文章来源:https://www.toymoban.com/news/detail-750624.html
文章来源:https://www.toymoban.com/news/detail-750624.html
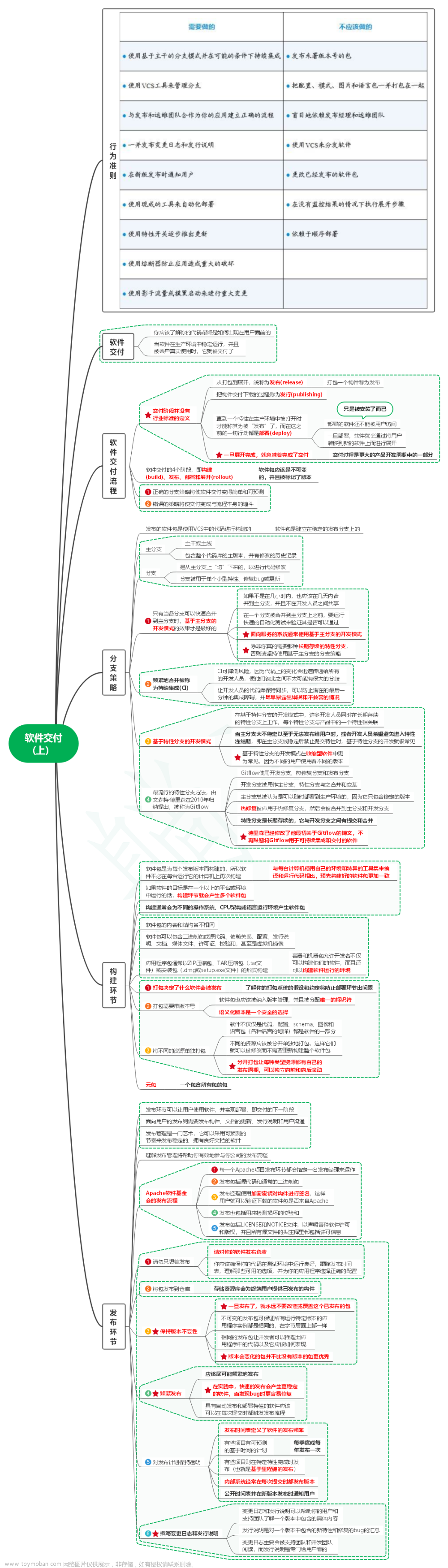
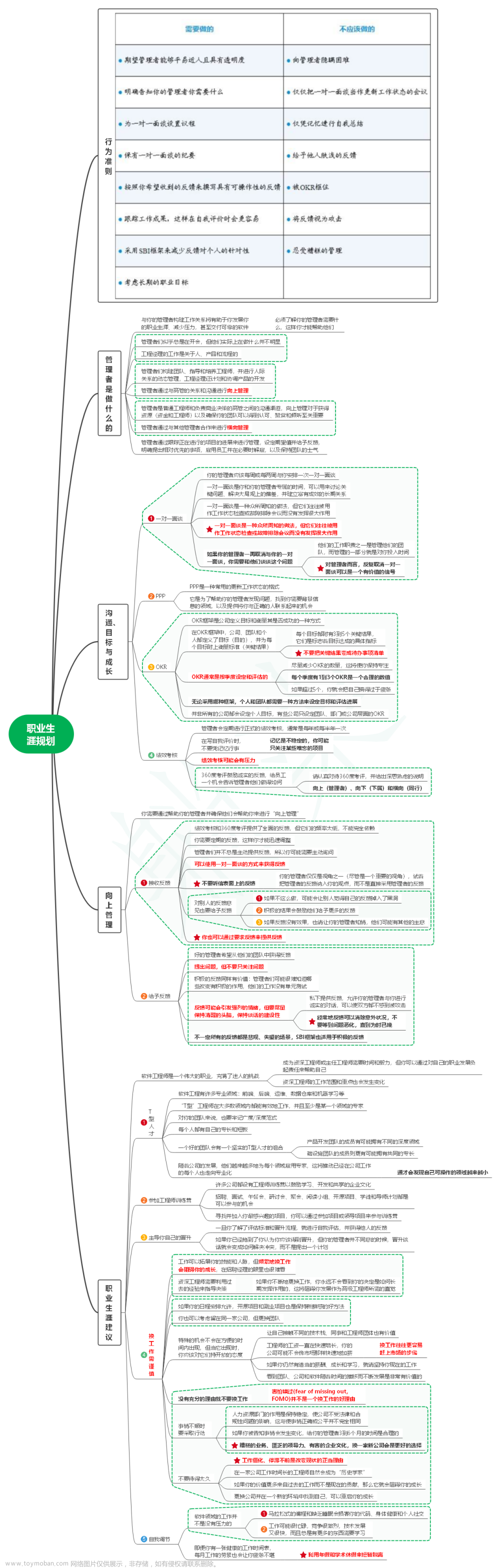
1. 行为准则
 文章来源地址https://www.toymoban.com/news/detail-750624.html
文章来源地址https://www.toymoban.com/news/detail-750624.html
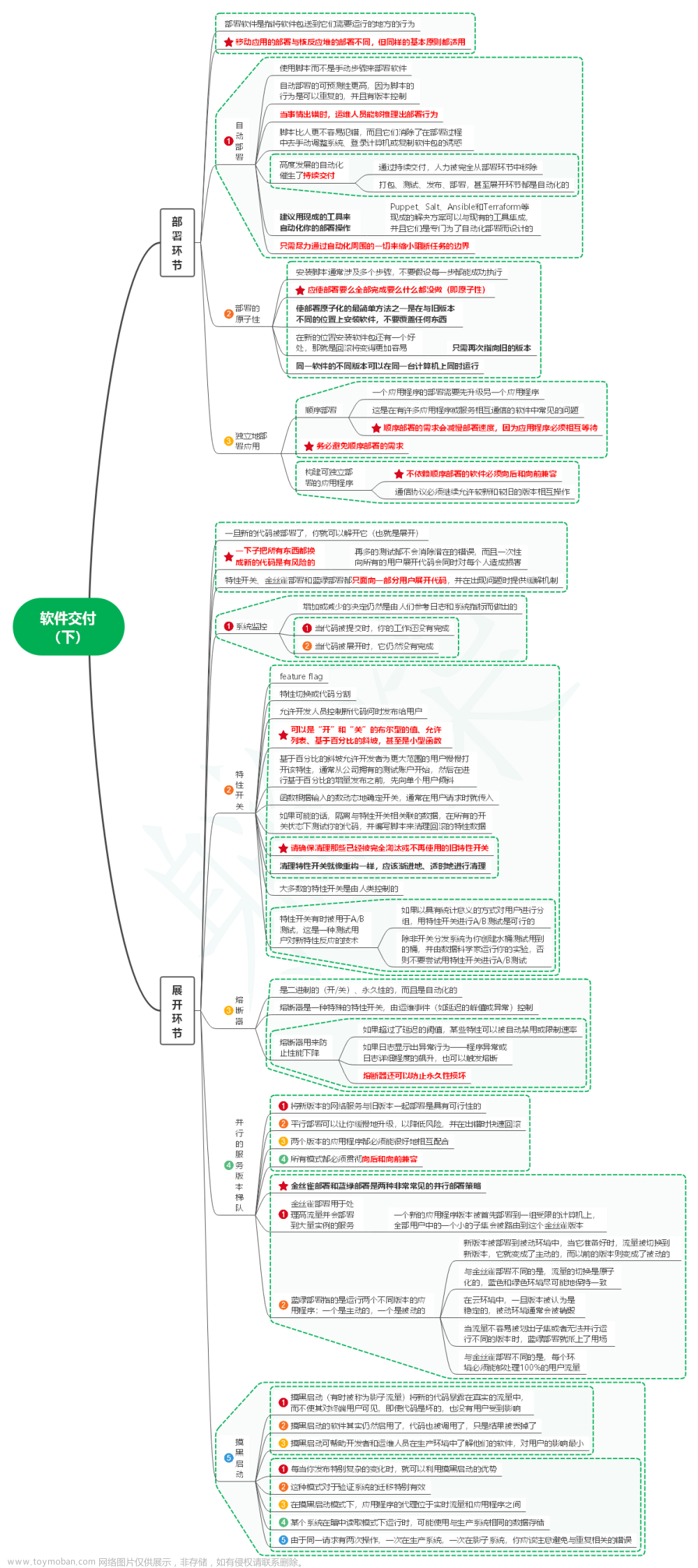
2. 依赖管理
2.1. 在现有的代码上增加一个依赖似乎是一个简单的决定
2.2. 不要重复自己”(Don’t repeat yourself,DRY)是一个通常被教导的原则
2.3. 依赖关系带来了风险
2.3.1. 不兼容的变化
2.3.2. 循环依赖
2.3.3. 版本冲突
2.3.4. 缺乏控制
2.4. 相依性是指你的代码所依赖的代码
2.4.1. 在编译、测试或运行期间,所有需要依赖关系的时间周期被称为依赖范围
2.5. 依赖关系是在软件包管理或构建文件中声明的
2.5.1. Java的Gradle或Maven配置
2.5.2. Python的setup.py或requirements.txt
2.5.3. JavaScript的NPM所使用的package.json
2.6. 一个好的版本管理方案的特点
2.6.1. 唯一性(unique)
2.6.1.1. 版本不应该被重复使用
2.6.1.2. 永远不要在现有版本下重新发布更改的代码
2.6.2. 可比性(comparable)
