1. 什么是正则表达式?
正则表达式(regular expression,有时简写为RegEx 或 regex)就是用一组由字母和符号组成的“表达式”来描述一个特征,然后去验证另一个“字符串”是否符合/匹配这个特征。
2.应用场景?
(1)验证字符串是否符合指定特征,比如验证邮件地址是否符合特定要求等;
(2)用来查找字符串,从一个长的文本中查找符合指定特征的字符串;
(3)用来替换,比普通的替换更强大。
3.相应的模块--re
re模块是Python用来处理正则表达的模块,是Python处理文本的标准库。所谓的Python标准库,就是内置模块,不需要额外下载,使用时直接引入即可。
4.常用函数
| 类别 | 函数 | 用途 | 表达式 | remark |
| 查找一个匹配项 | re.search() | 查找任意位置的匹配项. | re.search(pattern,string,flags) |
search函数是在字符串中任意位置匹配,只要有符合正则表达式的字符串就匹配成功,即使有两个匹配项,search函数也只返回一个。 pattern: 正则表达式的字符串或原生字符串表示;string待匹配字符串;flags:正则表达式使用时的控制标记。 返回Match对象。 |
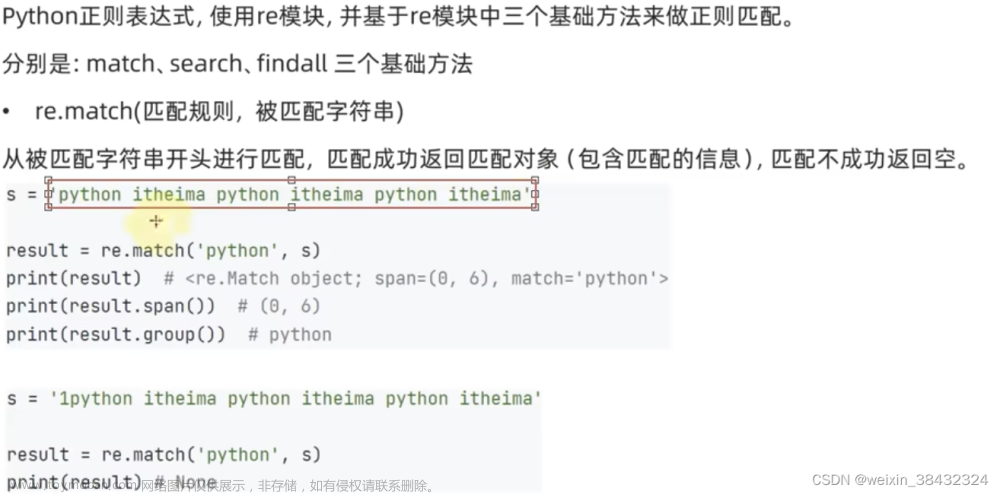
| re.match() | 必须从字符串开头匹配. | re.match(pattern,string,flags) |
match函数是要从头开始匹配,如果开头不一样,一定无法匹配。 从一个字符串的开始位置匹配正则表达式,返回Match对象。 pattern: 正则表达式的字符串或原生字符串表示;string待匹配字符串;flags:正则表达式使用时的控制标记。 返回Match对象。 |
|
| re.fullmatch() | 整个字符串与正则完全匹配. |
re.fullmatch(pattern,string,flags) |
fullmatch函数需要完全相同,匹配整个字符串,返回Match对象。不匹配时,返回None。 返回Match对象。 |
|
| 查找多个匹配项 | re.findall() | 从字符串任意位置查找,返回一个列表. |
re.findall(pattern,string,flags) 搜索字符串,以列表形式返回全部能匹配的子串。 返回列表类型。 |
两个方法基本类似,只不过一个是返回列表,一个是返回迭代器。列表是一次性生成在内存中,而迭代器是需要使用时一点一点生成出来的,内存使用更优。 |
| re.finditer() | 从字符串任意位置查找,返回一个迭代器. |
re.finditer(pattern,string,flags) 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是Match对象。 |
||
| 分割 | re.re.split() | 支持正则分割 | re.split(pattern, string, maxsplit=0, flags=0) |
函数:将一个字符串按照正则表达式匹配结果进行分割,返回列表类型。 用 pattern 分开 string , maxsplit表示最多进行分割次数, flags表示模式。 返回列表类型。 |
| 替换 | re.sub() | 支持正则替换 | re.sub(pattern, repl, string, count=0, flags=0) |
函数:在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串。 repl替换掉string中被pattern匹配的字符, count表示最大替换次数,flags表示正则表达式的常量。 |
| re.subn() | 支持正则替换 | re.subn(pattern, repl, string, count=0, flags=0) | 函数与 re.sub函数 功能一致,只不过返回一个元组 (字符串, 替换次数)。 | |
| 编译正则对象 | re.compile() | 编译正则表达式 | 返回Pattern对象。 |
将正则表达式的样式编译为一个 正则表达式对象 (正则对象Pattern),这个对象与re模块有同样的正则函数。template()增加了re.TEMPLATE 模式。 |
| re.template() | ||||
| 其他 | re.escape() | re.escape(pattern) | re.escape(pattern) 可以转义正则表达式中具有特殊含义的字符,比如:.或者 *。使用是,应小心转义符的问题。
|
|
| re.purge() | 清除正则表达式缓存 |
注意:查找一个匹配项(search、match、fullmatch)的函数返回值都是一个 匹配对象Match ,必须需要通过match.group() 获取匹配值。
5.什么是Match对象?有什么属性和方法?
