本章将和大家分享 Elasticsearch 的一些基本概念。话不多说,下面我们直接进入主题。
一、什么是Lucene
Lucene是Apache的开源搜索引擎类库,提供了搜索引擎的核心API。
1、Lucene的优势:易扩展、高性能(基于倒排索引)
2、Lucene的缺点:只限于Java语言开发、学习曲线陡峭、不支持水平扩展
二、什么是Elasticsearch
Elasticsearch(简称ES)是一个开源的,分布式的全文搜索和分析引擎。它可以帮助我们从海量数据中快速找到需要的内容。
1、Elasticsearch 是基于 Lucene 开发的,相比与Lucene,Elasticsearch具备以下优势:支持分布式,可水平扩展;提供Restful接口,可被任何语言调用。
2、Elasticsearch 结合 Kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域。
3、Elasticsearch 是 elastic stack(ELK)的核心,负责存储、搜索、分析数据。

4、官网地址:https://www.elastic.co/cn/
三、什么是elastic stack(ELK)
是以Elasticsearch为核心的技术栈,包括Beats、Logstash、Kibana、Elasticsearch。
四、正向索引和倒排索引
1、什么是正向索引
正向索引:基于文档id创建索引。查询词条时必须先找到文档,而后判断是否包含词条。
传统数据库(如MySQL)采用正向索引,例如给下表(tb_goods)中的id创建索引:

这是我们传统的正向索引,如果通过索引id去做检索那效率就比较高,但是如果通过局部内容去做检索那效率就比较差了。
2、什么是文档和词条
文档(document):每一条数据就是一个文档
词条(term):对文档中的内容按照语义分词,得到的词语就是词条
3、什么是倒排索引
倒排索引:对文档内容分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条查询到文档id,而后获取到文档。
Elasticsearch采用倒排索引:
文档(document):每条数据就是一个文档
词条(term):文档按照语义分成的词语
例如:对 title 创建倒排索引

倒排索引在做存储的时候,它是将文档中的内容按照语义去分成不同的词条,然后再按照词条去做存储,关联文档id,建立起倒排索引。
搜索过程如下:

倒排索引的搜索过程是经过两次检索的,第一次是根据用户输入内容的词条去词条列表中进行寻找,找到对应的文档id,第二次则是拿着文档id去找文档。虽然经历了两次查找,但是每一次查找都是索引级别的查找,所以总体的查询效率是比较高的。
五、ES的基本概念
1、字段(Field)
字段:类似MySQL中的一个字段。
2、文档(Document)
文档:一条数据,用json格式表示。Elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在Elasticsearch中。

3、类型(Type)
类型:逐渐被弱化的概念,Type就像关系型数据库MySQL中的表,如用户表、商品表等。注意:在Elasticsearch7.x中,一个索引库下只有一张表,建表时不能给表取表名,默认表名为_doc。
4、索引(Index)
索引:相同类型文档的集合,类似MySQL数据库中的表。(由于Elasticsearch7.x版本之后,就删除了Type类型,默认Type就是_doc,不然ES中的索引库更像是MySQL中数据库的概念)
5、映射(Mapping)
映射:索引中文档的字段约束信息,类似表的结构约束

