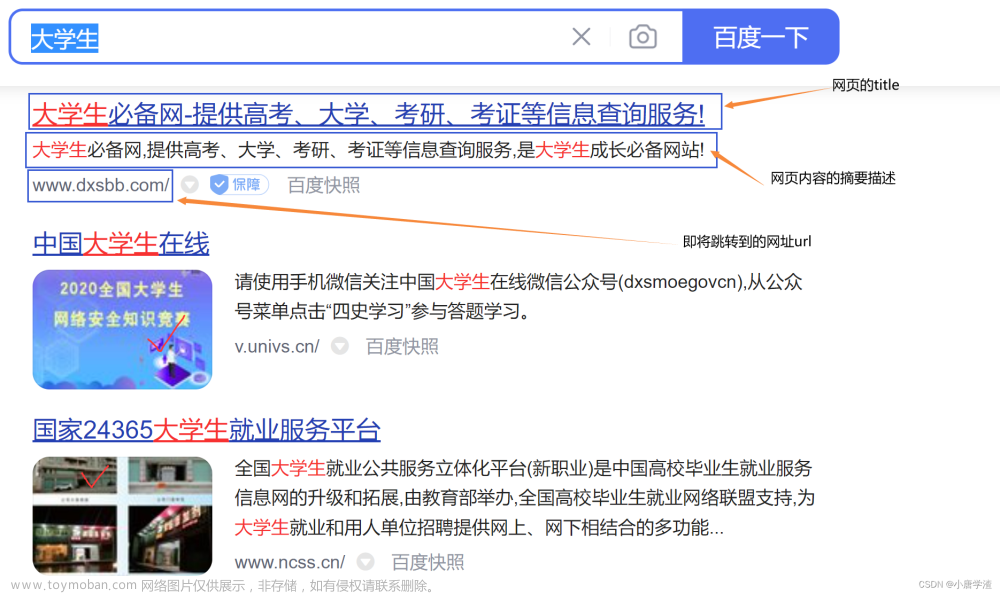
认识搜索引擎
1、有一个主页、有搜索框。在搜索框中输入的内容 称为“查询词”
2、还有搜索结果页,包含了若干条搜索结果
3、针对每一个搜索结果,都会包含查询词或者查询词的一部分或者和查询词具有一定的相关性
4、每个搜索结果包含好几个部分:
a)标题
b)描述 通常是页面的摘要信息
c)子链(子链接)
d)展示 url
e)图片
f)点击 url 点击“点击url”浏览器将跳转到“落地页”

搜索引擎的功能,就是“搜索”=>“查找”;
查找用户输入的查询词在哪些网页(自然搜索结果:网页数据通常是通过爬虫来获取的。广告搜索结果:广告主把物料提交给广告平台)中出现过或者出现过一部分;
把结果展示到网页上。点击结果就能跳转到该页面。
像百度,搜狗这样的搜索引擎,全网搜索。处理的数据量级是非常庞大的。PB级(1PB=1024TB)
咱们现在不具有搞全网搜索的条件(没有那么多服务器),可以搞一个数据量小得多的,站内搜索。
当前所做的搜索引擎,Java API文档
为啥要搜索Java API文档?
1、官方文档上没有一个好用的搜索框
2、Java API 文档数量比较少,当前有限的硬件资源足以处理。(几万个页面)
3、文档内容不需要使用爬虫来获取,可以直接在官网上下载。
搜索引擎是如何工作的?