2.6.2.1. 版本应该帮助人们和工具对版本的优先顺序进行推断
2.6.3. 信息性(informative)
2.6.3.1. 版本信息区分了预先发布的代码和已发布的代码,将构建流水号与构件相关联,并设置了稳定性和兼容性的合理预期
2.7. 具有唯一性的
2.7.1. Git的哈希值或“营销相关”的版本
2.7.2. Android操作系统的甜点系列(Android Cupcake、Android Froyo)
2.7.3. Ubuntu的动物园(Trusty Tahr、Disco Dingo)
2.7.4. 没有可比性或信息性
2.8. 一个递增的版本号(1、2、3)既是唯一的,也是可比较的,但其携带的信息量并不大
3. 语义化版本
3.1. 语义版本管理(semantic versioning,SemVer)的版本管理方案
3.1.1. 版本管理中最常用的方案之一
3.2. 该规范定义了3个数字:主版本号、次版本号和补丁版本号(有时也称作微版本号)
3.2.1. 主版本号.次版本号.补丁版本号
3.3. SemVer的方案还允许使用通配符来标记版本范围(2.13.*)
3.3.1. SemVer承诺跨小版本和补丁版本的兼容性,即使有更新版本被自动拉取,比如修复bug和新特性,此时构建工作也应该继续进行
3.4. 语义化版本同时具有唯一性、可比性、信息性
3.4.1. 每个版本号只使用一次,可以通过从左到右进行比较
3.4.2. 它们提供不同版本之间的兼容性信息,并且可以选择对候选版本或构建流水号进行编码
3.5. 主版本号为0被认为是“预发布”,是为了快速迭代,不做任何兼容性保证
3.5.1. 开发者可以用破坏旧代码的方式修改API
3.6. 主版本号从1开始后,一个项目应该保证
3.6.1. 主版本号从1开始后,一个项目应该保证以下内容
3.6.2. 对于向下兼容的特性,次版本号是递增的
3.6.3. 对于无法向下兼容的变化,主版本号会被递增
