摘要 :21世纪的今天互联网信息技术飞速发展,各类信息充斥着互联网,如何有效的进行信息的搜集整理成为了一个非常重要的课题。网络爬虫就是实现自动搜索互联网中的各种信息的程序,本系统通过定向的对新闻网站相关的信息进行采集分析与展示。运用计算机图形学及影像处理高新技术,数字可视化能够以图像的形式展现给用户,从而让用户能够轻松地获取、分析、掌握、应用相关的知识。它不仅能够帮助用户快速、准确地获取所需的资讯,还能够让用户能够轻松地了解到所需的信息,从而提升用户的工作效率。
本课题主要任务是通过Python开发环境设计一新闻搜索引擎系统,用户可以进行新闻数据采集、新闻搜索引擎、兴趣可视化分析、个性化新闻推荐等操作,采用柱状图、词云图等可视化方式展示给用户,提供给用户进行数据的分析。在这篇文章中,我们将深入探讨这个话题的重要性,并讨论当前的网络爬虫领域的最新进展。我们还将探讨有关的系统知识与技术,并对其进行详细的需求分析。其次是系统设计,包括概要设计、模块设计、数据库设计。最后对系统进行了详细设计和测试。
关键词 信息爬取;Python;可视化展示;新闻搜索引擎
爬虫是一类非常复杂的生物,它们的类型因其特性而异。根据其特性,爬虫可以大致划分为深度爬虫、集中爬虫(Focused Crawler)、普遍爬虫(General Crawler)。这些类型的差异取决于爬虫的特性、架构、战斗策略等因素。
1通用爬虫
通用爬虫的爬取流程过程如下:主要算法为广度优先,先从给定的页面进行信息的爬取,爬取到内容进行保存,爬取出新的链接,不分顺序,直接放入到队列里面,等待继续爬取,这样一直扩散爬取到整个网站,知道满足设定的条件而停止。通用爬虫的优点:爬取数量大、爬取内容多(主要应用到搜索引擎,例如谷歌、百度、搜搜等)。缺点也比较明显,由于见啥爬啥,效率也比较低。由于爬取的东西多而杂,对存储要求也特别高,但是现在存储空间特别大,计算机内存大,cpu的计算速率也特别高,所以能够弥补通用爬虫的缺点。
通用爬虫的体系结构如图 2-1 所示,主要包含4大部分,分别为初始 URL模块,URL 队列模块,爬行模块和重复链接过滤模块。爬行模块抓取给定的初始 URL 对应的页面,重复链接过滤模块负责把访问过的链接过滤掉,过滤后的 URL 添加到 URL 队列中,重复这一过程。

图 2-1通用爬虫体系结构
3.2功能需求分析
本系统目标是设计一个新闻搜索引擎系统,主要功能需求包括以下方面:
1信息收集:在网站设计中,首先,要收集信息,从目标网址站上收集信息,将其它网站上收集的信息保存到数据库中。
2展示实现:通过对信息的处理后,可以将结果以图形的凡是显示给用户,这些信息显示要满足简单、直观、交互性良好等具体目标和要求。
3安全管理:安全管理可以分为系统安全和数据安全,系统的安全需要做好程序判断和更新维护,数据安全需要做好数据备份。
基于Python的新闻搜索引擎系统中,爬虫、搜索引擎和jieba分词都是非常重要的组成部分,具体应用如下:
1.爬虫:爬虫用于从网站中抓取所需的新闻数据,并将其保存在数据库中,以便于下一步的搜索和分析。Python常用的爬虫库有BeautifulSoup、Scrapy等,具体的爬虫实现需要根据不同的需求进行定制。
2.搜索引擎:搜索引擎是搜索功能的核心,可以对爬虫抓取的新闻进行建立索引,以便于关键词搜索和相关性排序。Python常用的搜索引擎库有Whoosh、ElasticSearch等,可以根据实际需求进行选择,并进行相关的配置和优化。
3.jieba分词:中文分词是非常重要的一环,可以将新闻按照词语进行切分,以便于建立倒排索引和进行搜索关键词匹配。Python中常用的中文分词库有jieba、THULAC等,jieba分词是一个开源的中文分词库,具有分词速度快、准确度高、易用性强等优点,是Python中常用的中文分词工具之一。
综上所述,爬虫、搜索引擎和jieba分词都是基于Python的新闻搜索引擎系统中的重要技术,它们为搜索功能的实现提供了强有力的技术支持,可以帮助用户快速找到所需的新闻信息,提高搜索效率和用户满意度。
3.3系统性能分析
良好的运行状态是提升用户体验的关键因素。而性能的好坏又取决于系统的架构的好与坏。一个优秀的系统架构一般包含以下几个方面:
1模块化设计明确。一个大的系统,分为很多小的模块,每个模块的划分清晰明确,每个模块的功能明确,且模块之间可以灵活的调用,实现低耦合高内聚。
2模块的划分,分为很多种类,要保证通用模块实现灵活的调用,特殊模块,可以随时根据系统功能等的变更及时进行更改。让系统的灵活性更高。
3稳定、安全、高效的数据建模。数据是整个系统的仓库,只有一个稳定、安全、高效的仓库,才能为系统提供好的数据存取和变更。
4整体结构稳定而又灵活。系统的整体架构在初期部署的时候,一定要有高度 ,不但结构清晰,运行稳定,当运行出现问题的时候,能够提供快速的解决方案。
3.4系统运行环境分析
1开发硬件环境:
CPU:酷睿I 5及以上
内存:4G以上
硬盘:320G以上
2 开发软件环境:
操作系统:Windows 7
开发语言:python
系统整体框架结构如下图4.1所示。

