1.实验学时
4学时
2.实验目的
- 熟悉Spark Shell。
- 编写Spark的独立的应用程序。
3.实验内容
(一)完成Spark的安装,熟悉Spark Shell。
首先安装spark:
将下好的压缩文件传入linux,然后进行压解:


之后移动文件,修改文件权限:

然后是配置相关的文件:

Vim进入进行修改:


然后是运行程序判断是否安装完成:


由于信息太多,这时需要筛选信息:

运行示例代码输出小数。
然后是shell编程:
首先启动spark:

可以先进行测试,输入1+4看看输出:

测试完成,开始使用命令读取文件:
首先加载本地的文件,这些本地的文件是自带的spark测试文件。
这里读取README.md文件测试。

加载HDFS文件和本地文件都是使用textFile,区别是添加前缀(hdfs://和file:///)进行标识。
之后是简单的操作:
1.读取本地文件:
获得文件第一行内容

文件内容计数

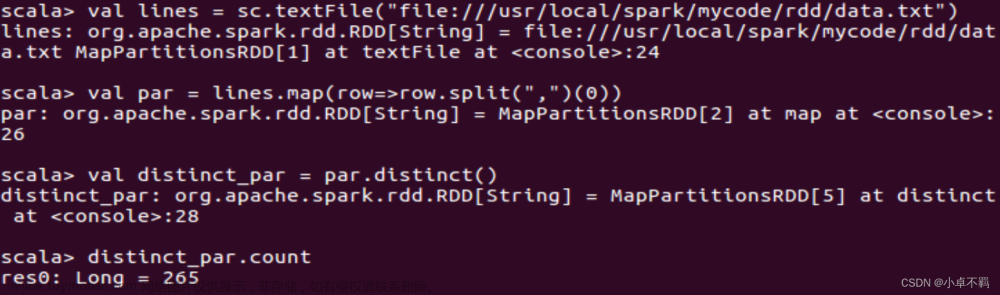
获得含有spark的行,同时返回新的一个RDD

之后统计这个新的RDD的行数:

2.读取hdfs文件,这里首先要启动hadoop

然后读取文件:

然后使用cat命令获取文件内容:

之后切换spark编写语句打印hdfs文件中的第一行内容:

(二)使用Spark程序编写wordcount程序。
这里使用本地的文件实现词频统计程序:
首先是打开文件:

之后遍历文件中的内容,对每个单词进行切分归类,后面使用flatMap命令为的是得到一个关于单词的集合。

得到这些单词的集合之后,开始使用键值对的方式对出现的单词进行计数,每出现一次就使用键值对计算一次。之后计算就得到了每个单词的词频:

(三)使用scala编写Spark程序。
使用spark进行编程需要卸载sbt文件进行辅助,这里先安装spark。
先创建一个文件夹:

然后压缩文件,将文件移动到新建好的文件夹下:


之后在对应的sbt文件夹下创建一个脚本文件,用于启动sbt。
脚本文件代码如下:

然后为文件增加权限:

之后可以查看sbt版本信息:

这里可以看到sbt的版本是1.38>这里会下载一些数据包,需要进行等待。+


执行成功。
之后就可以执行命令创建文件夹作为程序根目录

之后创建代码文件输入代码:
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
之后保存之后就使用sbt打包scala应用程序:
首先在对应的路径下创建对应的编译文件实现程序编写:


为了保证程序正常运行,需要检查整个应用程序的文件结构:
查找之后:

之后就可以将整个应用程序打包成为JAR:

这个时候就会在网上下载东西,等几分钟之后就会生成对应的jar包之后返回一些信息。

之后返回的信息:

之后可以使用jar包通过spark-submit在spark中运行,使用代码直接得到结果:

(四)使用java编写Spark程序,熟悉maven打包过程。
首先下载maven,之后进行压缩:

之后移动文件夹:

之后是编写java程序:
首先创建java文件,之后输入代码:

/*** SimpleApp.java ***/
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.SparkConf;
public class SimpleApp {
public static void main(String[] args) {
String logFile = "file:///usr/local/spark/README.md"; // Should be some file on your system
SparkConf conf=new SparkConf().setMaster("local").setAppName("SimpleApp");
JavaSparkContext sc=new JavaSparkContext(conf);
JavaRDD<String> logData = sc.textFile(logFile).cache();
long numAs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("a"); }
}).count();
long numBs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("b"); }
}).count();
System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs);
}
}
这个程序依赖于spark java apl,所以需要使用maven进行打包。
之后使用vim在对应目录下建立xml文件

输入代码:
<project>
<groupId>cn.edu.xmu</groupId>
<artifactId>simple-project</artifactId>
<modelVersion>4.0.0</modelVersion>
<name>Simple Project</name>
<packaging>jar</packaging>
<version>1.0</version>
<repositories>
<repository>
<id>jboss</id>
<name>JBoss Repository</name>
<url>http://repository.jboss.com/maven2/</url>
</repository>
</repositories>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.0</version>
</dependency>
</dependencies>
</project>
然后使用maven打包java程序:
首先检查文件结构:

然后使用代码将整个程序打包成为jar包,在打包的时候会接入网络下载文件。

发现程序正常运行。
然后通过spark-submit运行程序:

查看结果:

通过spark-submit运行程序,得到结果:

4.思考题
(一)Hadoop和Spark直接的区别在哪里?谁的性能更好?
Hadoop的框架最核心的设计就是:HDFS 和 Map Reduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Spark 拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS
Hadoop是磁盘级计算,计算时需要在磁盘中读取数据;其采用的是MapReduce的逻辑,把数据进行切片计算用这种方式来处理大量的离线数据.
Spark,它会在内存中以接近“实时”的时间完成所有的数据分析。Spark的批处理速度比MapReduce快近10倍,内存中的数据分析速度则快近100倍。
综合上面的数据,可以判断Spark的速度会比Hadoop更快,Spark的性能会更加好。
5.实验结论或体会
1. 加载HDFS文件和本地文件都是使用textFile,区别是添加前缀(hdfs://和file:///)进行标识。
2.编写程序的时候,需要使用到maven进行程序的打包。
3.进行打包的时候需要对路径进行判断,防止路径错误导致的数据文件的丢失。文章来源:https://www.toymoban.com/news/detail-752304.html
4.在进行打包的时候需要进行等待软件包下载好,否则再次进行打包的时候会产生数据的流失。文章来源地址https://www.toymoban.com/news/detail-752304.html
到了这里,关于云计算技术 实验九 Spark的安装和基础编程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!