在基于索引器的索引编制中,Azure AI _集成矢量化_将数据分块和文本到矢量嵌入添加到技能中,它还为查询添加文本到矢量的转换。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。文章来源地址https://www.toymoban.com/news/detail-752662.html

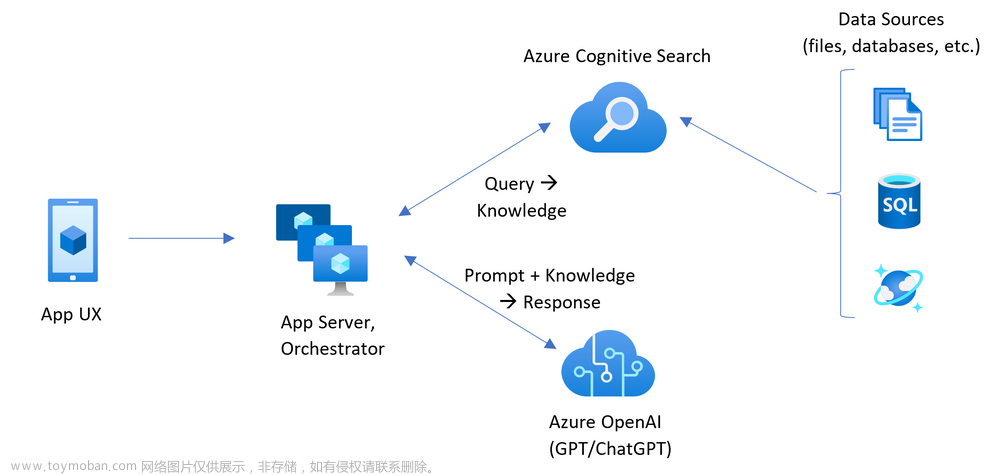
一、组件图
下图显示了集成矢量化的组件。

下面是负责集成矢量化的组件清单:
- 基于索引器的索引编制支持的数据源。
- 一个用于指定矢量字段的索引,以及一个分配到矢量字段的矢量化器定义。
- 一个用于为数据分块提供文本拆分技能的技能组,以及一个矢量化技能(AzureOpenAiEmbedding 技能,或指向外部嵌入模型的自定义技能)。
- (可选)用于将分块数据推送到次要索引的索引投影(也在技能组中定义)
- 一个嵌入模型,部署在 Azure OpenAI 上或通过 HTTP 终结点提供。
- 一个用于端到端驱动流程的索引器。 索引器还指定用于进行更改检测的计划、字段映射和属性。
此清单主要与集成矢量化有关,但你的解决方案并不局限于此列表。 可以添加其他 AI 扩充技能、创建知识存储、添加语义排名、添加相关性优化和其他查询功能。
二、可用性和定价
集成矢量化可用性基于嵌入模型。 如果使用的是 Azure OpenAI,请查看区域可用性。
如果使用的是自定义技能和 Azure 托管机制(例如 Azure 函数应用、Azure Web 应用和 Azure Kubernetes),请查看各区域上市的产品页以了解功能可用性。
数据分块(文本拆分技能)是免费的,已在所有区域的所有 Azure AI 服务中提供。
三、集成矢量化支持哪些方案?
-
将大型文档划分为块,这对于矢量和非矢量方案很有用。 对于矢量方案,块可帮助你满足嵌入模型的输入约束。 对于非矢量方案,你可能会使用一个聊天式搜索应用,其中的 GPT 从编制了索引的块中组合响应。 可以使用矢量化块或非矢量化块进行聊天式搜索。
-
生成一个矢量存储,其中的所有字段都是矢量字段,只有文档 ID(搜索索引所需)是字符串字段。 查询矢量索引以检索文档 ID,然后将文档的矢量字段发送到另一个模型。
-
组合矢量和文本字段来执行提供或不提供语义排名的混合搜索。 集成矢量化简化了[矢量搜索支持的所有方案]
四、何时使用集成矢量化
我们建议使用 Azure AI Studio 的内置矢量化支持。 如果此方法不能满足你的需求,你可以创建索引器和技能组,以便使用 Azure AI 搜索的编程接口调用集成矢量化。
五、如何使用集成矢量化
对于仅限查询的矢量化:
- 将一个[矢量化器添加]到索引。 它应该与用于在索引中生成矢量的嵌入模型相同。
- 将[矢量化器分配]到矢量字段。
- [构建矢量查询],用于指定要矢量化的文本字符串。
更常见的方案 - 在索引编制期间进行数据分块和矢量化:
- 与支持的数据源[建立数据源连接],以进行基于索引器的索引编制。
- [创建一个技能组],用于调用[文本拆分技能]进行分块,并调用 [AzureOpenAIEmbeddingModel]或自定义技能来将块矢量化。
- [创建一个索引]用于指定查询时间的[矢量化器],并将其分配到矢量字段。
- [创建一个索引器]以驱动从数据检索到技能组执行,再到索引编制的整个流程。
六、限制
确保了解[嵌入模型的 Azure OpenAI 配额和限制]。 Azure AI 搜索具有重试策略,但如果配额耗尽,重试会失败。
Azure OpenAI 每分钟令牌数限制是按模型、按订阅计算的。 如果对查询和索引编制工作负载使用嵌入模型,请记住这一点。 在可能的情况下[遵循最佳做法]。 为每个工作负载提供一个嵌入模型,并尝试将其部署在不同的订阅中。
请记住,在 Azure AI 搜索中,存在按层和按工作负载规定的[服务限制]。
最后,目前不支持以下功能:
- [客户托管的加密密钥]
- 与矢量化器的[共享专用链接连接]
- 目前,不提供对集成数据分块和矢量化进行批处理的功能
七、集成矢量化的优势
下面是集成矢量化的一些重要优势:
-
没有单独的数据分块和矢量化管道。 代码更易于编写和维护。
-
自动进行端到端索引编制。 当源(例如 Azure 存储、Azure SQL 或 Cosmos DB)中的数据发生更改时,索引器可以在整个管道中传递这些更新(从检索到文档破解,再到可选的 AI 扩充、数据分块、矢量化和索引编制)。
-
将分块的内容投影到次要索引。 次要索引的创建方式与创建任何搜索索引(包含字段和其他构造的架构)一样,但索引器会将它们与主要索引一起填充。 在同一索引编制运行期间,每个源文档的内容都会流向主要和次要索引中的字段。
次要索引适用于数据分块和检索增强生成 (RAG) 应用。 假设将一个大型 PDF 文件用作源文档,主要索引可能包含基本信息(标题、日期、作者、描述),而次要索引则包含内容块。 借助数据块级别的矢量化,可以更轻松地查找相关信息(每个块均可搜索)并返回相关响应,尤其是在聊天式搜索应用中。
八、分块索引
分块是将内容划分为可独立处理的较小可管理部分(块)的过程。 如果源文档太大,以至超过了嵌入或大型语言模型的最大输入大小,那么就需要进行分块,但你可能发现,分块能够为 [RAG 模式]和聊天式搜索提供更好的索引结构。
下图显示了分块索引编制的组件。
 文章来源:https://www.toymoban.com/news/detail-752662.html
文章来源:https://www.toymoban.com/news/detail-752662.html
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
到了这里,关于Azure Machine Learning - Azure AI 搜索中的集成数据分块和嵌入的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!