图 4.1系统整体框架结构
5.2系统实现界面
5.2.1登录界面
登录界面如图5.2所示。

图5.2 登录界面

图5.3 注册界面
5.2.2系统功能实现界面
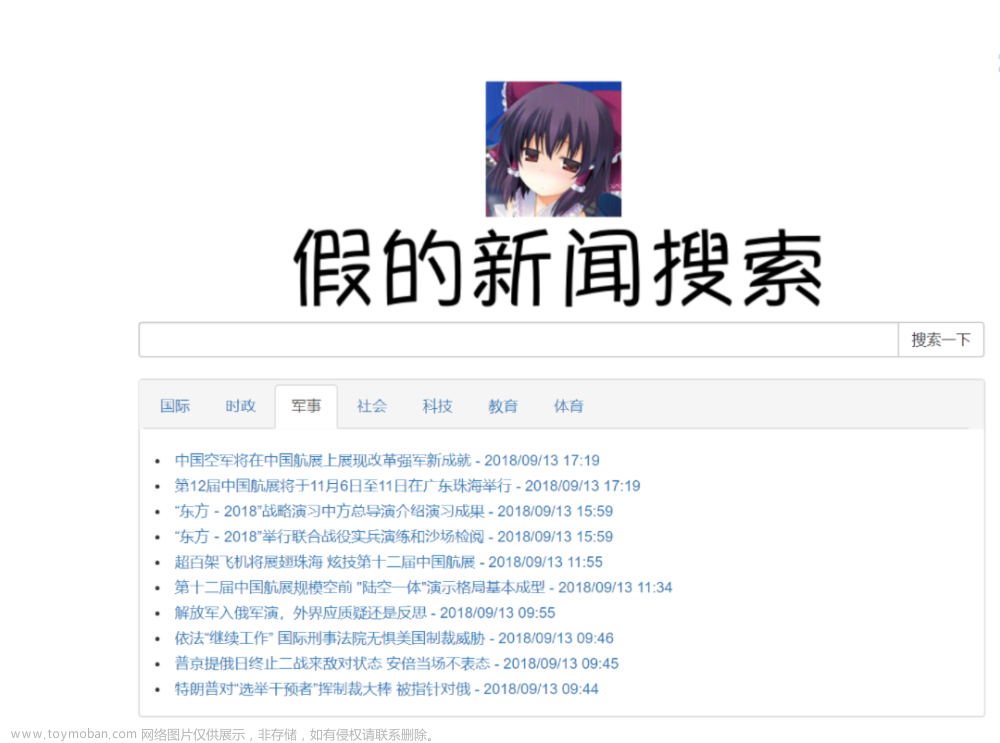
新闻数据采集信息展示界面。如图5.4

