Stable Diffusion 推理优化

背景
2022年,Stable Diffusion模型横空出世,其成为AI行业从传统深度学习时代走向AIGC时代的标志性模型之一,并为工业界,投资界,学术界以及竞赛界都注入了新的AI想象空间,让AI再次性感。
Stable Diffusion是计算机视觉领域的一个生成式大模型,能够进行文生图(txt2img)和图生图(img2img)等图像生成任务。与Midjourney不同的是,Stable Diffusion是一个完全开源的项目(模型,代码,训练数据,论文等),这使得其快速构建了强大繁荣的上下游生态(AI绘画社区,基于SD的自训练模型,丰富的辅助AI绘画工具与插件等),并且吸引了越来越多的AI绘画爱好者也加入其中,与AI行业从业者一起不断推动AIGC行业的发展与普惠。
也正是Stable Diffusion的开源属性,繁荣的上下游生态以及各行各业AI绘画爱好者的参与,使得AI绘画火爆出圈,让大部分人都能非常容易地进行AI绘画。可以说,本次AI科技浪潮的ToC普惠在AIGC时代的早期就已经显现,这是之前的传统深度学习时代从未有过的。而这也是最让Rocky振奋的AIGC属性,让Rocky相信未来的十年会是像移动互联网时代那样,充满科技变革与机会的时代。
Stable Diffusion 本质是基于扩散模型的高质量图像生成技术,可根据文本输入生成图像,广泛应用于CG、插画和高分辨率壁纸等领域。然而,由于其计算过程较为复杂,Stable Diffusion 的图像生成速度常常成为遏制其发展的限制因素。
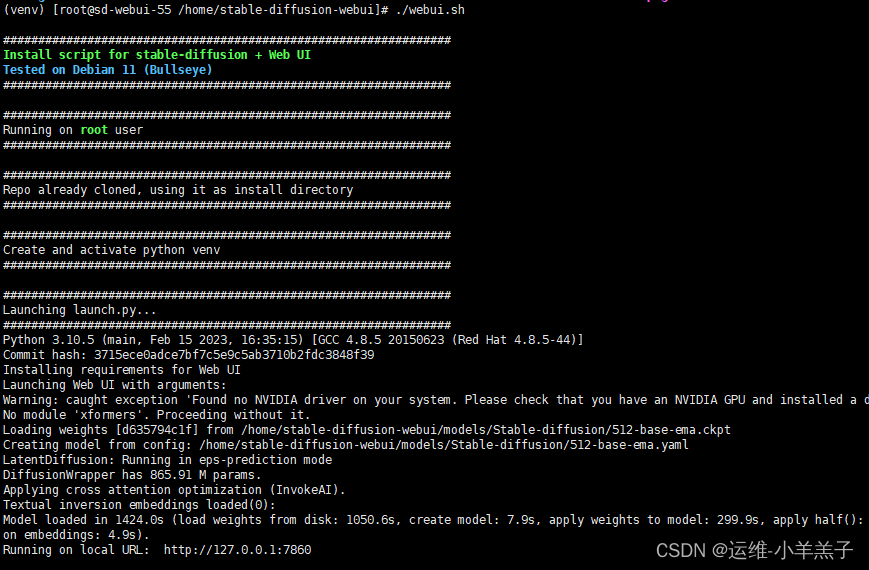
优化AI生图模型在端侧设备上的 Pipeline性能,在保证生图效果的情况下,降低pipeline端到端延迟,降低pipeline峰值内存占用,也成了当下迫在眉前的大难题。契合本次大赛要求,我们团队计划在目标英特尔硬件上完成部署优化及指定的图片生成工作,利用 OpenVINO 的异步推理功能,实现了预处理、推理和后处理阶段的并行执行,从而提高了整体图像生成 Pipeline 的并行性。
技术讲解:
Stable Diffusion(SD)模型是由Stability AI和LAION等公司共同开发的生成式模型,总共有1B左右的参数量,可以用于文生图,图生图,图像inpainting,ControlNet控制生成,图像超分等丰富的任务,本节中我们以**文生图(txt2img)和图生图(img2img)**任务展开对Stable Diffusion模型的工作流程进行通俗的讲解。

文生图任务是指将一段文本输入到SD模型中,经过一定的迭代次数,SD模型输出一张符合输入文本描述的图片。比如按照赛题要求输入关键字:
- Prompt输入:“a photo of an astronaut riding a horse on mars”
- Negative Prompt输入:“low resolution, blurry”

其本质就是给SD模型一个文本信息与机器数据信息之间互相转换的“桥梁”——CLIP Text Encoder模型。如下图所示,我们使用CLIP Text Encoder模型作为SD模型的前置模块,将输入的人类文本信息进行编码,输出特征矩阵,这个特征矩阵与文本信息相匹配,并且能够使得SD模型理解:

完成对文本信息的编码后,就会输入到SD模型的“图像优化模块”中对图像的优化进行“控制”。
“图像优化模块”作为SD模型中最为重要的模块,其工作流程是什么样的呢?文章来源:https://www.toymoban.com/news/detail-752734.html
首先&#文章来源地址https://www.toymoban.com/news/detail-752734.html
到了这里,关于OpenVINO异步Stable Diffusion推理优化方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!