一、Flink State 概念
State 用于记录 Flink 应用在运行过程中,算子的中间计算结果或者元数据信息。运行中的 Flink 应用如果需要上次计算结果进行处理的,则需要使用状态存储中间计算结果。如 Join、窗口聚合场景。
Flink 应用运行中会保存状态信息到 State 对象实例中,State 对象实例通过 StateBackend 实现将相关数据存储到 FS 文件系统或者 RocksDB 数据库中。在Flink应用运行过程中,通过 checkpoint 快照定期地保存状态数据。并在 Flink 应用重启时加载checkpoint/savepoint 来实现状态的恢复,从而让 Flink 应用继续完成之前的数据计算,实现数据精确一次向下游传递。
1.1 Apache Flink 中 State 的存储实现 StateBackend 分类
分为以下3类:
- 基于内存的 HeapStateBackend。状态存储在内存中。
- 基于 HDFS 或 OSS 的 FsStateBackend。状态存储在内存,并在做 cp(checkpoint)时存到远端。
- 基于 RocksDB 的 RocksDBStateBackend。将对象序列化成二进制存在内存和本地磁盘的 RocksDB 数据中,并在 cp 时存到远端。
HeapStateBackend 和 RocksDBStateBackend 分别对应在 TaskManager 内存模型中的位置:
RocksDBStateBackend 中存储结构:
namespace: 在不同的 namespace 下存在相同名称的状态。
1.1.1 State 状态持久化
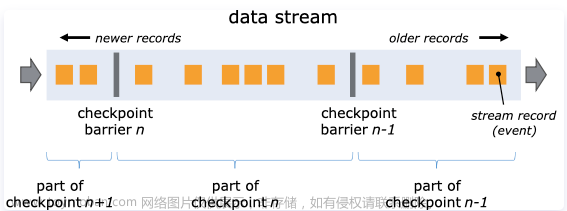
通过 Chandy-Lamport 分布式快照算法进行 checkpoint 完成状态数据的持久化。然后在 Flink 应用重启时读取 State 状态数据,进行运行现场的还原。
chekcpoint 分类:
- 基于内存的全量 checkpoint
- HDFS 全量 checkpoint
- RocksDB 全量 checkpoint/增量 checkpoint
1.2 State 基于算子和数据分组的分类
State 可分为 Operator State 和 Keyed State 两类。
- Operator State(称为 non-keyed state)
常常存在于Source, Sink中。具体实现类例如:
- BroadcastState
例:Kafka Source 中用 OperatorState 记录 offset。
- Keyed State
任何类型的 keyed state 都可以有有效期(TTL),所有状态类型都支持单元素的 TTL。 这意味着 List 元素和 Map 映射元素将独立到期。
例:SQL GroupBy/PartitionBy 后的窗口中的数据,每个 key 都有对应的 State。key 与 key 之间的 State 数据不可见。
keyed state 的具体实现类:
- ValueState
- MapState
- ListState
- AggregatingState
- ReducingState
- 。。。。。
Flink State思维导图:
| Keyed State | Operator State | |
|---|---|---|
| 适用算子类型 | 只适用于KeyedStream上的算子 | 可用于所有算子 |
| 状态分配 | 每个Key对应一个状态 | 一个算子子任务对应一个状态 |
| 横向扩展 | 状态随着keyBy的分组KeyGroup自动在多个算子子任务上迁移 | 有多种状态重新分配的方式 |
| 创建和访问方式 | 自定义算子(重写RichFunction,通过State 名称从 getRuntimeContext方法创建或获得 State ) | 实现 CheckpointedFunction 等接口 |
| 支持数据结构 | ValueState、ListState、MapState等 | ListState、BroadcastState等 |
二、常见状态相关处理流程
2.1 Flink 应用中状态是如何存储的?
1. Kafka Source 如何存储 OperatorState?
class FlinkKafkaConsumerBase {
private transient ListState<Tuple2<KafkaTopicPartition, Long>> unionOffsetStates; // state名称:"topic-partition-offset-states"
// 特殊的State类型:Union State
}
unionOffsetStates这个变量就是 OperatorState类型的。
2. Map算子如何存储需要累计的数据?
- ValueState/MapState/ListState/......
思考:keyby 后的数据分发与多并行度 subtask 之间的关系是怎样的?
首先,datastream 中数据经过 keyby 之后,会划分到各个 KeyedStream 中。每个 KeyedStream 有自己的 KeyedState(如ValueState/ListState/MapState)。
其次,KeyedStream 中的数据会以 KeyGroup 方式组织在一起。KeyGroup 是 Flink 重新分发 key state 的最小单元。
最后,KeyGroup 中的数据会通过取模最大并行度的方式分散到各个 subtask 中。以下是关键源码:
KeyGroupStreamPartitioner#selectChannel(record)
{
K key;
key = keySelector.getKey(record.getInstance().getValue());
return KeyGroupRangeAssignment.assignKeyToParallelOperator(
key, maxParallelism, numberOfChannels);
}
--KeyGroupRangeAssignment#assignKeyToParallelOperator()
{
return computeOperatorIndexForKeyGroup(maxParallelism, parallelism, assignToKeyGroup(key, maxParallelism));
}
--KeyGroupRangeAssignment#computeOperatorIndexForKeyGroup()
公式:OperatorIndex = keyGroupId * parallelism / maxParallelism
--KeyGroupRangeAssignment#assignToKeyGroup()
{
return computeKeyGroupForKeyHash(key.hashCode(), maxParallelism);
}
2.2 修改并行度场景时 State 状态存储的变化
2.3 State 与 Checkpoint 关系
分布式快照 Checkpoint 的概念,定期将 State 持久化到 外部存储系统(HDFS/OSS) 上。用户可以通过实现 CheckpointedFunction 接口来使用 operator state。通过 barrier 来对齐 checkpoint,等待 State 持久化完成(此过程参数不同也可能是异步的)。
常见 State 与 CP 相关的问题:
- State 状态过大。现象为多个算子或单个算子多个 subtask 做 checkpoint 慢,可导致 CP 对齐时间长,严重时会导致 CP 超时。
- 数据倾斜导致某个 subtask 处理不及时。现象为单个算子少数几个 subtask 做 checkpoint 慢,导致 CP 对齐时间长。严重时会导致 CP 超时。
- 大作业(并行度搞)频繁做 CP,会频繁上传小文件,导致 HDFS 集群小文件过多。
常用解决措施:调大托管内存大小。
三、参考文档:
- Flink State 官方文档:Flink 状态与容错
- https://cloud.tencent.com/developer/article/1403939
- https://www.modb.pro/db/81206
作者:京东物流 吴云涛文章来源:https://www.toymoban.com/news/detail-748909.html
来源:京东云开发者社区 自猿其说Tech 转载请注明来源文章来源地址https://www.toymoban.com/news/detail-748909.html
到了这里,关于Flink State 状态原理解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![状态设计模式(State Pattern)[论点:概念、相关角色、图示、示例代码、框架中的运用、适用场景]](https://imgs.yssmx.com/Uploads/2024/01/413279-1.png)