图5.4新闻数据采集展示界面
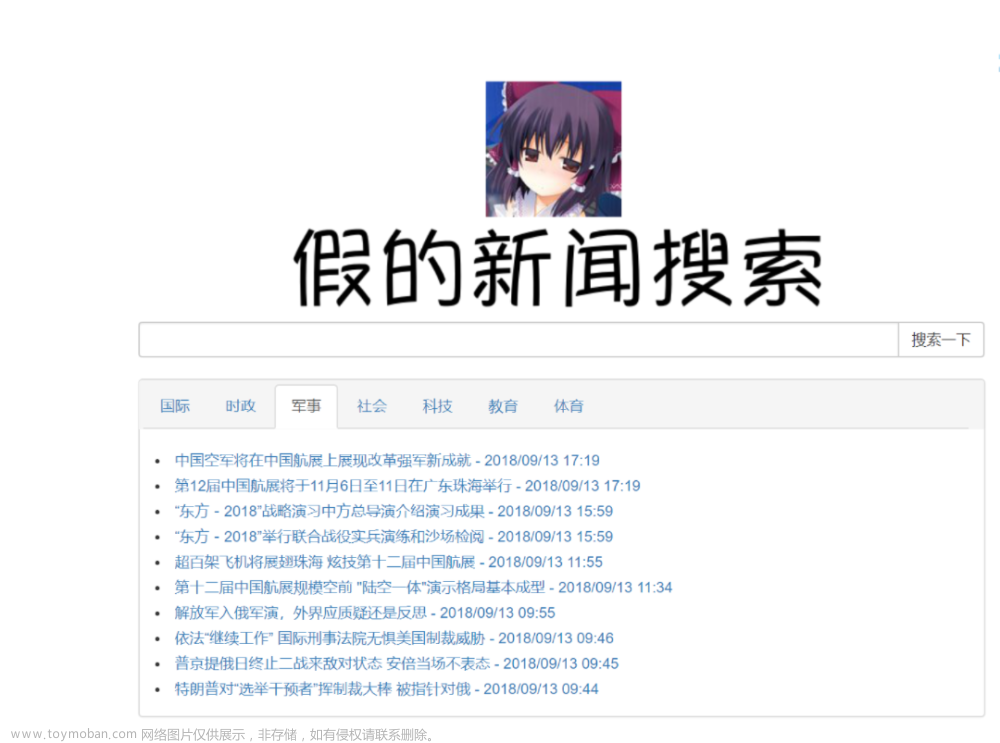
新闻搜索引擎信息展示界面。如图5.5

图5.5新闻搜索引擎展示界面
兴趣可视化分析信息展示界面。如图5.6

图5.6兴趣可视化分析展示界面
参考文献
[1]龙虹.信息爬取系统[M].北京理工大学出版社.2017.3.
[2]薛华成.数据可视化分析信息系统[M],北京:清华大学出版社,2016.
[3]刘超,唐彬.Python案例开发集锦[M],北京:电子工业出版社,2018.
[4]蒋宗礼,马涛,唐好魁,闫明霞等.数据可视化技术及应用(第2版)[M].电子工业出版社,2020:43-65.
[5]庭宝等.精通Python [M],北京:电子工业出版社,2018.
[6]艾伦(Grant Allen),欧文斯(Mike Owens),杨谦,刘义宣. Python权威指南(第2版)[M],电子工业出版社,2016(01):25-65.
[7]李盛恩,王珊.数据库基础与应用(第二版)[M].北京:人民邮电出版社,2017:14-78.
[8]曹岩,王海宇.Python应用程序开发实例应用于技巧(上基础篇)/21世纪工程应用计算机技术丛书[M],西安:西安交通大学出版社,2018.
[9]萨默菲尔德(Mark Summerfield),吴迪,戚彬,高波.python高级编程[M],电子工业出版社,2016(04):60-82.
[10]张雨. 融合用户聚类和协同过滤的新闻推荐系统设计与实现[D].山东师范大学,2019.
[11]陈思雯,刘海砚.面向网络新闻的爬虫开发与热点新闻事件分析[J].测绘与空间地理信息,2019,42(03):100-103+108.
[12]汤雪巧,许周腾.新闻自媒体采集系统的设计与实现[J].广播与电视技术,2019,46(02):29-32.
[13]Yoshifumi Seki,Mitsuo Yoshida 0001. Analysis of Bias in Gathering Information Between User Attributes in News Application.[J]. CoRR,2019,abs/1909.00554.
[14]左卫刚.基于Python的新闻聚合系统网络爬虫研究[J].长春师范大学学报,2018,37(12):29-33.
精力有限就写这么多,具体系统展示有视频链接。
目录
1 引言
1.1 1.1研究背景及意义
1.2 网络爬虫的发展现状
1.3 本课题主要工作
2 相关技术简介
2.1 Python简介
2.2 爬虫简介
2.3 PyEcharts
2.4 数据挖掘简介 7
3 系统分析
3.1 可行性分析
3.2 功能需求分析
3.3 系统性能分析
3.4 系统运行环境分析 1
4 系统设计
4.1 设计目标及原则
4.2 整体框架
4.3 系统流程设计
4.4 数据库实体
4.5 数据表设计
5 系统实现 16
5.1 信息爬取 16
5.2 系统实现界面
6 软件测试与分析
6.1 测试环境与测试条件 0
6.2 功能测试 20
6.3 性能测试 0
6.4 测试用例 1
6.5 系统运行情况 21
结 论 22
致 谢 23文章来源:https://www.toymoban.com/news/detail-745870.html
参考文献 24文章来源地址https://www.toymoban.com/news/detail-745870.html
到了这里,关于基于python的新闻搜索引擎设计与实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!