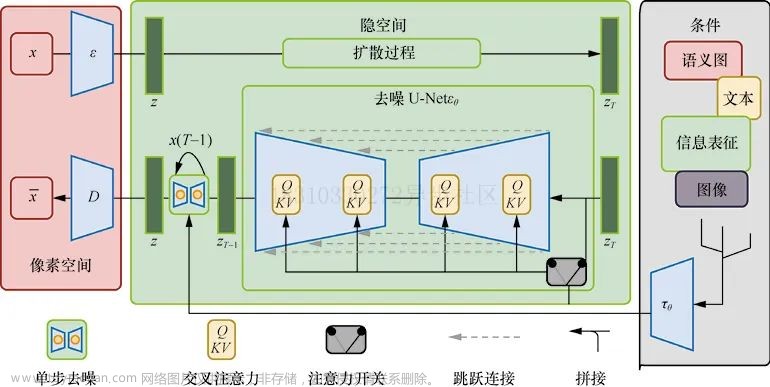
可以参考模型:https://zhuanlan.zhihu.com/p/526438544文章来源地址https://www.toymoban.com/news/detail-751386.html
文章来源:https://www.toymoban.com/news/detail-751386.html
到了这里,关于文本引导的图像生成模型一:DALL·E 2的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!