最近发现自己选的线上通识课在雨课堂上面上传了课件,数了一下一共要看100多个视频,平均时长5-20分钟,而雨课堂的视频无法手动拉动进度条,也无法调整播放速度,因此如果一个一个刷将会非常耗时,作者因此借助自己的爬虫知识,以及在网上搜索过相关经验之后,自己编写了这么一个刷课间的脚本,下面来讲一下运作原理:
一.首先配置相关的环境
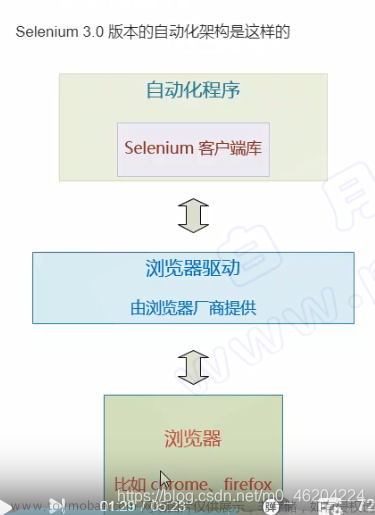
最核心的库就是selenium==4.0.0和urllib3==1.26.2,这里的selenium版本是不能改的,作者试过用最新版的selenium会出现和urllib版本不适配的问题。
另一个核心就是必须要有谷歌浏览器和谷歌浏览器的驱动,且二者的版本必须一致,作者自己的版本是117,浏览器从网上就可以直接下载,驱动的话这里有详细的下载教程:
【chromedriver与chrome各版本及下载地址】
驱动文件必须放在python解释器的Scripts文件夹下,并且配置到环境变量中,具体教程如下:
【PyCharm安装配置谷歌浏览器驱动】
全部配置完成之后就可以开始配置雨课堂了!
二.配置谷歌浏览器的参数
我们知道selenium是专门用于模拟人类进行网页操作的库,因此程序接收到的信息与浏览器完全一致,为了显示出程序的优越性,我们还要设置chrom的一些参数,包括下面几个:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import json
import time
opt=Options()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu") #用于设置无头浏览器,让程序在后台运行
opt.add_argument("--mute-audio") #用于刷视频时静音,这个很重要!
web=webdriver.Chrome(options=opt) #获取chrome浏览器的驱动,并初始化Chrome浏览器
三.设置雨课堂的cookie文件,用于自动登录。
我们知道雨课堂每次登陆都是需要输入账号和密码的,因此保存一个cookie将会对后面的免登录有很大帮助,下面的代码运行一次即可,且建议单独创建一个py文件运行,运行后,将创建一个txt文件存储cookie,并在后面程序运行时载入此cookie,代码运行时,将跳出雨课堂的扫码登录界面,扫码后成功登陆,即可关闭,此时已经保存成功。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import json
import time
#利用selenium获取网页cookies,从而免登录(这部分代码执行一次即可)
time.sleep(15)
with open('cookie.txt','w') as f:
dictCookies = web.get_cookies() # 获取list的cookies
jsonCookies = json.dumps(dictCookies)
f.write(jsonCookies)
print('cookie保存成功!')四.运行自动程序(核心)。
下面为核心代码:
运行逻辑为,每次打开5个要刷的视频,这个量是一般电脑可以承受的网络用量,再多的话网络就受不了了,然后得到5个视频中时长最长的那一个,然后程序休眠,等待所有视频刷完,然后再开启下面5个视频,以此类推。。。直到所有视频刷完,程序结束。
代码中min_id和max_id需要填入自己的视频id号,最低的编号就是雨课堂要刷的第一个课件的网页后缀的最后一个数字,最高的编号就是雨课堂要刷的最后一个课件的网页后缀的最后一个数字,注意,如果这个区间内有课后作业,程序将会跳过,并且经过作者实际操作运行一轮后发现偶然会有几个视频漏掉,建议在跑完一轮后检查一遍,把没有刷成功的视频编号制成list列表,并替换代码中的x。文章来源:https://www.toymoban.com/news/detail-751419.html
另外,偶然会出现5个视频连续打开失败的情况,或者程序刚运行就报错结束了,这种情况建议是重新启动程序,多试几次。文章来源地址https://www.toymoban.com/news/detail-751419.html
#---------------------------------------初始化---------------------
#首先打开主界面,输入cookie
org= f'https://changjiang.yuketang.cn/v2/web/studentLog/13544910'
web.get(org)
time.sleep(6)
with open('cookie.txt', 'r', encoding='utf8') as f:
listCookies = json.loads(f.read())
for cookie in listCookies:
cookie_dict = {
'domain': cookie.get('domain'),
'name': cookie.get('name'),
'value': cookie.get('value'),
'path': '/',
"expires": '',
'sameSite': 'None',
'secure': cookie.get('secure')
}
web.add_cookie(cookie_dict) # 添加cookie
web.get(org) # 更新cookies后进入目标网页
#-------------------------主函数--------------------------------------------
def process(i):
url = f'https://changjiang.yuketang.cn/v2/web/xcloud/video-student/13544910/{i}'
js = "window.open('{}','_blank');"
web.execute_script(js.format(f'https://changjiang.yuketang.cn/v2/web/xcloud/video-student/13544910/{i}'))
time.sleep(5)
web.switch_to.window(web.window_handles[-1])
try:
web.find_element_by_xpath('//*[@id="video-box"]/div/xt-wrap/xt-bigbutton/button').click()
#点击开始播放
wait = web.find_element_by_xpath('//*[@id="video-box"]/div/xt-wrap/xt-controls/xt-inner/xt-time/span[2]').text
print('序号', i, '打开成功')
except:
try:
print('序号', i, '打开失败,刷新')
web.refresh()
time.sleep(5)
web.find_element_by_xpath('//*[@id="video-box"]/div/xt-wrap/xt-bigbutton/button').click()