需要在很多网页数据中找到你输入的查询词(部分查询词)
搜索引擎后台当前已经获取了很多很多的网页数据。每个网页数据都是一个html。称为一个”文档/Document“想要知道的是该查询词在哪些文档中出现过。
1、暴力搜索
一次遍历每个文件,查看当前文件是否包含查询词。(文档数目非常多,依次遍历的话效率就非常低)
2、倒排索引(这是一种特殊的数据结构)
正排索引:docId => 文档内容
根据正排索引制作倒排索引,需要先针对文档内容进行分词(对计算机来说,中文分词是一件很CPU疼的事)
词 => docId 倒排索引 相当于是个键值对的结构(乔布斯这个词在文档1和文档2中都出现过)
正排:根据文档id找到对应文档相关信息
倒排:根据词找到这个词在哪些文档id中存在
这是项目中的最核心的部分。也是一个搜索引擎中的最核心部分。
当我们有了倒排序之后,针对用户输入的查询词就可以快速找到相关联。
实现分词的基本思路:
1、基于词典。几十万个
2、基于概率,统计很多的文本信息
哪两个/三个/四个汉字在一起的概率特别高,那么就说明是一个词。
当前商业公司分词库都能达到99%以上的准确率,分词算法一般都是公司的商业机密。
可以使用现成的第三方库。虽然达不到那么高的准确率,但是也够用。


项目的目标:
实现一个Java API文档的站内搜索引擎 在线API文档
Java API文档有一个线上版本,还有一个可以离线下载的版本 API下载地址。
下载好API文档,分析里面的内容,在搜索结果中填上线上文档的连接地址。
线上文档和线下文档具有一定的对应关系。

后面分析线下文档的时候,就可以根据当前文件的路径拼接出对应的线上文档的url。
项目的模块划分:
1、预处理模块:把下载好的 html 文档进行一次初步的处理(简单分析结构并且干掉其中的 html 标签)
2、索引模块:预处理得到的结果,构建正排+倒排索引
3、搜索模块:完成一次搜索过程基本流程(从用户输入查询词,到得到最终的搜索结果)
4、前端模块:有一个页面,展示结果并且让用户输入数据
1、预处理模块
把 api 目录中所有的html进行处理 => 得到一个单个的文件(为了后面制作索引更方便)。使用行文本的方式来进行组织(组织方式其实也有很多)。
这个得到的临时文件中,每一行对应到一个html文档,每一行中又包含3列。
第一列:表示这个文档的标题
第二列:表示这个文档的url(线上版本文档的url)
第三列:表示这个文档的正文(去掉html格式)
过滤掉标签是为了让搜索结果只集中到正文上
1、创建一个common 包表示每个模块都可能用到的公共信息
创建一个DocInfo类对象

2、创建一个Parser包,表示预处理
创建一个Parser类,遍历文档目录,递归的方式读取所有的html文档内容,把结果解析成一个行文本文件
每一行都对应一个文档,每一行中都包含 文档标题,文档的URL,文档的正文(去掉html标签的内容,去除换行符)
1、枚举出INPUT_PATH 下所有的 html 文件(递归)
2、针对枚举出来的html文件路径进行遍历,依次打开每个文件,并读取内容
把内容转换成需要的结构化的数据(DocInfo对象)
3、把DocInfo对象写入到最终的输出文件中(OUTPUT_PATH)。写成行文本的形式
convertcontent这个方法两件事情: // 1. 把 html 中的标签去掉 // 2. 把 \n 也去掉 eg: <body> <h1>hehe</h1> <div>我是一句话</div> </body> 一个一个字符读取并判定boolean isContent 值为true当前读取的内容是html正文(不是标签)
为false当前读取的内容是标签。
当当前字符为 < 把isContent置为false。把读到的字符直接忽略
当当前字符为 > 把isContent职位true。
如果当前 isContent 为 true 的时候,读到的字符就放到一个StringBuilder中即可。
这里使用字符流
补充:文件是二进制文件,就是用字节流
文件是文本文件,就是用字符流(用记事本打开能看懂的是文本文件)

public class Parser {
// 下载好的 Java API 文档在哪
private static final String INPUT_PATH = "E:\\project\\docs\\api";
// 预处理模块输出文件存放的目录
private static final String OUTPUT_PATH = "E:\\project\\raw_data.txt";
public static void main(String[] args) throws IOException {
FileWriter resultFileWriter = new FileWriter(new File(OUTPUT_PATH));
// 通过 main 完成整个预处理的过程
// 1. 枚举出 INPUT_PATH 下所有的 html 文件(递归)
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH, fileList);
// 2. 针对枚举出来的html文件路径进行遍历, 依次打开每个文件, 并读取内容.
// 把内容转换成需要的结构化的数据(DocInfo对象)
for (File f : fileList) {
System.out.println("converting " + f.getAbsolutePath() + " ...");
// 最终输出的 raw_data 文件是一个行文本文件. 每一行对应一个 html 文件.
// line 这个对象就对应到一个文件.
String line = convertLine(f);
// 3. 把得到的结果写入到最终的输出文件中(OUTPUT_PATH). 写成行文本的形式
resultFileWriter.write(line);
}
resultFileWriter.close();
}
// 此处咱们的 raw_data 文件使用行文本来表示只是一种方式而已.
