[Hadoop]数仓工具Hive的安装部署
📕作者:喜欢水星记
🏆系列:Hadoop高可用集群
🔋收藏:本文记录我搭建过程供大家学习和自己之后复习,如果对您有用,希望能点赞收藏加关注
Hive的简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
最初,Hive是由Facebook开发,后来由Apache软件基金会开发,并作为进一步将它作为名义下Apache Hive为一个开源项目。
Hive 建立在Hadoop 基础之上,Hive 与 Hadoop 紧密集成,其设计可快速对 PB 级数据进行操作。
Hive的意义就是在业务分析中将用户容易编写、会写的Sql语言转换为复杂难写的MapReduce程序,从而大大降低了Hadoop学习的门槛,让更多的用户可以利用Hadoop进行数据挖掘分析。
Hive的优点
-
Hive 所采用的数据可通过批处理快速处理 PB 级数据。
-
Hive 提供非程序员可以使用的熟悉的类似于 SQL 的界面。
-
Hive 可根据使用者的需求被轻松分发与扩展。
-
Hive支持标准的SQL语法,免去了用户编写MapReduce程序的过程,大大减少了公司的开发成本
-
Hive的出现可以让那些精通SQL技能、但是不熟悉MapReduce 、编程能力较弱与不擅长Java语言的用户能够在HDFS大规模数据集上很方便地利用SQL 语言查询、汇总、分析数据
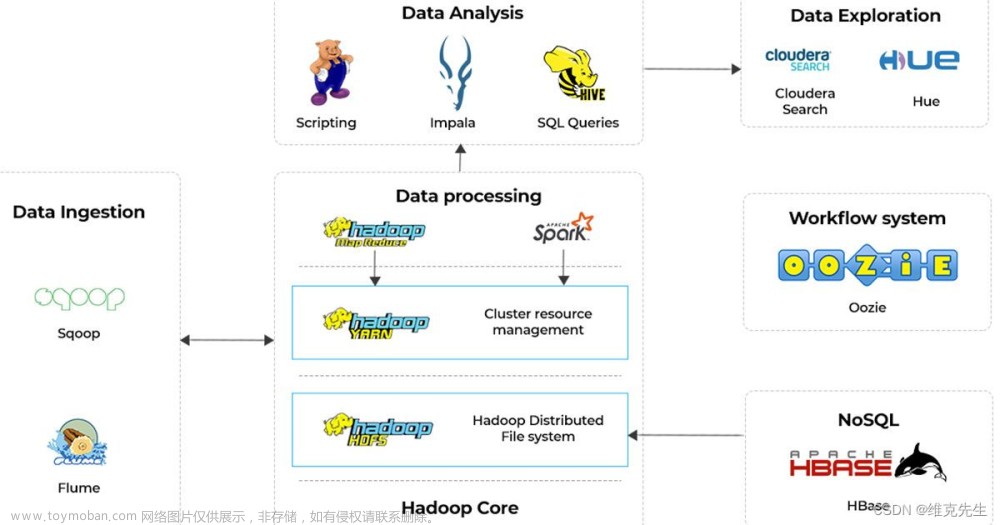
Hive的架构
架构图

Hadoop 和 MapReduce 是 Hive 架构的根基
Hive的体系结构可以分为以下几部分:
- 用户接口主要有三个:CLI,JDBC/ODBC和 Web UI。
- ①其中,最常用的是CLI,即Shell命令行;
- ②JDBC/ODBC Client是Hive的Java客户端,与使用传统数据库JDBC的方式类似,用户需要连接至Hive Server;
- ③Web UI是通过浏览器访问。
- Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
- Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成。
安装Hive
Hive搭建环境
- Centos7的操作系统
- 已安装完JDK
- 已搭建Hadoop
- 已搭建MySQL数据库平台
如果没有安装可以查看我上一篇文章:
Hadoop海量数据存储与计算高可用集群部署
==注意:==初学者最好在完成我上一篇Hadoop集群搭建之后再安装Hive
软件版本选用
选用Hive的2.1.1版本,软件包名apache-hive-2.1.1-bin.tar.gz
Hive工具使用JDBC方式连接MySQL数据库,需要用到MySQL数据库连接工具软件,选用该软件的5.1.42版本,软件包名mysql-connector-java-5.1.42-bin.jar
软件下载:
提取链接
提取码:0768
Hive工具安装配置
Hive的安装过程只需要在Cluster-01主机的admin用户下进行
在Cluster-01上:
su - admin # 进入admin用户
mkdir setups # 将本次实验所需要的软件包上传至该目录,之前已经上传 我这里就不上传了
mkdir hive #创建用于存放Hive相关文件的目录
cd ~/hive
mkdir tmp
tar -xzf ~/setups/apache-hive-2.1.1-bin.tar.gz
[root@Cluster-01 ~]# su - admin # 进入admin用户
Last login: Mon May 1 22:42:23 CST 2023 on pts/0
[admin@Cluster-01 ~]$ mkdir hive # 创建用于存放Hive相关文件的目录
[admin@Cluster-01 ~]$ cd hive/
[admin@Cluster-01 hive]$ mkdir tmp # 创建Hive的本地临时文件目录"tmp"
[admin@Cluster-01 hive]$ tar -xzf ~/setups/apache-hive-2.1.1-bin.tar.gz
[admin@Cluster-01 hive]$ ls
apache-hive-2.1.1-bin tmp
配置Hive相关的环境变量
vi ~/.bash_profile
对配置文件进行修改,在文件末尾添加以下内容:
#hive environment
HIVE_HOME=/home/admin/hive/apache-hive-2.1.1-bin
PATH=$HIVE_HOME/bin:$PATH
export HIVE_HOME PATH