6、Query DSL
Query DSL:ES中提供了一种强大的检索数据方式,这种检索方式称之为Query DSL(Domain Specific Language)。DSL是Elasticsearch提供的JSON风格的请求语句,用来操作Elasticsearch,实现CRUD。
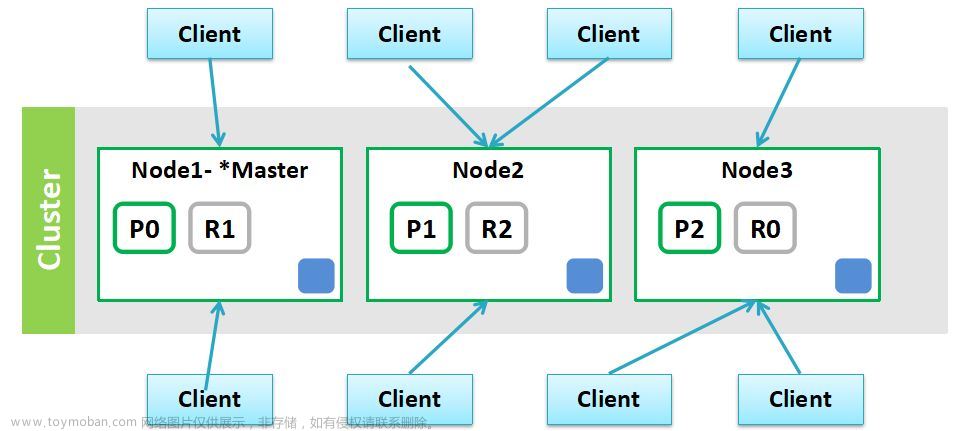
7、分片(shard)
分片:可以将一个Index中的数据切分为多个shard,然后存储到多台服务器上,以增大一个Index可以存储的数据量,加速检索能力,提升系统性能。
8、副本(replica)
副本:与shard存储的数据是相同的,起到备份作用。当shard发生故障时,可以从replica中读取数据,保证系统不受影响。
9、节点(node)
节点:单个Elasticsearch实例,一台机器可以有多个节点。节点名称默认随机分配。
10、集群(cluster)
集群:一组Elasticsearch实例,默认集群名称为 elasticsearch 。
11、概念对比
| MySQL | Elasticsearch | 说明 |
| Table | Index | 索引(Index),就是文档的集合,类似数据库的表(Table)。(由于Elasticsearch7.x版本之后,就删除了Type类型,默认Type就是_doc,不然ES中的索引库更像是MySQL中数据库的概念) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式。 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column)。 |
| Schema | Mapping | 映射(Mapping)是索引中对文档的约束,例如字段类型约束,类似数据库的表结构(Schema)。 |
| SQL | DSL | ES中提供了一种强大的检索数据方式,这种检索方式称之为Query DSL(Domain Specific Language)。DSL是Elasticsearch提供的JSON风格的请求语句,用来操作Elasticsearch,实现CRUD。 |
12、Elasticsearch与数据库的关系
MySQL:擅长事务类型操作,可以确保数据的安全和一致性。
Elasticsearch:擅长海量数据的搜索、分析、计算。

13、 元数据(Document MetaData)
元数据:用于标注文档的相关信息。
1)_index:文档所在的索引名
2)_type:文档所在的类型名,默认是_doc
3)_id:文档唯一id
4)_source:存储原始文档,文档的原始json数据,可从这里获取每个字段的内容
5)_all:整合所有字段内容到该字段,默认禁用
6)_score:得分
7)_version:版本
8)_seq_no:顺序号
六、ES中的数据类型
1、核心数据类型
1)字符串类型:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
2)数值类型:long、integer、short、byte、double、float、half_float、scaled_float
3)日期类型:date
4)布尔类型:boolean
5)二进制类型:binary
6)范围类型:integer_range、float_range、long_range、double_range、date_range
2、复杂数据类型
1)数组类型:array
2)对象类型:object
3)嵌套类型:nested object
3、地理位置数据类型
1)geo_point
2)geo_shape
4、专用类型
1)记录ip地址:ip
2)实现自动补全:completion
3)记录分词数:token_count
4)记录字符串hash值:murmur3
此文由博主精心撰写转载请保留此原文链接:https://www.cnblogs.com/xyh9039/p/17842159.html文章来源:https://www.toymoban.com/news/detail-746974.html
版权声明:如有雷同纯属巧合,如有侵权请及时联系本人修改,谢谢!!!文章来源地址https://www.toymoban.com/news/detail-746974.html
到了这里,关于Elasticsearch 系列(二)- ES的基本概念的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!