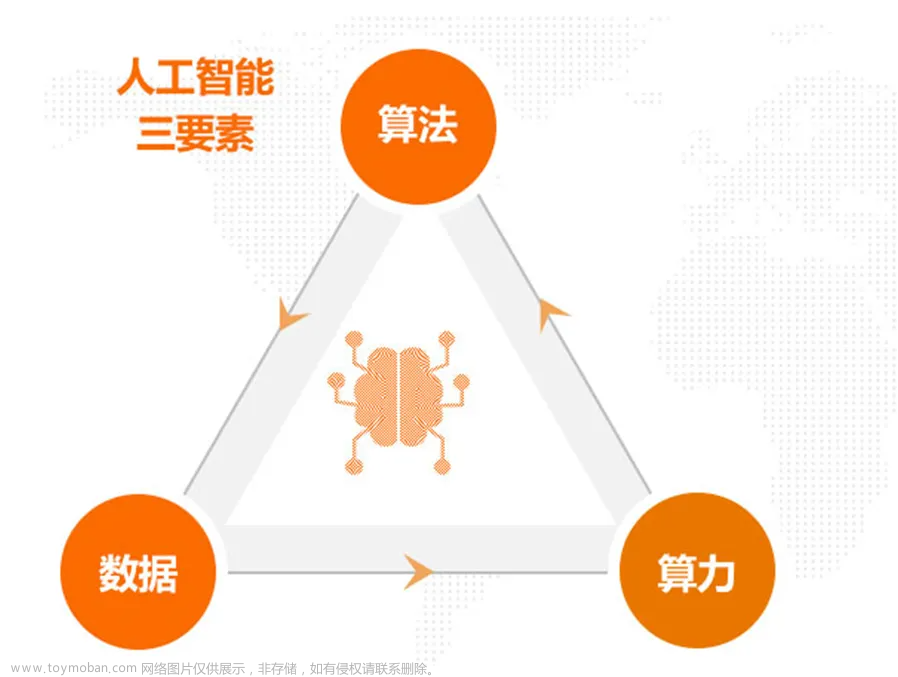
引言
在开始开发之前,我们首先要了解我们将会接触到的编程语言和组件。我本身是一名Java开发者,虽然也有接触过C、C++和PHP开发语言,但在工作中使用的并不多。因此,为了本次开发,我们选择了Python作为开发语言。大家都是从零开始,只要你有编程知识,就可以和我一起学习。回顾一下我们需要开发的简易版架构图:

前置知识
接下来,我们来看一下我们需要用到的知识点:Python 3.10版本、Git、Embedding、Hugging Face、Milvus、Langchain、OpenAI和Docker Desktop。在开发过程中,我们将使用Visual Studio Code作为客户端,并安装以下插件:Dev Container和Jupyter。请牢记这些内容,它们都是我们开发中需要使用到的,这样你就能对开发这个知识库有一个清晰的认识了。
需要掌握
Python:选择Python 3.10版本是因为我在尝试最新版本时遇到了一些报错,所以我决定降低版本,以确保开发过程尽可能顺利。个人而言,我发现Python具有简洁而优雅的语法,且具备广泛的应用领域,从数据分析到机器学习都可以使用它进行开发。
Git:如果你只是在本地运行代码而不需要与他人协作,那么可能不需要使用Git。然而,作为一个团队开发工具,Git提供了版本控制和协作功能,可以让多个开发者在同一个项目中进行并行开发,非常方便。
Docker:我对Docker有较多的接触,所以在这个项目中使用了它。Docker是一个开源的容器化平台,可以通过容器化技术将应用程序和其依赖项打包成一个独立的可移植镜像。使用Docker可以提供一致的开发环境,并且能够轻松部署到不同的服务器上。
Embedding:嵌入是一种常见的机器学习技术,它可以将高维的数据映射到低维空间中,从而提取出数据中的有用特征。在这个项目中,我们可能会使用嵌入技术来处理文本或图像数据,以便进行后续的分析和处理。
Hugging Face:Hugging Face是一个活跃的开源社区,提供了许多预训练的模型和工具,可以用于文本生成、情感分析、问答系统等任务。在这个项目中,我们会利用Hugging Face的提供的向量模型来实现一些自然语言处理的功能。
Milvus:Milvus是一个开源的向量数据库,专门用于存储和查询大规模的向量数据。它提供了高效的相似度搜索和索引构建功能,适用于许多机器学习和数据挖掘任务。在这个项目中,我们会使用Milvus来存储和查询某些向量数据。就跟我们的MySQL数据库是一样的,只不过他存储的是向量,而不是我们的字段数据。
Langchain:当谈到Langchain时,我认为它类似于Java的SDK包或者是util类,它封装了许多API供我们调用。它的一个显著特点是简单且具有高可读性。这意味着我们可以轻松地使用Langchain提供的API来实现特定功能,而不需要花费大量的时间去编写复杂的代码。这样,我们可以更专注于业务逻辑的实现,而不用过多关注底层实现细节。同时,由于API的可读性高,我们能够更容易地理解和使用Langchain中提供的各种功能。
