LSM-Tree
Doris的存储结构是类似LSM-Tree设计的,因此很多方面都是通用的,先阅读了解LSM相关的知识,再看Doris的底层存储与读取流程会清晰透彻很多,LSM基本知识如下:
原理:把各种数据先用log等形式组织在内存中(该数据结构称为MemTable,且有序);到达一定数据量后再批量merge写入磁盘(该数据结构称为SSTable);为压缩存储,会通过归并排序合并压缩SSTable。LSM主要是利用顺序写要比随机写更快速高效的原理,加上归并排序,合并压缩文件,提供更高效的数据存储与查询支持。
MemTable: 内存里的表,有序且存储在内存Buffer中;用有序数据结构来组织数据,一般是用跳表(SkipList),也可以是有序数组或红黑树等二叉搜索树。
SSTable: Sorted Strings Table; 由MemTable按SSTable文件格式刷入磁盘持久化存储,一般由一组数据block和一组元数据block组成,数据是已序的。元数据block会存储数据block的描述信息,如索引、BloomFilter、压缩、统计等信息;数据block存储数据。可以看作是一个有序的数组或有序链表。
Compaction: 通过归并排序算法,合并压缩SSTable。
LSM(Log-Structured Merge-Tree)是一种在分布式系统中常用的数据结构,用于高效地存储和检索大量数据。它结合了日志结构化(Log-Structured)和归并排序(Merge-Sort)的思想,通过将数据按照键的顺序合并存储,实现了高效的写入和读取操作。
其核心思想在于充分发挥磁盘连续读写的性能优势、以短时间的内存与 IO 的开销换取最大的写入性能,数据以 Append-only 的方式写入 Memtable、达到阈值后冻结 Memtable 并 Flush 为磁盘文件、再结合 Compaction 机制将多个小文件进行多路归并排序形成新的文件,最终实现数据的高效写入。
SSTable文件格式是一个很重要的信息;其包含存储与检索数据的数据结构设计,比如索引值,压缩算法,布隆过滤器等高效的设计。
参考:
LSM 树设计原理
LSM Tree索引:高性能写引擎
索引
官网文档: 索引概述.
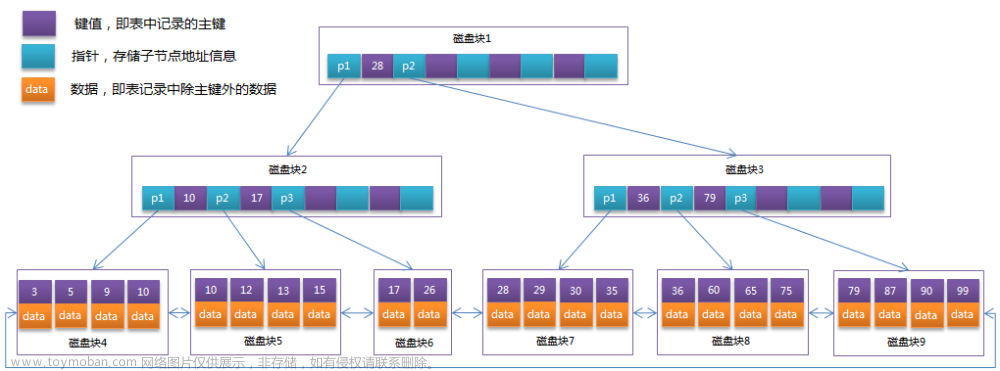
Doris内建的索引: 前缀索引(Short key Index)、ZoneMap索引,默认是根据建表时的key列生成的。
Doris 的数据存储在类似 SSTable(Sorted String Table)的数据结构中。该结构是一种有序的数据结构,可以按照指定的列进行排序存储。在这种数据结构上,以排序列作为条件进行查找,会非常的高效。
在 Aggregate、Unique 和 Duplicate 三种数据模型中。底层的数据存储,是按照各自建表语句中,AGGREGATE KEY、UNIQUE KEY 和 DUPLICATE KEY 中指定的列进行排序存储的。因此在此排序列的基础上根据不同的场景构建内置的索引,提高查询的性能与效率。
Duplicate、Aggregate、Unique 模型,都会在建表指定 key 列,然而实际上是有所区别的:对于 Duplicate 模型,表的key列, 可以认为只是 “排序列”,并非起到唯一标识的作用。而 Aggregate、Unique 模型这种聚合类型的表,key 列是兼顾 “排序列” 和 “唯一标识列”,是真正意义上的“ key 列”。
参考:
Apache Doris 索引机制解析
Doris-BE-存储结构设计解析
Join
官网文档: Doris Join 优化原理
概览
Doris 支持两种物理算子,一类是 Hash Join,另一类是 Nest Loop Join。
Doris 支持 4 种数据 Shuffle 方式:
-
BroadCast Join: 要求把右表全量的数据都发送到左表上,即每一个参与 Join 的节点,它都拥有右表全量的数据