在上面4的说明中,我们提到search、match、fullmatch函数的返回值是一个Match对象,这个对象中包含了很多匹配的信息。
| 类别 | 名称 | 解释 |
| 对象属性 | string | 待匹配的文本。 |
| re | 匹配时使用的Pattern对象(正则表达式) | |
| pos | 正则表达式搜索文本的开始位置。 | |
| endpos | 正则表达式搜索文本的结束位置。 | |
| 对象方法 | start() | 匹配字符串在原始字符串的开始位置。 |
| end() | 匹配字符串在原始字符串的结束位置。 | |
| span() | 匹配区域,返回(start(),end())。 | |
| group() | 获得匹配后的字符串。 | |
| groups() | 获取每部分匹配的字符串,元组类型。 |
注意group()和groups()的区别,一个是返回匹配的字符串,一个是返回各部分匹配内容组成的元组。
6.表达式中的控制标记flags
flags:正则表达式使用时的控制标记
| 常用标记 | 标记功能说明 |
|
re.I(re.IGNORECASE) |
re.I是正则表达式中的一个flag,用于忽略大小写。当我们想要匹配的字符串中包含大小写不敏感的内容时,可以使用这个flag。 例如,我们想要匹配字符串中的"apple",不论是大写还是小写,都可以使用re.I来实现。 |
| re.M(re.MULTILINE) |
re.M是正则表达式中的另一个flag,用于多行匹配。通常情况下,正则表达式默认只匹配字符串中的一行内容,但是当我们需要匹配多行内容时,就可以使用re.M。 例如,我们想要匹配字符串中的以数字开头的所有行,就可以使用re.M。 |
| re.S(re.DOTALL) | re.S是正则表达式中的一个flag,用于匹配任意字符,包括换行符。如不设置re.DOTALL这个Flag标识位,符号“.”匹配除换行符外的一切。而一旦设置了这个标识位,符号“.”将啥都匹配。 |
| re.X(re.VERBOSE) |
忽略空白,提高可读性。当该标志被指定时,在 RE 字符串中的空白符被忽略,除非该空白符在字符类中或在反斜杠之后。它也可以允许你将注释写入 RE,这些注释会被引擎忽略;注释用 “#”号 来标识,不过该符号不能在字符串或反斜杠之后。 |
7.在表达式中强调开始\结束位置的特殊字符
| 表达式用到的特殊字符 | 说明 | 举例 |
| ^ | 与字符串开始的地方匹配,此字符不匹配任何字符. | 表达式 "^aaa" 在匹配 "xxxaaaxxx" 时,匹配失败。只有当 "aaa" 位于字符串的开头的时候,"^aaa" 才能匹配,如:"aaaxxxxxx"。 |
| $ | 与字符串结束的地方匹配,此字符不匹配任何字符. | 达式 "aaa$"在匹配 "xxxaaaxxx" 时,匹配失败。只有当"aaa"位于字符串的结尾的时候,"aaa$"才能匹配,比如:"xxxxxxaaa"。 |
8.表达式中的转义符(\)
一些不便书写的字符和特殊用处的标点符号,采用在前面加“\” (转义符).
