文章来源:https://www.toymoban.com/news/detail-749852.html
文章来源:https://www.toymoban.com/news/detail-749852.html
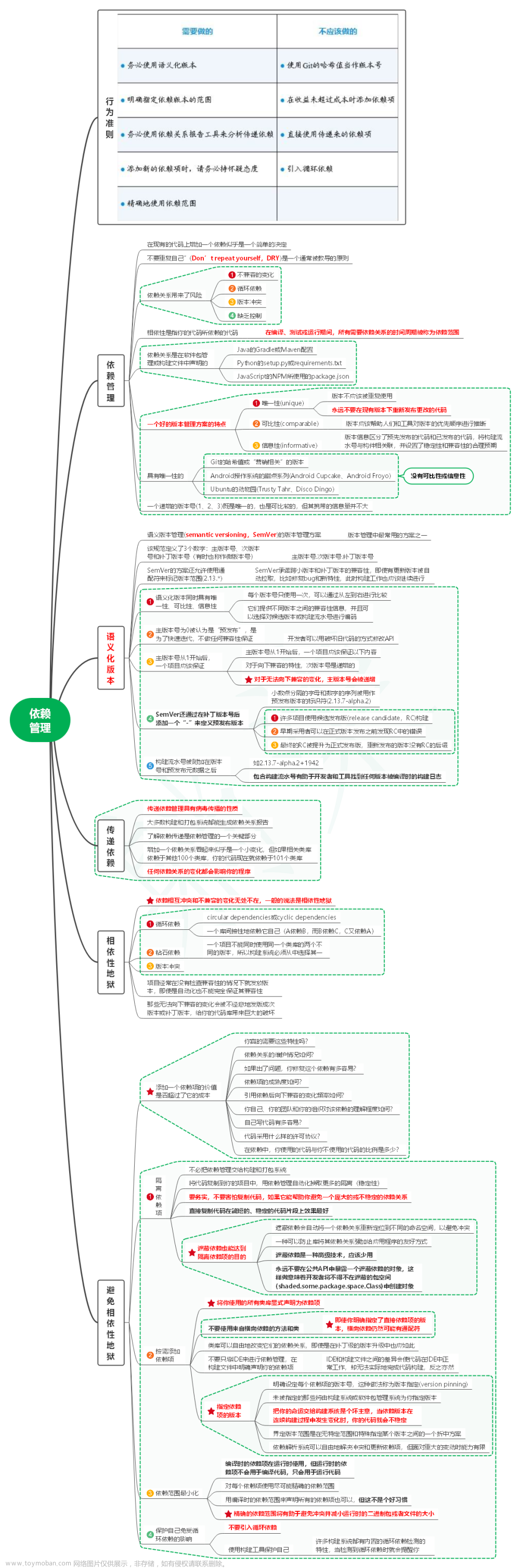
1. 行为准则
 文章来源地址https://www.toymoban.com/news/detail-749852.html
文章来源地址https://www.toymoban.com/news/detail-749852.html
2. 日志分级
2.1. 日志框架设有日志级别,它可以让运维人员根据重要性过滤消息
2.2. 编程语言有精良的日志类库,让运维人员对要记录的内容和时间有更多的控制
2.3. TRACE
2.3.1. 一个极其精细的日志级别
2.3.2. 对特定的包或类开放
2.3.3. 在开发阶段之外很少使用这个级别
2.4. DEBUG
2.4.1. 多用于那些只在调查产品出故障时有用
2.4.2. 在正常操作中没有用的日志
2.5. INFO
2.5.1. 一般用于输出应用程序运转良好的日志
2.5.2. 不应该用于输出任何问题的指示
2.6. WARN
2.6.1. 一般用于提示那些潜在问题
2.6.2. 一个资源已经接近其容量上限,就应该是一个WARN
2.7. ERROR
2.7.1. 表明正在发生需要注意的错误
2.8. FATAL
2.8.1. 如果程序遇到非常严重的情况,必须立即退出,就可以在FATAL级别上记录关于问题原因的信息
2.8.2. 包括该程序状态的上下文内容,恢复或诊断相关数据的位置也应该被记录下来
3. 日志的原子性
3.1. 如果某些信息只有在与其他数据配合时才有用,那么就应该把所有相关内容“原子化地”记录到一条消息中
3.2. 如果日志信息不能以原子化的方式输出,可以在消息中放置唯一的ID,这样日志信息就可以在后续的处理中被拼接起来
3.3. 不要假设日志会按照特定的顺序被看到,许多操作工具会重新排序,甚至弃用一些消息
3.4. 不要依赖系统的时间戳来排序,系统时钟可能被重置或来自不同的主机,从而造成日志信息难以理解
3.5. 避免在日志信息中使用折行,许多日志聚合器会把每一个新行当作一串单独的消息
3.5.1. 要特别确保堆栈跟踪被记录在一条消息中,因为它们在输出时经常包含折行
4. 日志性能
4.1. 过度的日志记录会损害性能
4.2. 日志必须被写入像磁盘、控制台或者某个远程系统这样的地方
4.3. 在写入日志前,要记得处理好字符串的拼接和格式化
4.4. 用参数化的日志输入及异步附加器来保持快速记录日志
4.5. 改变日志的冗余度和配置可以消除竞争条件和bug
4.5.1. 因为它降低了应用程序的速度
4.5.2. 如果你启用冗余的日志等级来调试一个问题,并发现一个bug消失了,日志等级的变化本身可能就是原因
5. 不要记录敏感数据
5.1. 日志信息不应该包括任何私人数据
5.1.1. 密码
5.1.2. 安全令牌
5.1.3. 信用卡号码
5.1.4. 电子邮件地址
5.2. 大多数框架支持基于规则的字符串替换和编辑,要配置它们,但不要依赖它们作为你的唯一防护手段
6. 系统监控
6.1. 常见的系统指标类型
6.1.1. 计数器
6.1.1.1. 测量的是某个事件发生的次数
6.1.1.2. 通过使用计数器获得缓存命中数和请求总数,你就可以计算出缓存命中率
6.1.2. 仪表盘
6.1.2.1. 一个基于时间点的测量值
6.1.2.2. 既可以上升又可以下降
6.1.3. 直方图
6.1.3.1. 根据事件的大小幅度分成不同的范围
6.1.3.2. 每一个范围都会有一个计数器,每当某事件的值落入其范围时,计数器就会递增
6.1.3.3. 通常用来测量请求所需的时间或数据有效负载的长度
6.2. 系统性能通常以阈值百分比的形式来衡量
6.2.1. 从0%到99%,被称为P99
6.3. 集中式可视化系统
6.3.1. Datadog
6.3.2. LogicMonitor
6.3.3. Prometheus
6.4. 使用标准的监控组件
6.4.1. 标准库可以与其他一切“开箱即用”的东西集成
6.5. 测量一切