// 完全也可以使用 json 或者 xml 或者其他任何你喜欢的方式来表示都行
private static String convertLine(File f) throws IOException {
// 1. 根据 f 转换出 标题
String title = convertTitle(f);
// 2. 根据 f 转换出 url
String url = convertUrl(f);
// 3. 根据 f 转换成正文, a) 去掉 html 标签; b) 去掉换行符
String content = convertContent(f);
// 4. 把这三个部分拼成一行文本
// \3 起到分割三个部分的效果. \3 ASCII 值为 3 的字符
// 在一个 html 这样的文本文件中是不会存在 \3 这种不可见字符
// 类似的, 使用 \1 \2 \4 \5....来分割效果也是一样
return title + "\3" + url + "\3" + content + "\n";
}
private static String convertContent(File f) throws IOException {
// 这个方法做两件事情:
// 1. 把 html 中的标签去掉
// 2. 把 \n 也去掉
// 一个一个字符读取并判定
FileReader fileReader = new FileReader(f);
boolean isContent = true;
StringBuilder output = new StringBuilder();
while (true) {
int ret = fileReader.read();
if (ret == -1) {
// 读取完毕了
break;
}
char c = (char)ret;
if (isContent) {
// 当前这部分内容是正文
if (c == '<') {
isContent = false;
continue;
}
if (c == '\n' || c == '\r') {
c = ' ';
}
output.append(c);
} else {
// 当前这个部分内容是标签
// 不去写 output
if (c == '>') {
isContent = true;
}
}
}
fileReader.close();
return output.toString();
}
private static String convertUrl(File f) {
// URL 线上文档对应的 URL
// 线上文档 URL 形如:
// https://docs.oracle.com/javase/8/docs/api/java/util/Collection.html
// 本地目录文档路径形如:
// E:\jdk1.8\docs\api\java\util\Collection.html
// 线上文档的 URL 由两个部分构成.
// part1: https://docs.oracle.com/javase/8/docs/api 固定的
// part2: /java/util/Collection.html 和本地文件的路径密切相关.
// 此处对于 浏览器 来说, / 或者 \ 都能识别.
String part1 = "https://docs.oracle.com/javase/8/docs/api";
String part2 = f.getAbsolutePath().substring(INPUT_PATH.length());
return part1 + part2;
}
private static String convertTitle(File f) {
// 把文件名(不是全路径, 去掉.html后缀)作为标题就可以了
// 文件名: EntityResolver.html
// 全路径: D:\jdk1.8\docs\api\org\xml\sax\EntityResolver.html
String name = f.getName();
return name.substring(0, name.length() - ".html".length());
}
// 当这个方法递归完毕后, 当前 inputPath 目录下所有子目录中的 html 的路径就都被收集到
// fileList 这个 List 中了
private static void enumFile(String inputPath, ArrayList<File> fileList) {
// 递归的把 inputPath 对应的全部目录和文件都遍历一遍
File root = new File(inputPath);
// listFiles 相当于 Linux 上的 ls 命令.
// 就把当前目录下所有的文件和目录都罗列出来了. 当前目录就是 root 对象所对应的目录
File[] files = root.listFiles();
// System.out.println(Arrays.toString(files));
// 遍历当前这些目录和文件路径, 分别处理
for (File f : files) {
if (f.isDirectory()) {
// 如果当前这个 f 是一个目录. 递归调用 enumFile
enumFile(f.getAbsolutePath(), fileList);
} else if (f.getAbsolutePath().endsWith(".html")) {
// 如果当前 f 不是一个目录, 看文件后缀是不是 .html。 如果是就把这个文件的对象
// 加入到 fileList 这个 List 中
fileList.add(f);
}
}
}
}运行:
文件很大,直接打开,加载不出来。使用less命令
less 特点就是打开大文件速度很快。
很多文本编辑器都是尝试把所有文件内容都加载到内存中
less 只加载一小块。显示哪部分就加载哪部分(懒加载)
在 less /Vim 如何显示不可见字符呢?