| 表达式 | 可匹配 | 表达式 | 可匹配 |
| \n | 匹配换行符 | \? | 匹配?符号本身 |
| \t | 匹配制表符 | \* | 匹配*符号本身 |
| \\ | 匹配\符号本身 | \+ | 匹配+符号本身 |
| \^ | 匹配^符号本身 | \{、\} | 匹配大括号 |
| \$ | 匹配$符号本身 | \[、\] | 匹配中括号 |
| \. | 匹配.符号本身 | \(、\) | 匹配小括号 |
9.能够与 '多种字符' 匹配的表达式
正则表达式中的一些表示方法,可以匹配 ‘多种字符’ 中的任意一个字符。例如,表达式"\d" 可以匹配任意一个数字。虽然可以匹配其中任意字符,但是只能是一个,不是多个。
| 表达式 | 匹配功能 |
| \d | 任意一个数字,0~9中的任意一个 |
| \w | 任意一个字母或数字或下划线,也就是A~Z,a-z,0-9,_中任意一个 |
| \s | 包括空格\制表符\换页符等空白符的其中的任意一个 |
| . | 小数点可以匹配除了换行符(\n)以外的任意一个字符 |
10.表达匹配次数
| 表达式 | 匹配功能 | 例子 |
| {n} | 表达式重复n次 | 例如:"\w{2}"相当于"\w\w";"a{5}"相当于"aaaaa" |
| {m,n} | 表达式至少重复m次,最多重复n次 | 例如:"ba{1,3}" 可以匹配"ba"或"baa"或"baaa" |
| {m,} | 表达式至少重复m次 | 例如:"\w\d{2,}"可以匹配"a12","_456","M12344" |
| ? | 匹配表达式0次或1次,相当于{0,1} | 例如:"a[cd]?"可以匹配"a","ac","ad" |
| + | 表达式至少出现1次,相当于{1,} | 例如:"a+b" 可以匹配"ab","aab","aaab" |
| * | 表达式不出现或出现任意次数,相当于{0,} | 例如:"\^*b"可以匹配"b","^^^b" |
11.借助[]和^自定义匹配关系
使用方括号 [ ] 包含一系列字符,能匹配其中任意一个字符。用 [^ ] 包含一系列字符,则能匹配其中字符之外的任意一个字符。
| 表达式案例 | 匹配功能 |
| [abc5@] | 匹配"a"或"b"或"5"或"@" |
| [^abc] | 匹配"a","b","c"之外的任意一个字符 |
| [f-k] | 匹配"f"~"k"之间的任意一个字符 |
| [^A-F0-3] | 匹配"A"~"F","0"~"3"之外的任意一个字符。 |
注意:虽然可以匹配其中任意一个,但是只能是一个,不是多个。
12.字符串中关于IP的正则表达式
##字符串中关于IP地址的正则表达式 ## ^:匹配字符串的开头。((25[0-5]|2[0-4]\d|[01]?\d\d?)\.):匹配一个数字和一个点号,这个数字的取值范围是0到255。 ## {3}:匹配前面的表达式三次。(25[0-5]|2[0-4]\d|[01]?\d\d?): 配一个数字,这个数字的取值范围是0到255。$:匹配字符串的结尾。 ## 使用正则表达式匹配IP地址 # 字符串是IP地址 ip_pattern = r'^((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)$' ##字符串是IP地址开头的 ipstart_pattern = r'^((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)' ##字符串包含IP ipcontain_pattern = r'((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)' ##字符串包含IP,并且IP地址是以': ['字符开头,以']'字符结尾 ipcontain_pattern_plus = r'(\: \[)((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}((25[0-5]|2[0-4]\d|[01]?\d\d?)\])'
参考网址
https://zhuanlan.zhihu.com/p/479731754
https://zhuanlan.zhihu.com/p/127807805
https://www.bilibili.com/read/cv25901174/?jump_opus=1文章来源:https://www.toymoban.com/news/detail-747842.html
https://www.bilibili.com/video/BV1TJ411Y7JX?p=156文章来源地址https://www.toymoban.com/news/detail-747842.html
到了这里,关于Python正则表达式(小结)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!