wait = web.find_element_by_xpath('//*[@id="video-box"]/div/xt-wrap/xt-controls/xt-inner/xt-time/span[2]').text
except:
wait='00:00:05'
print(i,'失败,挂起')
pass
times=int(wait.split(':')[1])*60+int(wait.split(':')[-1])
print('时长',times,'s')
time_list.append(times)
time.sleep(2)
#-------------------------------调试器-----------------------------
min_id='xxxx' #这里输入视频编号最低值
max_id='xxxx' #这里输入视频编号最高值
x=range(min_id,max_id)
i=0
while(i<len(x)):
time_list = []
for j in x[i:i+5]:
try:
process(i)
except:
time.sleep(2)
print('序号', i, '仍然失败,可能是习题')
pass
print('最长的视频长达:', max(time_list), '将在该时间后关闭所有浏览器')
time.sleep(max(time_list))
i+=5五.完整代码如下
#这里有个很坑的地方,selenium的版本只能用旧版的4.0.0,否则就会出现闪退的现象
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import json
import time
opt=Options()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu") #用于设置无头浏览器,让程序在后台运行
opt.add_argument("--mute-audio") #用于刷视频时静音,这个很重要!
web=webdriver.Chrome(options=opt) #获取chrome浏览器的驱动,并初始化Chrome浏览器
#利用selenium获取网页cookies,从而免登录(这部分代码执行一次即可)
'''
time.sleep(15)
with open('cookie.txt','w') as f:
dictCookies = web.get_cookies() # 获取list的cookies
jsonCookies = json.dumps(dictCookies)
f.write(jsonCookies)
'''
#---------------------------------------初始化---------------------
#首先打开主界面,输入cookie
org= f'https://changjiang.yuketang.cn/v2/web/studentLog/13544910'
web.get(org)
time.sleep(6)
with open('cookie.txt', 'r', encoding='utf8') as f:
listCookies = json.loads(f.read())
for cookie in listCookies:
cookie_dict = {
'domain': cookie.get('domain'),
'name': cookie.get('name'),
'value': cookie.get('value'),
'path': '/',
"expires": '',
'sameSite': 'None',
'secure': cookie.get('secure')
}
web.add_cookie(cookie_dict) # 添加cookie
web.get(org) # 更新cookies后进入目标网页
#-------------------------主函数--------------------------------------------
def process(i):
url = f'https://changjiang.yuketang.cn/v2/web/xcloud/video-student/13544910/{i}'
js = "window.open('{}','_blank');"
web.execute_script(js.format(f'https://changjiang.yuketang.cn/v2/web/xcloud/video-student/13544910/{i}'))
time.sleep(5)
web.switch_to.window(web.window_handles[-1])
try:
web.find_element_by_xpath('//*[@id="video-box"]/div/xt-wrap/xt-bigbutton/button').click()
#点击开始播放
wait = web.find_element_by_xpath('//*[@id="video-box"]/div/xt-wrap/xt-controls/xt-inner/xt-time/span[2]').text
print('序号', i, '打开成功')
except:
try:
print('序号', i, '打开失败,刷新')
web.refresh()
time.sleep(5)
web.find_element_by_xpath('//*[@id="video-box"]/div/xt-wrap/xt-bigbutton/button').click()
wait = web.find_element_by_xpath('//*[@id="video-box"]/div/xt-wrap/xt-controls/xt-inner/xt-time/span[2]').text
except:
wait='00:00:05'
print(i,'失败,挂起')
pass
times=int(wait.split(':')[1])*60+int(wait.split(':')[-1])
print('时长',times,'s')
time_list.append(times)
time.sleep(2)
#-------------------------------调试器-----------------------------
min_id='xxxx' #这里输入视频编号最低值
max_id='xxxx' #这里输入视频编号最高值
x=range(min_id,max_id)
i=0
while(i<len(x)):
time_list = []
for j in x[i:i+5]:
try:
process(i)
except:
time.sleep(2)
print('序号', i, '仍然失败,可能是习题')
pass
print('最长的视频长达:', max(time_list), '将在该时间后关闭所有浏览器')
time.sleep(max(time_list))
i+=5到了这里,关于使用python的selenium库自动批量刷长江雨课堂的课件视频的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!