6.5.1. 监测的性能开销很低,你应该广泛地使用这些监测数据
6.5.2. 抽样可以保持快速的性能,减少磁盘和内存的使用,但它也会使测量的准确性降低
6.5.3. 资源池
6.5.3.1. 资源池使用过大表明系统此刻的响应很卡顿或无法跟上需求速度
6.5.4. 缓存
6.5.4.1. 计算高速缓存的命中数和失误数,两者比率的变化会影响应用程序的性能
6.5.5. 数据结构
6.5.5.1. 数据结构大小的异样表明正在发生一些奇怪的事情
6.5.6. CPU密集型操作
6.5.6.1. 序列化是一个昂贵的、CPU密集型的操作,所以它花费的时间应该被记录下来
6.5.7. I/O密集型操作
6.5.7.1. 磁盘和网络I/O操作是缓慢和不可预知的,使用计时器来监测它们所需的时间
6.5.8. 数据大小
6.5.9. 异常和错误
6.5.9.1. 计算异常、错误响应代码和不良输入的次数,监测错误的出现频率可以在出错时很容易触发警报
6.5.10. 远程请求和响应
7. 跟踪器
7.1. RPC客户端会使用一个跟踪库,在他们的请求上附加一个调用跟踪ID
7.2. 调用跟踪ID通常通过RPC客户端包装器和服务网格自动为你传播,用来验证你在调用其他服务时是否传播了任何需要的状态
7.3. 分布式调用跟踪
7.3.1. 对上游API的一次调用可能会导致对下游的数百次不同服务的RPC调用
7.3.2. 分布式调用跟踪将所有这些下游调用连接成一个图
7.3.3. 分布式跟踪对于调试错误、监测性能、理解依赖关系和分析系统成本都很有用
7.3.3.1. 哪些API的服务成本最高、哪些消费者线程成本最高等
8. 配置
8.1. 应用程序和服务应该暴露出配置信息,并允许开发人员或网站稳定性工程师(site reliability engineers,SRE)配置运行时的行为
8.2. 表达方式
8.2.1. 普通的、对人友好的格式的文件
8.2.1.1. INI
8.2.1.2. JSON
8.2.1.3. YAML
8.2.2. 环境变量
8.2.3. 命令行参数
8.2.4. 最常见
8.2.5. 定制的领域特定语言(DSL)
8.2.6. 应用程序所使用的语言
8.3. 不要太有创意,要使用标准的配置格式,提供合理的默认值,校验配置的输入值,并尽可能地避免动态配置
8.3.1. 配置无须新花样
8.3.2. 记录并校验所有的配置
8.3.3. 提供默认值
8.3.3.1. 如果用户不得不配置大量的参数,你的系统将很难运行起来
8.3.3.2. 提供良好的默认值,这样你的应用程序对大多数用户来说开箱即用
8.3.4. 给配置分组
8.3.4.1. 将相关属性分组,这样就更容易组织和维护配置信息
8.3.4.2. 应用程序配置很容易变得难以管理,特别是不支持嵌套语法的键值格式
8.3.4.3. 可以使用像YAML这样允许嵌套的标准格式
8.3.5. 将配置视为代码
8.3.5.1. 配置即代码(configuration as code,CAC)的哲学认为,配置应该受到与代码同样严格的要求
8.3.5.2. 配置错误可能是灾难性的,一个错误的整数或缺失的参数就可以毁掉一个应用程序
8.3.5.3. 为了保证配置变化的安全,配置应该被版本控制、评审、测试、构建和发布
8.3.5.3.1. 将配置保存在像Git这样的VCS中,这样你就有了变更的历史
8.3.5.3.2. 像评审代码一样评审配置的变化,验证配置的格式是否正确、是否符合预期的类型和配置的值是否在理论范围内,构建和发布配置包
8.3.6. 保持配置文件清爽
8.3.6.1. 干净、清爽的配置对其他人来说更容易理解和改变
8.3.6.2. 删除不使用的配置,使用标准的格式和间距,不要盲目地从其他文件中复制配置
8.3.7. 不要编辑已经部署的配置
9. 工具集
9.1. 编写工具是协作性的
9.2. SRE通常会喜欢基于命令行界面(command line interface,CLI)的工具和自描述的API
9.2.1. 它们很容易脚本化,脚本化的工具很容易实现自动化
到了这里,关于读程序员的README笔记05_日志、监控与配置的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!