刷新环境变量,使其立即生效
source ~/.bash_profile
验证环境变量是否配置成功
echo $HIVE_HOME
echo $PATH

出现hive则表明环境变量配置成功
修改Hive相关配置文件
进入Hive的配置文件目录
cd ~/hive/apache-hive-2.1.1-bin/conf
Hive的配置文件默认都被命名为了模板文件,需要对其进行拷贝重命名之后才能使用:
cp hive-env.sh.template hive-env.sh
cp hive-log4j2.properties.template hive-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
cp hive-default.xml.template hive-site.xml
对配置文件进行修改,找到相关配置项并对其值进行修改(本个文件一共有3处修改的)
vi hive-env.sh
找到配置项“HADOOP_HOME”,该项用于指定Hadoop所在的路径,将其值改为以下内容:
HADOOP_HOME=/home/admin/hadoop/hadoop-2.7.3
找到配置项“HIVE_CONF_DIR”,该项用于指定Hive的配置文件所在的路径,将其值改为以下内容:
export HIVE_CONF_DIR=/home/admin/hive/apache-hive-2.1.1-bin/conf
找到配置项“HIVE_AUX_JARS_PATH”,该项用于指定Hive的lib文件所在的路径,将其值改为以下内容:
export HIVE_AUX_JARS_PATH=/home/admin/hive/apache-hive-2.1.1-bin/lib

启动相关进程
在五台主机的admin用户下执行:
zkServer.sh status #查看zookeeper的状态
zkServer.sh start #启动zookeeper,如果zookeeper已经启动则不需要执行本条命令
在Cluster-01的admin用户下执行
start-all.sh
在Cluster-02的admin用户下执行
yarn-daemon.sh start resourcemanager

在HDFS中创建Hive相关目录并赋权
本项操作仅在Cluster-01的admin用户下进行
hadoop fs -mkdir -p /user/hive/tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -mkdir -p /user/hive/log
hadoop fs -chmod 777 /user/hive/tmp
hadoop fs -chmod 777 /user/hive/warehouse
hadoop fs -chmod 777 /user/hive/log
[admin@Cluster-01 conf]$ hadoop fs -mkdir -p /user/hive/tmp #在HDFS中分别创建Hive的临时文件目录tmp
[admin@Cluster-01 conf]$ hadoop fs -mkdir -p /user/hive/warehouse #在HDFS中分别创建Hive的数据存储目录“warehouse”
[admin@Cluster-01 conf]$ hadoop fs -mkdir -p /user/hive/log #在HDFS中分别创建Hive的日志文件目录“log”
[admin@Cluster-01 conf]$ hadoop fs -chmod 777 /user/hive/tmp # 赋权
[admin@Cluster-01 conf]$ hadoop fs -chmod 777 /user/hive/warehouse
[admin@Cluster-01 conf]$ hadoop fs -chmod 777 /user/hive/log
[admin@Cluster-01 conf]$ hadoop fs -ls /user/hive # 查看刚刚创建的目录
Found 3 items
drwxrwxrwx - admin supergroup 0 2023-05-08 21:32 /user/hive/log
drwxrwxrwx - admin supergroup 0 2023-05-08 21:32 /user/hive/tmp
drwxrwxrwx - admin supergroup 0 2023-05-08 21:32 /user/hive/warehouse
修改相关配置文件
vi ~/hive/apache-hive-2.1.1-bin/conf/hive-site.xml
找到下列标签“”所标识的属性项名称所在位置,修改其标签“”所标识的属性值部分的内容:
第一处:
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
修改为::
<property>
<name>hive.exec.scratchdir</name>
<value>/user/hive/tmp</value>
(只修改了<value>标签里面的值)

第二处:
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
修改为::
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
注意:这里有的人可能不需要修改

第三处:
<property>
<name>hive.querylog.location</name>
<value>${system:java.io.tmpdir}/${system:user.name}</value>
<description>Location of Hive run time structured log file</description>
修改为:::
<property>
<name>hive.querylog.location</name>
<value>/user/hive/log</value>
<description>Location of Hive run time structured log file</description>
(只修改了<value>标签里面的值)

