随着企业数据量呈现出爆炸式增长,跨部门、跨应用、跨平台的数据交互需求越来越频繁,传统的数据查询方式已经难以满足这些需求。同时,不同数据库系统之间的数据格式、查询语言等都存在差异,直接进行跨库查询十分困难。
原生跨库查询的局限性
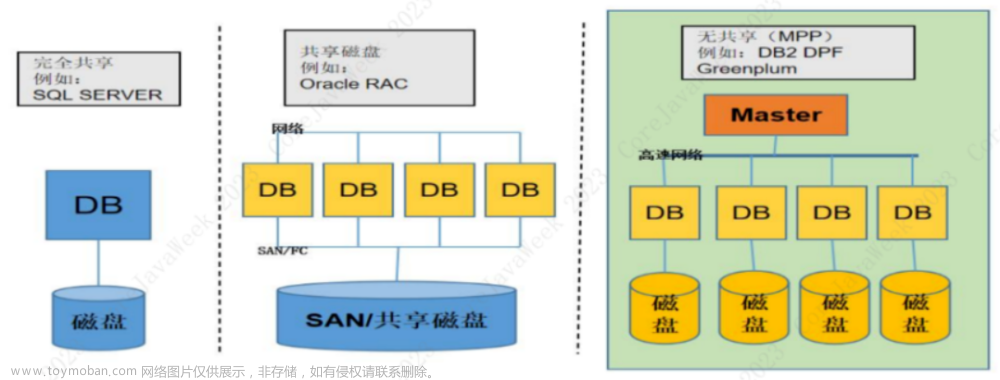
虽然 MySQL、Oracle、PostgreSQL 等数据库系统都提供了自身的跨库查询功能,但是存在诸多局限性:
- 数据库类型限制:MySQL 的 Federated、Oracle 的 Database Links 功能均要求目标数据库也必须是相同类型的数据库,这限制了跨库查询功能的适用范围,不适用于异构数据库的跨库查询。
- 额外性能损耗:自带的跨库查询功能可能会有 JOIN 操作带来的额外性能损耗,特别是在大规模数据查询或数据传输时,会增加系统负担,影响其他查询的效率。
这些局限性意味着数据库系统自带的跨库查询功能可能无法满足复杂多样的数据分析需求,特别是在异构数据库、大规模数据查询、有高性能高安全性方面需求等场景。
为解决这些问题,NineData DSQL 应运而生。
什么是 NineData DSQL ?
NineData DSQL 是针对多个同异构数据库系统进行跨库查询的功能,当前支持对表和视图进行 SELECT 操作。您可以在一个查询中访问多个数据库,获取分散在各个数据库中的有用信息,并且将这些信息聚合为一份查询结果返回,轻松实现跨多个库、多个数据源,乃至跨多个异构数据源的数据查询。
NineData DSQL 具有如下特性:
- 连接多个数据库系统:支持连接多个数据库系统,并确保这些数据库系统之间的兼容性。这些数据库系统可以来自不同的厂商或平台,且数据格式、存储方式、查询语言等可以存在差异。
- 统一的查询语法:DSQL 提供了统一的查询语法,您仅需使用一种语法即可跨多个异构或同构数据库进行查询,系统会自动将该语法解析并转换成不同类型数据源的查询语法进行下发查询。
- 结果整合和输出:整合同异构数据库系统的查询结果,并统一输出格式,方便您获取所需信息。您无需关心数据存储在哪个数据库中,只需通过一个查询就可以获得所需的结果。
- 数据隐私和安全保护:基于 NineData 的权限管控功能,支持对敏感数据进行脱敏处理、对访问权限进行控制等,保护数据的隐私和安全,防止数据泄露和非法访问。
- 图形化界面支持:提供一目了然的图形化界面,方便您进行可视化的查询和管理,提高您的工作效率。
易于记忆的 DSQL 查询语法
在 DSQL 中,无论是执行联表(视图)查询还是单表(视图)查询,指定来源数据源时都需要采用三段式语法,即<DBLINK 名称>.<库名|Schema 名>.<表名(视图名)>。
示例 1:跨异构源查询,从 DBLINK1(MySQL) 和 DBLINK2(Oracle) 中查询数据。
SELECT * FROM DBLINK1.database_name.table_name a, DBLINK2.schema_name.table_name b WHERE a.id=b.id;
示例 2:单表(视图)查询,从 DBLINK1 中查询数据。
SELECT * FROM DBLINK1.database.table_name WHERE id=1;
如果您的库名或表(视图)名以数字开头,或使用了预留字段,则需要使用双引号("")包裹该名称,否则查询失败。例如:
SELECT * FROM dblink_mysql_3451."9zdbtest3".sbtest1;
什么情况下需要使用 DSQL?
- 企业级数据整合:企业经常需要从多个部门或系统中整合数据,以提供更全面的视角。通过 DSQL ,企业可以在一个查询中访问多个数据库,获取分散在各个数据库中的有用信息,然后将其整合在一起,方便数据分析和决策。
- 数据挖掘与分析:数据挖掘和分析需要大量的数据支持。通过 DSQL ,您可以在多个数据库中检索需要的数据,然后使用挖掘和分析工具对数据进行深入的研究和分析。
- 数据仓库:数据仓库是用于存储和管理大量数据的系统。通过 DSQL ,您无需搭建数据仓库,即可实现数据仓库的功能。
操作示例
5.1 查看需要查询的库表列信息
您可以在左侧导航栏查看需要查询的 DBLink 名、库名|Schema 名、表名、视图名、列名等信息,无需摸黑操作。

查看需要查询的库表列信息
5.2 编写跨库查询语句并执行
通过简单的查询 SQL 即可对多个同、异构数据源进行查询,支持对查询结果中的敏感字段进行脱敏。

编写跨库查询语句并执行
5.3 整合多表查询结果并导出
执行跨库查询后,系统会整合查询结果到一张表中,您可以对结果集执行导出操作。同时,还支持对结果集进行搜索。

整合多表查询结果并导出
5.4 收藏常用 DBLink
如果 DBLink 很多,您可以收藏常用的几个 DBLink,方便查找。

收藏常用 DBLink文章来源:https://www.toymoban.com/news/detail-746102.html
综上所述,NineData DSQL 提供了全局视角审视您的数据,在减少了数据处理的复杂性的同时,提高了数据利用率,为企业提供了更灵活、高效和安全的方式来处理数据,可促进数据驱动的决策和业务发展,助力企业降本增效。文章来源地址https://www.toymoban.com/news/detail-746102.html
到了这里,关于NineData:通过一个SQL语句构建实时数仓的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![flink 实时数仓构建与开发[记录一些坑]](https://imgs.yssmx.com/Uploads/2024/02/601899-1.png)