitMQ
说三点:
- 要保证rabbitMQ不丢失消息,那么就需要开启rabbitMQ的持久化机制,即把消息持久化到硬盘上,这样即使rabbitMQ挂掉在重启后仍然可以从硬盘读取消息;
- 如果rabbitMQ单点故障怎么办,这种情况倒不会造成消息丢失,这里就要提到rabbitMQ的3种安装模式,单机模式、普通集群模式、镜像集群模式,这里要保证rabbitMQ的高可用就要配合HAPROXY做镜像集群模式
- 如果硬盘坏掉怎么保证消息不丢失
1. 消息持久化
RabbitMQ 的消息默认存放在内存上面,如果不特别声明设置,消息不会持久化保存到硬盘上面的,如果节点重启或者意外crash掉,消息就会丢失。
所以就要对消息进行持久化处理。如何持久化,下面具体说明下:
要想做到消息持久化,必须满足以下三个条件,缺一不可。
- Exchange 设置持久化
- Queue 设置持久化
- Message持久化发送:发送消息设置发送模式deliveryMode=2,代表持久化消息
2. 设置集群镜像模式
我们先来介绍下RabbitMQ三种部署模式:
- 单节点模式:最简单的情况,非集群模式,节点挂了,消息就不能用了。业务可能瘫痪,只能等待。
- 普通模式:消息只会存在与当前节点中,并不会同步到其他节点,当前节点宕机,有影响的业务会瘫痪,只能等待节点恢复重启可用(必须持久化消息情况下)。
- 镜像模式:消息会同步到其他节点上,可以设置同步的节点个数,但吞吐量会下降。属于RabbitMQ的HA方案
为什么设置镜像模式集群,因为队列的内容仅仅存在某一个节点上面,不会存在所有节点上面,所有节点仅仅存放消息结构和元数据。下面自己画了一张图介绍普通集群丢失消息情况:
如果想解决上面途中问题,保证消息不丢失,需要采用HA 镜像模式队列。
下面介绍下三种HA策略模式:
- 同步至所有的
- 同步最多N个机器
- 只同步至符合指定名称的nodes
命令处理HA策略模版:rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
- 为每个以“rock.wechat”开头的队列设置所有节点的镜像,并且设置为自动同步模式
rabbitmqctl set_policy ha-all "^rock.wechat" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
rabbitmqctl set_policy -p rock ha-all "^rock.wechat" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
- 为每个以“rock.wechat.”开头的队列设置两个节点的镜像,并且设置为自动同步模式
rabbitmqctl set_policy -p rock ha-exacly "^rock.wechat" \
'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
- 为每个以“node.”开头的队列分配指定的节点做镜像
rabbitmqctl set_policy ha-nodes "^nodes\." \
'{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'
但是:HA 镜像队列有一个很大的缺点就是: 系统的吞吐量会有所下降
3. 消息补偿机制
为什么还要消息补偿机制呢?难道消息还会丢失,没错,系统是在一个复杂的环境,不要想的太简单了,虽然以上的三种方案,基本可以保证消息的高可用不丢失的问题,
但是作为有追求的程序员来讲,要绝对保证我的系统的稳定性,有一种危机意识。
比如:持久化的消息,保存到硬盘过程中,当前队列节点挂了,存储节点硬盘又坏了,消息丢了,怎么办?
- 生产端首先将业务数据以及消息数据入库,需要在同一个事务中,消息数据入库失败,则整体回滚。字段包括:消息id,消息状态,重试次数,创建时间等
- 根据消息表中消息状态,失败则进行消息补偿措施,重新发送消息处理。

2.2.3 针对消费者
1. 方案一:ACK确认机制
多个消费者同时收取消息,比如消息接收到一半的时候,一个消费者死掉了(逻辑复杂时间太长,超时了或者消费被停机或者网络断开链接),如何保证消息不丢?
使用rabbitmq提供的ack机制,服务端首先关闭rabbitmq的自动ack,然后每次在确保处理完这个消息之后,在代码里手动调用ack。这样就可以避免消息还没有处理完就ack。才把消息从内存删除。
这样就解决了,即使一个消费者出了问题,但不会同步消息给服务端,会有其他的消费端去消费,保证了消息不丢的case。
2.3 总结:

如果需要保证消息在整条链路中不丢失,那就需要生产端、mq自身与消费端共同去保障。
生产端:对生产的消息进行状态标记,开启confirm机制,依据mq的响应来更新消息状态,使用定时任务重新投递超时的消息,多次投递失败进行报警。
mq自身:开启持久化,并在落盘后再进行ack。如果是镜像部署模式,需要在同步到多个副本之后再进行ack。
消费端:开启手动ack模式,在业务处理完成后再进行ack,并且需要保证幂等。
通过以上的处理,理论上不存在消息丢失的情况,但是系统的吞吐量以及性能有所下降。
在实际开发中,需要考虑消息丢失的影响程度,来做出对可靠性以及性能之间的权衡。
3. 消息积压:
所谓消息积压一般是由于消费端消费的速度远小于生产者发消息的速度,导致大量消息在 RabbitMQ 的队列中无法消费。文章来源:https://www.toymoban.com/news/detail-745496.html
其实这玩意我也不知道为什么面试这么喜欢问…既然消费者速度跟不上生产者,那么提高消费者的速度就行了呀!个人认为有以下几种思路:文章来源地址https://www.toymoban.com/news/detail-745496.html
- 对生产者发消息接口进行适当限流(不太推荐,影响用户体验)
- 多部署几台消费者实例(推荐)
- 适当增加 prefetch 的数量,让消费端一次多接受一些消息(推荐,可以和第二种方案一起用)
4. 消息消费顺序性问题:
到了这里,关于RabbitMq(七) -- 常见问题:幂等性问题(消息重复消费)、消息丢失的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!