-
Shuffle Join: 只支持hash join场景(即等值匹配). 当进行 Hash Join 时候,可以通过 Join 列计算对应的 Hash 值,并进行 Hash 分桶,并将分桶后的数据分散到节点中进行计算
-
Bucket Shuffle Join: 右表数据扫描出来之后进行数据分区的 Hash 计算,根据左表本身的数据分布发送到右表对应的 Join 计算节点上。
-
Colocation: 导入数据时,提前将join表的数据分散到一个节点
Runtime Filter
Doris 在进行 Hash Join 计算时会在右表构建一个哈希表,左表流式的通过右表的哈希表从而得出 Join 结果。而 RuntimeFilter 就是充分利用了右表的 Hash 表,在右表生成哈希表的时候,同时生成一个基于哈希表数据的一个过滤条件(Filter),然后下推到左表的数据扫描节点,通过这样的方式,左表在运行时(Runtime)提前进行数据过滤,提高查询效率。
Runtime Filter是分布式SQL查询引擎框架通用的一种优化手段,具体可参考: Join优化技术之Runtime Filter.
Runtime Filter涉及到的下推技术同样也是查询引擎框架常用的优化手段; 常见的下推优化技术有:谓词下推, 存储层下推等。
Doris支持的三种类型RuntimeFilter:
- IN 的优点是过滤效果明显,且快速。它的缺点首先第一个它只适用于 BroadCast,第二,它右表超过一定数据量的时候就失效了,当前 Doris 目前配置的是1024,即右表如果大于 1024,IN 的 Runtime Filter 就直接失效了,其余的RuntimeFileter则没有限制。
- MinMax 的优点是开销比较小。它的缺点就是对数值列还有比较好的效果,但对于非数值列,基本上就没什么效果。
- Bloom Filter 的特点就是通用,适用于各种类型、效果也比较好。缺点就是它的配置比较复杂并且计算较高。
使用场景的要求:
- 第一个要求就是左表大右表小,因为构建 Runtime Filter是需要承担计算成本的,包括一些内存的开销。
- 第二个要求就是左右表 Join 出来的结果很少,说明这个 Join 可以过滤掉左表的绝大部分数据。
Join Reorder
Join Reorder 是指在执行SQL查询时,决定多个表进行 join 的顺序。它是数据库查询优化的一个重要方面,对查询性能和效率有着重要的影响, 不同的 join order 对性能可能有数量级的影响。
从定义来看,其实就是寻找最短路径(最优解)的过程,因此可以从算法的角度考虑,比如动态规划算法与贪心算法;同时也可以基于规则来做。
Doris中Join Reorder的实现是基于规则策略的,其规则定义如下:文章来源:https://www.toymoban.com/news/detail-747359.html
- 让大表、跟小表尽量做 Join,它生成的中间结果是尽可能小的。
- 把有条件的 Join 表往前放,也就是说尽量让有条件的 Join 表进行过滤
- Hash Join 的优先级高于 Nest Loop Join,因为 Hash join 本身是比 Nest Loop Join 快很多的。
Join Reorder 也是SQL查询引擎框架通用的一种优化手段, 在PolarDB、TiDB、StarRocks等数据库框架中都有涉及与应用。其实现与说明如下:文章来源地址https://www.toymoban.com/news/detail-747359.html
- TiDB Join Reorder 算法简介
- StarRocks Join Reorder 源码解析
- PolarDB-X 优化器核心技术 ~ Join Reorder
到了这里,关于聊聊分布式 SQL 数据库Doris(七)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!