0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 **基于深度学习YOLO安检管制误判识别与检测 **
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:文章来源:https://www.toymoban.com/news/detail-751528.html
https://gitee.com/dancheng-senior/postgraduate文章来源地址https://www.toymoban.com/news/detail-751528.html
1 课题背景
军事信息化建设一直是各国的研究热点,但我国的武器存在着种类繁多、信息散落等问题,这不利于国防工作提取有效信息,大大妨碍了我军信息化建设的步伐。同时,我军武器常以文字、二维图片和实体武器等传统方式进行展示,交互性差且无法满足更多军迷了解武器性能、近距离观赏或把玩武器的迫切需求。本文将改进后的Yolov5算法应用到武器识别中,将武器图片中的武器快速识别出来,提取武器的相关信息,并将其放入三维的武器展现系统中进行展示,以期让人们了解和掌握各种武器,有利于推动军事信息化建设。
2 实现效果
检测展示
3 卷积神经网络
简介
卷积神经网络 (CNN)
是一种算法,将图像作为输入,然后为图像的所有方面分配权重和偏差,从而区分彼此。神经网络可以通过使用成批的图像进行训练,每个图像都有一个标签来识别图像的真实性质(这里是猫或狗)。一个批次可以包含十分之几到数百个图像。
对于每张图像,将网络预测与相应的现有标签进行比较,并评估整个批次的网络预测与真实值之间的距离。然后,修改网络参数以最小化距离,从而增加网络的预测能力。类似地,每个批次的训练过程都是类似的。
相关代码实现
cnn卷积神经网络的编写如下,编写卷积层、池化层和全连接层的代码
conv1_1 = tf.layers.conv2d(x, 16, (3, 3), padding='same', activation=tf.nn.relu, name='conv1_1')
conv1_2 = tf.layers.conv2d(conv1_1, 16, (3, 3), padding='same', activation=tf.nn.relu, name='conv1_2')
pool1 = tf.layers.max_pooling2d(conv1_2, (2, 2), (2, 2), name='pool1')
conv2_1 = tf.layers.conv2d(pool1, 32, (3, 3), padding='same', activation=tf.nn.relu, name='conv2_1')
conv2_2 = tf.layers.conv2d(conv2_1, 32, (3, 3), padding='same', activation=tf.nn.relu, name='conv2_2')
pool2 = tf.layers.max_pooling2d(conv2_2, (2, 2), (2, 2), name='pool2')
conv3_1 = tf.layers.conv2d(pool2, 64, (3, 3), padding='same', activation=tf.nn.relu, name='conv3_1')
conv3_2 = tf.layers.conv2d(conv3_1, 64, (3, 3), padding='same', activation=tf.nn.relu, name='conv3_2')
pool3 = tf.layers.max_pooling2d(conv3_2, (2, 2), (2, 2), name='pool3')
conv4_1 = tf.layers.conv2d(pool3, 128, (3, 3), padding='same', activation=tf.nn.relu, name='conv4_1')
conv4_2 = tf.layers.conv2d(conv4_1, 128, (3, 3), padding='same', activation=tf.nn.relu, name='conv4_2')
pool4 = tf.layers.max_pooling2d(conv4_2, (2, 2), (2, 2), name='pool4')
flatten = tf.layers.flatten(pool4)
fc1 = tf.layers.dense(flatten, 512, tf.nn.relu)
fc1_dropout = tf.nn.dropout(fc1, keep_prob=keep_prob)
fc2 = tf.layers.dense(fc1, 256, tf.nn.relu)
fc2_dropout = tf.nn.dropout(fc2, keep_prob=keep_prob)
fc3 = tf.layers.dense(fc2, 2, None)
4 Yolov5
我们选择当下YOLO最新的卷积神经网络YOLOv5来进行火焰识别检测。6月9日,Ultralytics公司开源了YOLOv5,离上一次YOLOv4发布不到50天。而且这一次的YOLOv5是完全基于PyTorch实现的!在我们还对YOLOv4的各种高端操作、丰富的实验对比惊叹不已时,YOLOv5又带来了更强实时目标检测技术。按照官方给出的数目,现版本的YOLOv5每个图像的推理时间最快0.007秒,即每秒140帧(FPS),但YOLOv5的权重文件大小只有YOLOv4的1/9。
目标检测架构分为两种,一种是two-stage,一种是one-stage,区别就在于 two-stage 有region
proposal过程,类似于一种海选过程,网络会根据候选区域生成位置和类别,而one-stage直接从图片生成位置和类别。今天提到的 YOLO就是一种
one-stage方法。YOLO是You Only Look Once的缩写,意思是神经网络只需要看一次图片,就能输出结果。YOLO
一共发布了五个版本,其中 YOLOv1 奠定了整个系列的基础,后面的系列就是在第一版基础上的改进,为的是提升性能。
YOLOv5有4个版本性能如图所示:
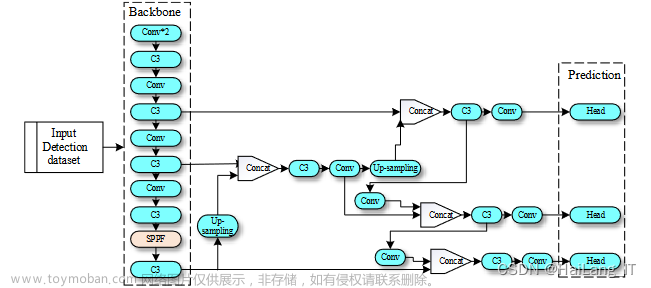
网络架构图

YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
输入端
在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
Mosaic数据增强
:Mosaic数据增强的作者也是来自YOLOv5团队的成员,通过随机缩放、随机裁剪、随机排布的方式进行拼接,对小目标的检测效果很不错
基准网络
融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
Neck网络
在目标检测领域,为了更好的提取融合特征,通常在Backbone和输出层,会插入一些层,这个部分称为Neck。Yolov5中添加了FPN+PAN结构,相当于目标检测网络的颈部,也是非常关键的。


FPN+PAN的结构
这样结合操作,FPN层自顶向下传达强语义特征(High-Level特征),而特征金字塔则自底向上传达强定位特征(Low-
Level特征),两两联手,从不同的主干层对不同的检测层进行特征聚合。
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
Head输出层
输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
对于Head部分,可以看到三个紫色箭头处的特征图是40×40、20×20、10×10。以及最后Prediction中用于预测的3个特征图:
①==>40×40×255
②==>20×20×255
③==>10×10×255

-
相关代码
class Detect(nn.Module): stride = None # strides computed during build onnx_dynamic = False # ONNX export parameter def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer super().__init__() self.nc = nc # number of classes self.no = nc + 5 # number of outputs per anchor self.nl = len(anchors) # number of detection layers self.na = len(anchors[0]) // 2 # number of anchors self.grid = [torch.zeros(1)] * self.nl # init grid self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2) self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv self.inplace = inplace # use in-place ops (e.g. slice assignment) def forward(self, x): z = [] # inference output for i in range(self.nl): x[i] = self.m[i](x[i]) # conv bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85) x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous() if not self.training: # inference if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]: self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i) y = x[i].sigmoid() if self.inplace: y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953 xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh y = torch.cat((xy, wh, y[..., 4:]), -1) z.append(y.view(bs, -1, self.no)) return x if self.training else (torch.cat(z, 1), x) def _make_grid(self, nx=20, ny=20, i=0): d = self.anchors[i].device if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij') else: yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)]) grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float() anchor_grid = (self.anchors[i].clone() * self.stride[i]) \ .view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float() return grid, anchor_grid
5 模型训练
训练效果如下
相关代码
#部分代码
def train(hyp, opt, device, tb_writer=None):
print(f'Hyperparameters {hyp}')
log_dir = tb_writer.log_dir if tb_writer else 'runs/evolve' # run directory
wdir = str(Path(log_dir) / 'weights') + os.sep # weights directory
os.makedirs(wdir, exist_ok=True)
last = wdir + 'last.pt'
best = wdir + 'best.pt'
results_file = log_dir + os.sep + 'results.txt'
epochs, batch_size, total_batch_size, weights, rank = \
opt.epochs, opt.batch_size, opt.total_batch_size, opt.weights, opt.local_rank
# TODO: Use DDP logging. Only the first process is allowed to log.
# Save run settings
with open(Path(log_dir) / 'hyp.yaml', 'w') as f:
yaml.dump(hyp, f, sort_keys=False)
with open(Path(log_dir) / 'opt.yaml', 'w') as f:
yaml.dump(vars(opt), f, sort_keys=False)
# Configure
cuda = device.type != 'cpu'
init_seeds(2 + rank)
with open(opt.data) as f:
data_dict = yaml.load(f, Loader=yaml.FullLoader) # model dict
train_path = data_dict['train']
test_path = data_dict['val']
nc, names = (1, ['item']) if opt.single_cls else (int(data_dict['nc']), data_dict['names']) # number classes, names
assert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, opt.data) # check
# Remove previous results
if rank in [-1, 0]:
for f in glob.glob('*_batch*.jpg') + glob.glob(results_file):
os.remove(f)
# Create model
model = Model(opt.cfg, nc=nc).to(device)
# Image sizes
gs = int(max(model.stride)) # grid size (max stride)
imgsz, imgsz_test = [check_img_size(x, gs) for x in opt.img_size] # verify imgsz are gs-multiples
# Optimizer
nbs = 64 # nominal batch size
# default DDP implementation is slow for accumulation according to: https://pytorch.org/docs/stable/notes/ddp.html
# all-reduce operation is carried out during loss.backward().
# Thus, there would be redundant all-reduce communications in a accumulation procedure,
# which means, the result is still right but the training speed gets slower.
# TODO: If acceleration is needed, there is an implementation of allreduce_post_accumulation
# in https://github.com/NVIDIA/DeepLearningExamples/blob/master/PyTorch/LanguageModeling/BERT/run_pretraining.py
accumulate = max(round(nbs / total_batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= total_batch_size * accumulate / nbs # scale weight_decay
pg0, pg1, pg2 = [], [], [] # optimizer parameter groups
for k, v in model.named_parameters():
if v.requires_grad:
if '.bias' in k:
pg2.append(v) # biases
elif '.weight' in k and '.bn' not in k:
pg1.append(v) # apply weight decay
else:
pg0.append(v) # all else
if opt.adam:
optimizer = optim.Adam(pg0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decay
optimizer.add_param_group({'params': pg2}) # add pg2 (biases)
print('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))
del pg0, pg1,
6 实现效果

7 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
到了这里,关于深度学习YOLO安检管制物品识别与检测 - python opencv 计算机竞赛的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!