一、爬取目标
大家好,我是盆子。今天这篇文章来讲解一下:使用Java爬虫爬取百度搜索结果。
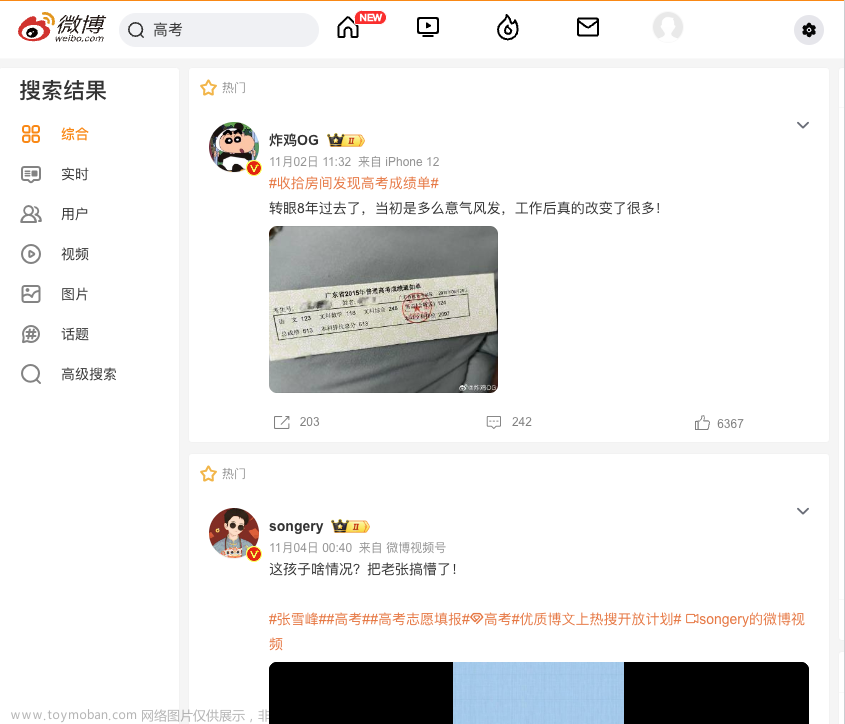
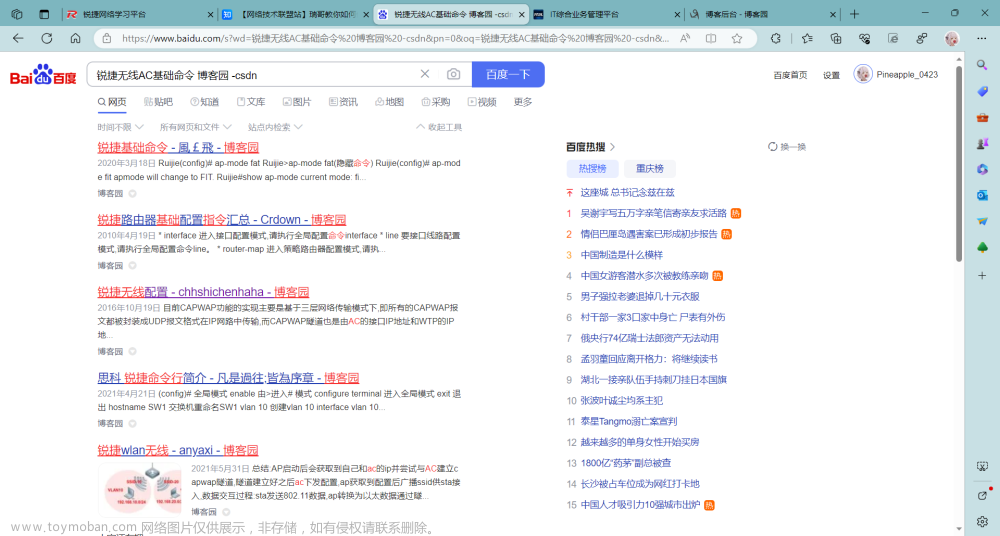
首先,展示爬取的数据,如下图。
爬取结果1:

爬取结果2:

代码爬取展示:

可以看到,上面爬取了五个字段,包括
标题,原文链接地址,链接来源,简介信息,发布时间。
二、爬取分析
用到的技术栈,主要有这些
Puppeteer 网页自动化工具
Jsoup 浏览器元素解析器
Mybatis-Plus 数据库存储
2.1 网页结构分析
打开百度搜索,搜索“手机”二字,可以看到下面这样的搜索结果,我们需要爬的信息都在上面。
爬取网页元素分析1:*
*尝试去分析它的网页结构:

爬取网页元素分析2:

打开控制台F12,可以看到这个 class =“result c-container xpath-log new-pmd” 所在的 div 标签就包含我们要爬取的所有信息。
那就很简单了,我们只需要去这个div里面,将需要的元素 (字段) 信息挨个的获取即可。
同理,这个结构也就是百度搜索结果的通用结构,其他的搜索结果中,也可以通过该 class 去定位。
2.2 爬虫代码分析
首先,这是我们代码的核心依赖:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.2</version>
</dependency>
<dependency>
<groupId>io.github.fanyong920</groupId>
<artifactId>jvppeteer</artifactId>
<version>1.1.5</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybaits.plus.version}</version>
</dependency>
初始化浏览器,并且打开百度搜索页
// 初始化浏览器相关
BrowserFetcher.downloadIfNotExist(null);
ArrayList<String> argList = new ArrayList<>();
LaunchOptions options = new LaunchOptionsBuilder().withArgs(argList).withHeadless(false).build();
argList.add("--no-sandbox");
argList.add("--disable-setuid-sandbox");
System.out.println("==1=");
Browser browser = Puppeteer.launch(options);
// 打开页面,开爬
Page page = browser.newPage();
page.goTo("https://www.baidu.com/");
运行上述代码,就会弹出一个浏览器(受我们代码控制),并且打开百度搜索页面
找出页面元素,并且模拟人工搜索关键字、点击搜索按钮的操作
// 模拟人工搜索关键字
ElementHandle inputField = page.$("#kw");
inputField.type("手机");
// 模拟人工点击搜索按钮
ElementHandle confirmSearch = page.$("#su");
confirmSearch.click();
此时,浏览器页面已经按照你的搜索关键词开始搜索了。
用代码解析页面
// 获取页面所有内容(HTML格式)
String content = page.content();
// 解析页面元素,方便后面定位
Document document = Jsoup.parse(content);
// 找出我们上面说的那个class所在的div标签
Elements elements = document.getElementsByClass("result c-container xpath-log new-pmd");
// 去 class所在的div标签中找出需要的 字段信息
for (int i = 0; i < elements.size(); i++) {
Element element = elements.get(i);
String title = element.getElementsByTag("a").text();
String keyword = StrUtil.sub(title, 0, 7);
// 将关键词存储到队列中,后续可使用
keyWordsQueue.offer(keyword);
String href = element.getElementsByTag("a").attr("href");
// ...找出其他字段
System.out.println(dataInfo);
}
至此,一个关键词的爬取就已经完成,如果想要继续爬取关键词,我们继续搜索其他关键词,并且重复上述操作即可。
完整代码中,还包随机等待时长、解析其他字段、保存数据、多个关键字同时爬取等关键逻辑,详见文末。
三、总结
在爬虫中,无非就是模拟人的操作过程,去做相关操作,获取数据。
通过上文介绍的方式,我们是使用一种更具有通用型的方式去爬取数据。因为Puppeteer只是代理人手工点击的方式,而拿到数据。
上述完整代码,可以留言私信我获取。文章来源:https://www.toymoban.com/news/detail-750269.html
本文由博客一文多发平台 OpenWrite 发布!文章来源地址https://www.toymoban.com/news/detail-750269.html
到了这里,关于【教你写爬虫】用Java爬虫爬取百度搜索结果!可爬10w+条!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!