\1 => ^A
\2 => ^B
\3 => ^C
也可以用head - n 1 xxx


补充:测试项目,测试用例
针对这个预处理程序:
1、验证文件整体格式是否是行文本格式
2、验证每一行是否对应一个html文件
3、验证每一行中是不是都包含3个字段,是否用\3分割
4、验证标题是否和html文件名一直
5、验证url是否是正确的,是否能跳转到线上文档页面
6、验证正文格式是否正确,html标签是否去掉是否把 \n 去掉
当前文件内容很多,如何验证所有行都是包含3个字段?=> 写一个程序来验证,自动化测试
2、索引模块
索引分词
根据 raw_data.txt 得到正排索引和倒排索引 => 分词
分词第三方库有很多 .ansj
安装对应 jar 包
创建Index索引类
引用权重:该词和该文档之间的相关程度。相关程度越高,权重就越大。
实际的搜索引擎或根据查询词和文档之间的相关性进行降序排序,把相关程度越高的文档排到越靠前。相关程度越低的,就排到越靠后。
相关性——有专门的算法工程师团队来做这个事情。(人工智能)
此处就使用简单粗暴的方式来相关性的衡量。
就看这个词在文档中的出现次数,出现次数越多,相关性就越强。
词在标题中出现,就应该相关性比在正文中出现更强一些。
此处设定一个简单粗暴的公式来描述权重。
weight = 标题中出现的次数 * 10 + 正文中出现的次数
正排索引,就是一个数组。docId作为下标,知道docId就可以找到DocInfo。
倒排索引:根据词找到这个词在哪些文档中出现过。


Index 类需要提供的方法
查正排
查倒排 
构建索引,把raw_data.txt 文件内容读取出来,加载到内存上面的数据结构中
索引模块中最复杂的部分
// 构建索引, 把 raw_data.txt 文件内容读取出来, 加载到内存上面的数据结构中
// raw_data.txt 是一个行文本文件. 每一行都有三个部分. 每个部分之间使用 \3 分割
// 索引模块中最复杂的部分
public void build(String inputPath) throws IOException {
class Timer {
public long readFileTime;
public long buildForwardTime;
public long buildInvertedTime;
public long logTime;
}
Timer timer = new Timer();
long startTime = System.currentTimeMillis();
System.out.println("build start!");
// 1. 打开文件, 并且按行读取文件内容
BufferedReader bufferedReader = new BufferedReader(new FileReader(new File(inputPath)));
// 2. 读取到的每一行.
// 加时间是有技巧的. 不应该在比较大的循环中加入过多的打印信息. 打印信息会很多, 看起来很不方便.
// 打印函数本身也是有时间消耗的.
while (true) {
long t1 = System.currentTimeMillis();
String line = bufferedReader.readLine();
if (line == null) {
break;
}
long t2 = System.currentTimeMillis();
// 3. 构造正排的过程: 按照 \3 来切分, 切分结果构造成一个 DocInfo 对象, 并加入到正排索引中
DocInfo docInfo = buildForward(line);
long t3 = System.currentTimeMillis();
// 4. 构造倒排的过程: 把 DocInfo 对象里面的内容进一步处理, 构造出倒排
buildInverted(docInfo);
long t4 = System.currentTimeMillis();
// System.out.println("Build " + docInfo.getTitle() + " done!");
long t5 = System.currentTimeMillis();
timer.readFileTime += (t2 - t1);
timer.buildForwardTime += (t3 - t2);
timer.buildInvertedTime += (t4 - t3);
timer.logTime += (t5 - t4);
}
bufferedReader.close();
long finishTime = System.currentTimeMillis();
System.out.println("build finish! time: " + (finishTime - startTime) + " ms");
System.out.println("readFileTime: " + timer.readFileTime
+ " buildForwardTime: " + timer.buildForwardTime
+ " buildInvertedTime: " + timer.buildInvertedTime
+ " logTime: " + timer.logTime);
}
正排索引:
private DocInfo buildForward(String line) {
// 把这一行按照 \3 切分
// 分出来的三个部分就是一个文档的 标题, URL, 正文
String[] tokens = line.split("\3");
if (tokens.length != 3) {
// 发现文件格式有问题~~
// 当前场景下咱们有 1w 多个文件. 如果某个文件出现格式问题,
// 不应该让某个问题影响到整体的索引构建
// 此处我们的处理方式仅仅就是打印了日志.
System.out.println("文件格式存在问题: " + line);
return null;
}
// 把新的 docInfo 插入到 数组末尾.