小技巧:该文档内容较多,可以在编辑器内使用命令“/关键字”直接进行搜索,使用快捷键“n”可以切换到下一个关键字的所在位置。
创建hive元数据数据库
本项的所有操作步骤使用五台主机的用户root进行,5台都要操作
在MySQL数据库SQL服务节点Cluster-04中创建一个数据库“hive”用于存放Hive的元数据,该数据库的用户名和密码均为“hive”,数据库名、用户名、密码均可以自行设定,但需要与Hive配置文件中的内容相对应,连接MySQL数据库:
启动MySQL:
将五台主机切换到root用户
su - root (五台都要执行)
在Cluster-01执行:
ndb_mgmd -f /usr/local/mysql/etc/config.ini
在Cluster-02,03 执行:
ndbd
在Cluster-04,05执行:
service mysql start
执行完后查看连接状态:
ndb_mgm -e show

进入控制台
在Cluster-04的root用户下执行:
mysql -hCluster-04 -uroot -pmysqlabc
在控制台执行以下命令进行数据库的创建:
CREATE DATABASE hive;
USE hive;
CREATE USER ‘hive’@‘%’ IDENTIFIED BY ‘hive’;
GRANT ALL ON hive.* TO ‘hive’@‘%’;
FLUSH PRIVILEGES;
show databases;
quit;
mysql> CREATE DATABASE hive; # 创建数据库hive
Query OK, 1 row affected (0.05 sec)
mysql> USE hive; # 切换到新创建的hive数据库
Database changed
mysql> CREATE USER 'hive'@'%' IDENTIFIED BY 'hive'; # 创建数据库用户hive
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT ALL ON hive.* TO 'hive'@'%'; # 设置hive数据库的访问权限,hive用户拥有所有操作权限并支持远程访问
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH PRIVILEGES; # 刷新数据库权限信息
Query OK, 0 rows affected (0.00 sec)
mysql> show databases; # 显示数据库
+--------------------+
| Database |
+--------------------+
| information_schema |
| hive |
| mysql |
| ndbinfo |
| performance_schema |
| sys |
| test |
+--------------------+
7 rows in set (0.00 sec)
mysql> quit; # 退出数据库控制台
Bye
添加MySQL连接的相关配置信息
本项仅在Cluster-01的admin用户下进行
vi ~/hive/apache-hive-2.1.1-bin/conf/hive-site.xml
找到下列标签“”所标识的属性项名称所在位置,修改其标签“”所标识的属性值部分的内容:
将:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
<description>
修改为:::
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://Cluster-04:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
<description>
只需要修改<value>标签里面的内容即可

将
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
修改为:
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>

将:
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>APP</value>
<description>Username to use against metastore database</description>
</property>
修改为:
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>

将:
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>mine</value>
<description>password to use against metastore database</description>
</property>
修改为:
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>

将MySQL的数据库连接工具包添加到Hive的“lib”目录下
cp -v ~/setups/mysql-connector-java-5.1.42-bin.jar ~/hive/apache-hive-2.1.1-bin/lib
添加MySQL连接的相关配置信息
vi ~/hive/apache-hive-2.1.1-bin/conf/hive-site.xml
在编辑器中使用快捷键“:”进入到编辑器的命令模式,也称为末行模式,然后使用命令
%s#${system:java.io.tmpdir}#/home/admin/hive/tmp#g
%s#${system:user.name}#${user.name}#g
Hive初始化
在Cluster-01的admin用户下进行
schematool -initSchema -dbType mysql

删除hive中$HIVE_HOME/lib下面的log4j-slf4j-impl-2.4.1.jar包
cd $HIVE_HOME/lib
rm -rf log4j-slf4j-impl-2.4.1.jar
为了防止与Hadoop中的jar包slf4j-log4j12-1.7.10.jar冲突
Hive工具启动和验证
本项步骤只在中Cluster-01主机admin用户上进行操作即可
进入hive控制台
hive
查看数据库
show databases;
退出
quit;文章来源地址https://www.toymoban.com/news/detail-752361.html
简单练习
在Cluster-01的admin用户下
基本命令
show databases; # 显示数据库信息
create database test; # 创建一个名为test的数据库
use test; # 使用刚刚创建的test库
show tables; # 显示当前的表
进入hive控制台
hive
创建表及加载数据
create table student1 (
id int comment 'id of student1',
name string comment 'name of student1',
age int comment 'age of student1',
gender string comment 'sex of student1',
addr string
)
comment 'this is a demo'
row format delimited fields terminated by '\t';
查看表
desc student1;

在任意一台主机的root用户下,我这里使用Cluster-04的root进入MySQL
mysql -hCluster-04 -uroot -pmysqlabc
(注意:mysqlabc 是我自己设置的密码)
进入mysql控制台之后,调用hive的库
use hive;
查看刚刚创建的表信息
select * from TBLS;

退出控制台文章来源:https://www.toymoban.com/news/detail-752361.html
quit;
到了这里,关于[Hadoop高可用集群]数仓工具之Hive的安装部署(超级详细,适用于初学者)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!