3.7. SemVer还通过在补丁版本号后添加一个“-”来定义预发布版本
3.7.1. 小数点分隔的字母和数字的序列被用作预发布版本的标识符(2.13.7-alpha.2)
3.7.2. 许多项目使用候选发布版(release candidate,RC)构建
3.7.3. 早期采用者可以在正式版本发布之前发现RC中的错误
3.7.4. 最终的RC被提升为正式发布版,重新发布的版本没有RC的后缀
3.8. 构建流水号被附加在版本号和预发布元数据之后
3.8.1. 如2.13.7-alpha.2+1942
3.8.2. 包含构建流水号有助于开发者和工具找到任何版本被编译时的构建日志
4. 传递依赖
4.1. 传递依赖管理具有病毒传播的性质
4.2. 大多数构建和打包系统都能生成依赖关系报告
4.3. 了解依赖传递是依赖管理的一个关键部分
4.4. 增加一个依赖关系看起来似乎是一个小变化,但如果相关类库依赖于其他100个类库,你的代码现在就依赖于101个类库
4.5. 任何依赖关系的变化都会影响你的程序
5. 相依性地狱
5.1. 依赖相互冲突和不兼容的变化无处不在,一般的说法是相依性地狱
5.2. 循环依赖
5.2.1. circular dependencies或cyclic dependencies
5.2.2. 一个库间接性地依赖它自己(A依赖B,而B依赖C,C又依赖A)
5.3. 钻石依赖
5.3.1. 一个项目不能同时使用同一个类库的两个不同的版本,所以构建系统必须从中选择其一
5.4. 版本冲突
5.5. 项目经常在没有检查兼容性的情况下就发放版本,即使是自动化也不能完全保证其兼容性
5.6. 那些无法向下兼容的变化会被不经意地发版成次版本或补丁版本,给你的代码库带来巨大的破坏
6. 避免相依性地狱
6.1. 添加一个依赖项的价值是否超过了它的成本
6.1.1. 你真的需要这些特性吗?
