目录
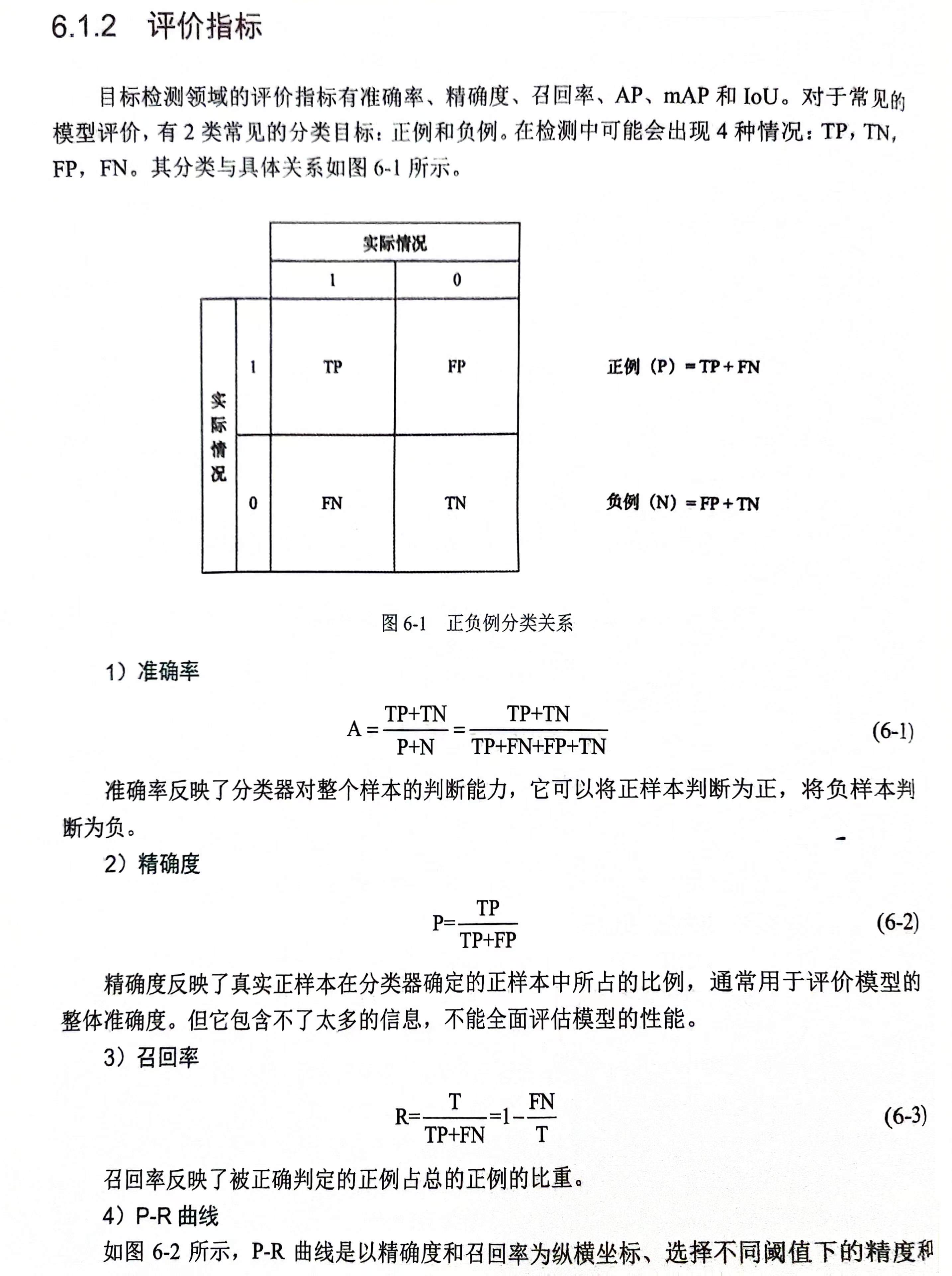
编辑引言
相机姿态估计的基本概念
相机姿态估计的方法
特征点匹配
直接法
基于深度学习的方法
相机姿态估计的应用
增强现实(AR)
机器人导航
三维重建
结论
引言
相机姿态估计是计算机视觉领域的重要任务之一。它涉及到确定相机在三维空间中的位置和朝向,常用于诸如增强现实、机器人导航、三维重建等应用中。本文将介绍相机姿态估计的基本概念、常用方法以及应用领域。
相机姿态估计的基本概念
相机姿态估计,即相机位姿估计,是指通过计算机视觉算法来确定相机在世界坐标系中的位置和方向。一般情况下,我们可以将相机的姿态表示为一个4×4的变换矩阵,即相机的位姿矩阵。这个矩阵包含了相机的位置、朝向等信息。
相机姿态估计的方法
相机姿态估计的方法有很多种,下面介绍一些常用的方法:
特征点匹配
特征点匹配是一种常用的相机姿态估计方法。它通过检测图像中的特征点,并找到两幅图像之间对应的特征点,然后利用这些特征点的几何关系来估计相机的姿态。常用的特征点匹配算法包括SIFT、SURF、ORB等。
直接法
直接法是一种不依赖于特征点的相机姿态估计方法。它通过直接比较两幅图像之间的像素值差异来估计相机的姿态。直接法能够在光照变化、遮挡等情况下仍然有效,但由于需要处理大量的像素点,计算复杂度较高。
基于深度学习的方法
近年来,深度学习在计算机视觉领域取得了巨大的成功。基于深度学习的方法可以通过神经网络来直接估计相机的姿态。这些方法通常需要大量的标注数据进行训练,但在一些特定的应用场景下,能够取得很好的效果。
以下是一个使用OpenCV库实现相机姿态估计的示例代码:
pythonCopy codeimport cv2
import numpy as np
# 读取相机内参
camera_matrix = np.array([[fx, 0, cx], [0, fy, cy], [0, 0, 1]])
dist_coeffs = np.array([k1, k2, p1, p2, k3])
# 读取图像
image1 = cv2.imread('image1.jpg')
image2 = cv2.imread('image2.jpg')
# 提取特征点
sift = cv2.SIFT_create()
keypoints1, descriptors1 = sift.detectAndCompute(image1, None)
keypoints2, descriptors2 = sift.detectAndCompute(image2, None)
# 特征点匹配
matcher = cv2.BFMatcher(cv2.NORM_L2, crossCheck=True)
matches = matcher.match(descriptors1, descriptors2)
# 提取匹配到的特征点
points1 = np.float32([keypoints1[m.queryIdx].pt for m in matches]).reshape(-1, 1, 2)