// 如果数组是 0 个元素, 新的元素所处在的下标就是 0
DocInfo docInfo = new DocInfo();
// id 就是正排索引数组下标
docInfo.setDocId(forwardIndex.size());
docInfo.setTitle(tokens[0]);
docInfo.setUrl(tokens[1]);
docInfo.setContent(tokens[2]);
forwardIndex.add(docInfo);
return docInfo;
}倒排索引:
private void buildInverted(DocInfo docInfo) {
class WordCnt {
public int titleCount;
public int contentCount;
public WordCnt(int titleCount, int contentCount) {
this.titleCount = titleCount;
this.contentCount = contentCount;
}
}
HashMap<String, WordCnt> wordCntHashMap = new HashMap<>();
// 前 4 个操作都是为了给后面的计算权重做铺垫
// 针对 DocInfo 中的 title 和 content 进行分词, 再根据分词结果构建出 Weight 对象, 更新倒排索引
// 1. 先针对标题分词
List<Term> titleTerms = ToAnalysis.parse(docInfo.getTitle()).getTerms();
// 2. 遍历分词结果, 统计标题中的每个词出现的次数
for (Term term : titleTerms) {
// 此处 word 已经是被转成小写了
String word = term.getName();
WordCnt wordCnt = wordCntHashMap.get(word);
if (wordCnt == null) {
// 当前这个词在哈希表中不存在
wordCntHashMap.put(word, new WordCnt(1, 0));
} else {
// 当前这个词已经在哈希表中存在, 直接修改 titleCount 即可
wordCnt.titleCount++;
}
}
// 3. 再针对正文分词
List<Term> contentTerms = ToAnalysis.parse(docInfo.getContent()).getTerms();
// 4. 遍历分词结果, 统计正文中的每个词出现的次数
for (Term term : contentTerms) {
String word = term.getName();
WordCnt wordCnt = wordCntHashMap.get(word);
if (wordCnt == null) {
// 当前这个词在哈希表中不存在
wordCntHashMap.put(word, new WordCnt(0, 1));
} else {
wordCnt.contentCount++;
}
}
// 5. 遍历 HashMap, 依次构建 Weight 对象并更新倒排索引的映射关系
for (HashMap.Entry<String, WordCnt> entry : wordCntHashMap.entrySet()) {
Weight weight = new Weight();
weight.word = entry.getKey();
weight.docId = docInfo.getDocId();
// weight = 标题中出现次数 * 10 + 正文中出现次数
weight.weight = entry.getValue().titleCount * 10 + entry.getValue().contentCount;
// weight 加入到倒排索引中. 倒排索引是一个 HashMap, value 就是 Weight 构成的 ArrayList
// 先根据这个词, 找到 HashMap 中对应的这个 ArrayList, 称为 "倒排拉链"
ArrayList<Weight> invertedList = invertedIndex.get(entry.getKey());
if (invertedList == null) {
// 当前这个键值对不存在, 就新加入一个键值对就可以了
invertedList = new ArrayList<>();
invertedIndex.put(entry.getKey(), invertedList);
}
// 到了这一步, invertedIndex 已经是一个合法的 ArrayList 了, 就可以把 weight 直接加入即可
invertedList.add(weight);
}
}3、搜索模块
把刚才这些docId所对应的DocInfo信息查找到,组装成一个响应数据.

public class Result {
private String title;
// 当前这个场景中, 这两个 URL 就填成一样的内容了
private String showUrl;
private String clickUrl;
private String desc; // 描述. 网页正文的摘要信息, 一般要包含查询词(查询词的一部分)
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getShowUrl() {
return showUrl;
}
public void setShowUrl(String showUrl) {
this.showUrl = showUrl;
}
public String getClickUrl() {
return clickUrl;
}
public void setClickUrl(String clickUrl) {
this.clickUrl = clickUrl;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
@Override
public String toString() {
return "Result{" +
"title='" + title + '\'' +
", showUrl='" + showUrl + '\'' +
", clickUrl='" + clickUrl + '\'' +
", desc='" + desc + '\'' +
'}';
}
}通过Searcher这个类来完成核心的搜索过程
思路:
1、【分词】针对查询词进行分词
2、【触发】针对查询词的分词结果依次查找倒排索引,得到一大堆相关的 docId
3、【排序】按照权重进行降序排序
4、【包装结果】根据刚才查找到的docId在正排中查找DocInfo,包装成 Result 对象
用户输入的内容到底是啥?