6.1.2. 依赖关系的维护情况如何?
6.1.3. 如果出了问题,你修复这个依赖有多容易?
6.1.4. 依赖项的成熟度如何?
6.1.5. 引用依赖后向下兼容的变化频率如何?
6.1.6. 你自己、你的团队和你的组织对该依赖的理解程度如何?
6.1.7. 自己写代码有多容易?
6.1.8. 代码采用什么样的许可协议?
6.1.9. 在依赖中,你使用的代码与你不使用的代码的比例是多少?
6.2. 隔离依赖项
6.2.1. 不必把依赖管理交给构建和打包系统
6.2.2. 将代码复制到你的项目中,用依赖管理自动化换取更多的隔离(稳定性)
6.2.3. 要务实,不要害怕复制代码,如果它能帮助你避免一个庞大的或不稳定的依赖关系
6.2.4. 直接复制代码在简短的、稳定的代码片段上效果最好
6.2.5. 遮蔽依赖也能达到隔离依赖项的目的
6.2.5.1. 遮蔽依赖会自动将一个依赖关系重新定位到不同的命名空间,以避免冲突
6.2.5.2. 一种可以防止库将其依赖关系强加给应用程序的友好方式
6.2.5.3. 遮蔽依赖是一种高级技术,应该少用
6.2.5.4. 永远不要在公共API中暴露一个遮蔽依赖的对象,这样做意味着开发者将不得不在遮蔽的包空间(shaded.some.package.space.Class)中创建对象
6.3. 按需添加依赖项
6.3.1. 将你使用的所有类库显式声明为依赖项
6.3.2. 不要使用来自横向依赖的方法和类
6.3.2.1. 即使你明确指定了直接依赖项的版本,横向依赖仍然可能有通配符
6.3.3. 类库可以自由地改变它们的依赖关系,即使是在补丁级的版本升级中也应如此
6.3.4. 不要只靠IDE来进行依赖管理,在构建文件中明确声明你的依赖项
6.3.4.1. IDE和构建文件之间的差异会使代码在IDE中正常工作,却无法实际地完成代码构建,反之亦然
6.3.5. 指定依赖项的版本
6.3.5.1. 明确设定每个依赖项的版本号,这种做法称为版本指定(version pinning)
6.3.5.2. 未被指定的那些将由构建系统或软件包管理系统为你指定版本
6.3.5.3. 把你的命运交给构建系统是个坏主意,当依赖版本在连续构建过程中发生变化时,你的代码就会不稳定
6.3.5.4. 界定版本范围是在无特定范围和特殊指定某个版本之间的一个折中方案
6.3.5.5. 依赖解析系统可以自由地解决冲突和更新依赖项,但面对重大的变动时能力有限
6.4. 依赖范围最小化
6.4.1. 编译时的依赖项在运行时使用,但运行时的依赖项不会用于编译代码,只会用于运行代码
6.4.2. 对每个依赖项使用尽可能精确的依赖范围
6.4.3. 用编译时的依赖范围来声明所有的依赖项也可以,但这不是个好习惯
6.4.4. 精确的依赖范围将有助于避免冲突并减小运行时的二进制包或者文件的大小
6.5. 保护自己免受循环依赖的影响
6.5.1. 不要引入循环依赖
6.5.2. 使用构建工具保护自己
6.5.2.1. 许多构建系统都有内置的循环依赖检测的特性,当检测到循环依赖时就会提醒你
到了这里,关于读程序员的README笔记08_依赖管理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!