一、什么是分类问题?
在分类问题中,我们试图预测的变量𝑦是离散的值,通常表示某种类别或标签。这些类别可以是二元的,也可以是多元的。分类问题的示例包括:
- 判断一封电子邮件是否是垃圾邮件(二元分类)
- 判断一次金融交易是否涉及欺诈(二元分类)
- 区分肿瘤是恶性的还是良性的(二元分类)
- 图像识别:将图像分为不同的类别(多元分类)
分类问题在现实世界中无处不在,因此开发有效的分类算法至关重要。逻辑回归是其中一种应用最广泛的分类算法。

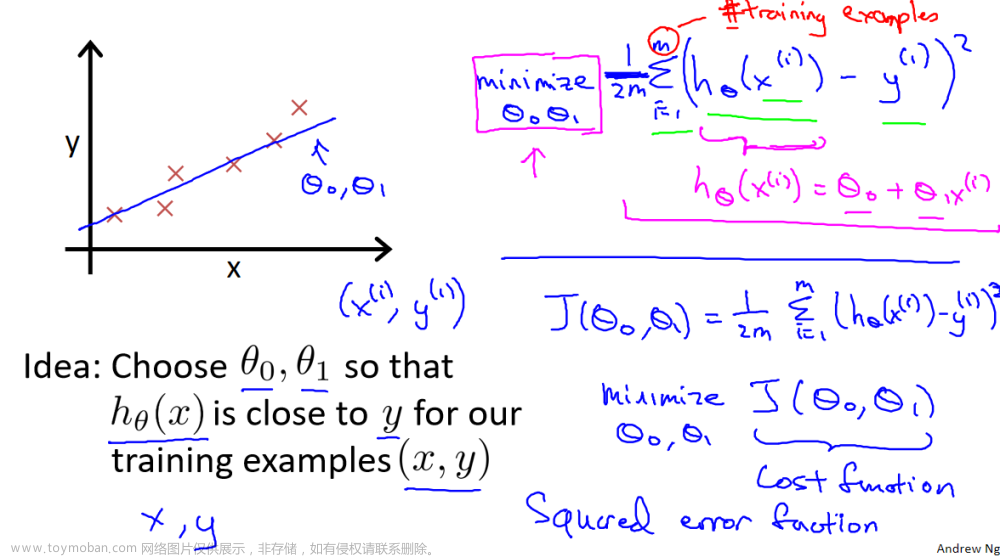
二、逻辑回归
逻辑回归是一种分类算法,尽管其名称中包含“回归”,但它实际上是用于分类任务的算法。逻辑回归的特点是其输出值永远在0到1之间,这使得它非常适合处理离散的标签,如0和1。
与线性回归不同,逻辑回归的输出范围被约束在[0, 1]之间,因此它适用于计算概率。具体来说,逻辑回归模型使用一个逻辑函数(Sigmoid函数)来将输入映射到0和1之间。逻辑函数的公式为:
g(z) = 1 / (1 + e^(-z))在这个公式中,z表示输入,g(z)表示逻辑函数。逻辑函数的作用是计算在给定输入条件下,输出为1的可能性。如果g(z)大于等于0.5,则模型预测为1;如果g(z)小于0.5,则模型预测为0。

三、假设函数表示
逻辑回归模型的假设函数表示如下:
ℎ𝜃(𝑥) = 𝑔(𝜃^𝑇𝑥)在这个表示中,𝑥代表特征向量,𝑔代表逻辑函数。模型的任务是根据选择的参数计算输出变量为1的可能性,即ℎ𝜃(𝑥) = 𝑃(𝑦 = 1|𝑥; 𝜃)。例如,如果计算得到ℎ𝜃(𝑥) = 0.7,那么表示有70%的几率𝑦为正向类,相应地𝑦为负向类的几率为0.3。

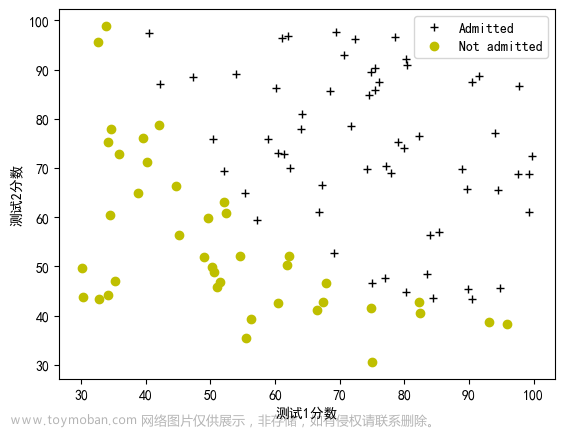
四、判定边界
在逻辑回归中,我们通过选择适当的参数𝜃来定义一个决策边界(decision boundary),该边界将数据分为不同的类别。决策边界是一个分割区域,对于不同的输入数据,模型会预测其属于不同的类别。
逻辑回归的假设函数可以表示为:
ℎ𝜃(𝑥) = 𝑔(𝜃0 + 𝜃1𝑥1 + 𝜃2𝑥2 + 𝜃3𝑥1² + 𝜃4𝑥2²)在上述表达式中,𝑥1和𝑥2是特征,𝜃0、𝜃1、𝜃2、𝜃3、𝜃4是模型的参数。根据不同的参数,我们可以得到不同的决策边界。这意味着逻辑回归模型可以适应各种形状的决策边界,从简单的直线到复杂的曲线。

参考资料:
[中英字幕]吴恩达机器学习系列课程文章来源:https://www.toymoban.com/news/detail-745712.html
黄海广博士 - 吴恩达机器学习个人笔记文章来源地址https://www.toymoban.com/news/detail-745712.html
到了这里,关于吴恩达《机器学习》6-1->6-3:分类问题、假设陈述、决策界限的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!