OpenAI:它确实是一个非常强大的平台。在语言模型中,OpenAI训练的模型表现非常出色,能够提供非常接近实际的回答。这对于聊天机器人、智能助手等应用非常有价值。通过使用OpenAI的模型,我们可以得到更准确和自然的回答,总的来说,OpenAI在自然语言处理领域的技术实力不容小觑,对于语言相关的应用开发具有巨大的帮助和潜力。
项目简易结构
下面是我们的目录结构示例,以简单的业务开发流程为基础,你可以根据实际需求进行优化:

.devcontainer:这个文件夹是用来在Visual Studio Code中进行Docker开发的。里面包含一个json文件,用于指定如何构建Docker容器。
.venv:这个文件夹是运行时自动生成的,用于存放运行时编译生成的Python虚拟环境。我们不需要手动创建或管理它。
volumes:这个文件夹也是在运行时自动生成的,用于存放运行时编译生成的数据卷。我们不需要手动创建或管理它。
.env:这个文件用于定义环境变量。
.gitattributes:这个文件用于定义Git提交时的一些属性。
.gitignore:这个文件用于定义哪些文件或文件夹不应该被提交到Git仓库中。
docker-compose.yaml:这个文件用于定义多个Docker容器的编排配置。
Dockerfile:这个文件用于将当前项目编译成Docker镜像。
main.py:这个文件是我们实际运行的Python代码。
pyproject.toml:由于Python包的安装对版本依赖性较强,我们使用了Poetry工具来管理依赖项的安装,而不是使用传统的pip命令。
README.md:这个文件是一个Markdown文件,用于介绍我们的项目,但是对于项目开发来说不是必需的。
requirements.txt:这个文件用于定义需要安装的Python依赖包,我们这次不使用它。
untitled.ipynb:这个文件是一个Jupyter Notebook文件,类似于我们的调试器模型,但是它是逐段执行的。我们稍后可以仔细研究它。
下面的一个Python文件是我用来进行测试的,你们不需要关注它。文章来源:https://www.toymoban.com/news/detail-748549.html
总结
在这个项目中,我们将使用Python作为开发语言,结合Hugging Face、Milvus、Langchain、OpenAI等工具和技术,实现一个简易版的架构图。通过嵌入技术处理文本和图像数据,利用Hugging Face的预训练模型进行自然语言处理,使用Milvus作为向量数据库进行存储和查询。同时,我们还会使用Langchain提供的API来简化开发流程,并借助OpenAI的强大功能实现更准确和自然的回答。这个项目将帮助我们深入了解各种技术和工具的使用,并提供一个清晰的业务开发流程。文章来源地址https://www.toymoban.com/news/detail-748549.html
到了这里,关于探索人工智能的世界:构建智能问答系统之前置篇的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!