points2 = np.float32([keypoints2[m.trainIdx].pt for m in matches]).reshape(-1, 1, 2)
# 相机姿态估计
retval, rvec, tvec, inliers = cv2.solvePnPRansac(points3D, points2D, camera_matrix, dist_coeffs)
# 打印相机位置和朝向
print("Rotation Vector:")
print(rvec)
print("Translation Vector:")
print(tvec)在上述代码中,首先需要读取相机的内参(fx, fy, cx, cy)和畸变系数(k1, k2, p1, p2, k3)。然后,读取两幅图像,并使用SIFT算法提取图像的特征点和特征描述子。接下来,使用特征点匹配算法找到两幅图像之间的对应特征点。然后,使用solvePnPRansac函数进行相机姿态估计,得到相机的旋转向量(rvec)和平移向量(tvec)。最后,打印出相机的位置和朝向。 需要注意的是,上述代码仅为示例,实际应用中可能需要根据具体情况进行调整和优化。另外,还有其他相机姿态估计的方法和库可供选择,如基于直接法的ORB-SLAM、基于深度学习的PNP-Net等。
相机姿态估计的应用
相机姿态估计在许多领域中都有广泛的应用,下面介绍其中的一些应用场景:
增强现实(AR)
在增强现实应用中,相机姿态估计用于将虚拟对象与实际场景进行对齐。通过估计相机的姿态,可以根据相机的位置和朝向来确定虚拟对象的位置和姿态,从而实现虚拟对象与实际场景的融合。
机器人导航
相机姿态估计在机器人导航中起着重要的作用。通过估计相机的姿态,可以确定机器人相对于环境的位置和朝向,从而帮助机器人进行路径规划和导航。
三维重建
在三维重建中,相机姿态估计用于确定多个相机之间的位置和朝向,从而实现对三维场景的重建。通过估计相机的姿态,可以将多个视角的图像融合起来,得到更准确的三维模型。
以下是一个使用Python和NumPy库实现相机姿态估计的示例代码:
pythonCopy codeimport numpy as np
def estimate_camera_pose(points3D, points2D):
# 根据3D-2D点对计算相机姿态
assert len(points3D) == len(points2D), "Number of 3D and 2D points should be the same"
# 将3D点和2D点转换为齐次坐标
points3D_homogeneous = np.hstack((points3D, np.ones((len(points3D), 1))))
points2D_homogeneous = np.hstack((points2D, np.ones((len(points2D), 1))))
# 构造矩阵A
A = np.zeros((2 * len(points3D), 12))
for i in range(len(points3D)):
A[2*i, 4:8] = -points3D_homogeneous[i]
A[2*i, 8:12] = points2D_homogeneous[i, 1] * points3D_homogeneous[i]
A[2*i+1, 0:4] = points3D_homogeneous[i]
A[2*i+1, 8:12] = -points2D_homogeneous[i, 0] * points3D_homogeneous[i]
# 使用SVD分解求解最小二乘问题
_, _, V = np.linalg.svd(A)
P = V[-1].reshape((3, 4))
# 将P分解为相机内参K和旋转矩阵R
K, R = np.linalg.rq(P[:, 0:3])
# 将R调整为右手坐标系
if np.linalg.det(R) < 0:
R = -R
# 计算平移向量t
t = np.linalg.inv(K) @ P[:, 3]
return K, R, t
# 3D点坐标
points3D = np.array([[1, 0, 0],
[0, 1, 0],
[0, 0, 1]])
# 2D点坐标
points2D = np.array([[1, 1],
[2, 2],
[3, 3]])
# 估计相机姿态
K, R, t = estimate_camera_pose(points3D, points2D)
# 打印相机内参K、旋转矩阵R和平移向量t
print("Camera Intrinsic Matrix (K):")
print(K)
print("Rotation Matrix (R):")
print(R)
print("Translation Vector (t):")
print(t)上述代码中,estimate_camera_pose函数实现了相机姿态估计的算法。函数输入为3D点坐标(points3D)和对应的2D点坐标(points2D),输出为相机的内参矩阵K、旋转矩阵R和平移向量t。 在示例代码中,我们假设了3D点和2D点的坐标,并调用estimate_camera_pose函数进行相机姿态估计。最后,打印出相机的内参矩阵K、旋转矩阵R和平移向量t。 请注意,上述代码仅为示例,实际应用中可能需要根据具体情况进行调整和优化。另外,相机姿态估计是一个复杂的问题,还有其他更复杂的算法和方法可供选择,如PnP算法、EPnP算法、直接法(如ORB-SLAM)等。文章来源:https://www.toymoban.com/news/detail-752766.html
结论
相机姿态估计是计算机视觉领域中的一个重要任务,它涉及到确定相机在三维空间中的位置和朝向。本文介绍了相机姿态估计的基本概念、常用方法以及应用领域。随着计算机视觉和深度学习技术的不断发展,相机姿态估计在实际应用中将发挥越来越重要的作用。希望本文能够对相机姿态估计感兴趣的读者有所启发,并为相关研究和应用提供参考。文章来源地址https://www.toymoban.com/news/detail-752766.html
到了这里,关于计算机视觉算法中的 相机姿态估计(Camera Pose Estimation)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!