很可能输入的内容中就包含某个词,这个词在所有的文档中都不存在。
当我们针对一个集合类进行排序的时候,往往需要指定比较规则。尤其是集合类内部包含是引用类型的时候。
Comparable:让需要被比较的类实现这个接口,重写compareTo方法
Comparator:创建一个比较器类,实现这个接口,实现的这个接口内部重写compare方法。
class WeightComparator implements Comparator<Index.Weight> {
@Override
public int compare(Index.Weight o1, Index.Weight o2) {
// 如果 o1 < o2 返回一个 < 0
// 如果 o1 > o2 返回一个 > 0
// 如果 o1 == o2 返回 0
return o2.weight - o1.weight;
}
}
/**
* 通过这个类来完成核心的搜索过程
*/
public class Searcher {
private Index index = new Index();
public Searcher() throws IOException {
index.build("d:/raw_data.txt");
}
public List<Result> search(String query) {
// 1. [分词] 针对查询词进行分词
List<Term> terms = ToAnalysis.parse(query).getTerms();
// 2. [触发] 针对查询词的分词结果依次查找倒排索引, 得到一大堆相关的 docId
// 这个 ArrayList 中就保存 每个分词结果 得到的倒排拉链的整体结果
ArrayList<Index.Weight> allTokenResult = new ArrayList<>();
for (Term term : terms) {
// 此处得到的 word 就已经是全小写的内容了. 索引中的内容也是小写的
String word = term.getName();
List<Index.Weight> invertedList = index.getInverted(word);
if (invertedList == null) {
// 用户输入的这部分词很生僻, 在所有文档中都不存在
continue;
}
allTokenResult.addAll(invertedList);
}
// 3. [排序] 按照权重进行降序排序
// 匿名内部类
allTokenResult.sort(new WeightComparator());
// 4. [包装结果] 根据刚才查找到的 docId 在正排中查找 DocInfo, 包装成 Result 对象
ArrayList<Result> results = new ArrayList<>();
for (Index.Weight weight : allTokenResult) {
// 根据 weight 中包含的 docId 找到对应的 DocInfo 对象
DocInfo docInfo = index.getDocInfo(weight.docId);
Result result = new Result();
result.setTitle(docInfo.getTitle());
result.setShowUrl(docInfo.getUrl());
result.setClickUrl(docInfo.getUrl());
// GenDesc 做的事情是从正文中摘取一段摘要信息. 根据当前的这个词, 找到这个词在正文中的位置
// 再把这个位置周围的文本都获取到. 得到了一个片段
result.setDesc(GenDesc(docInfo.getContent(), weight.word));
results.add(result);
}
return results;
}
// 这个方法根据当前的词, 提取正文中的一部分内容作为描述.
// 以下的实现逻辑还是咱们拍脑门出来的.
private String GenDesc(String content, String word) {
// 查找 word 在 content 中出现的位置.
// word 里内容已经是全小写了. content 里头还是大小写都有.
int firstPos = content.toLowerCase().indexOf(word);
if (firstPos == -1) {
// 极端情况下, 某个词只在标题中出现, 而没在正文中出现, 在正文中肯定找不到了
// 这种情况非常少见, 咱们暂时不考虑
return "";
}
// 从 firstPos 开始往前找 60 个字符, 作为描述开始. 如果前面不足 60 个, 就从正文头部开始;
int descBeg = firstPos < 60 ? 0 : firstPos - 60;
// 从描述开始往后找 160 个字符作为整个描述内容. 如果后面不足 160 个, 把剩下的都算上.
if (descBeg + 160 > content.length()) {
return content.substring(descBeg);
}
return content.substring(descBeg, descBeg + 160) + "...";
}
}针对搜索模块的测试
1、针对某个查询词,搜索出来的结构是否都包含指定查询词
2、针对搜索结果,是否按照权重排序
3、针对搜索结果,里面包含的标题,url,描述是否正确
4、URL是否能跳转
5、描述是否包含指定的词
6、描述前面比较短的情况
7、描述后面比较短的情况
8、描述中是否带。。。
9、搜索结果的数目是否符合预期
10、搜索时间是否符合预期
……
搜索模块中核心的搜索类,已经完成了。把搜索类放到一个服务器中,通过服务器来进行搜索过程。
HTTP Servlet。
前后端交互接口
请求:GET /search?query=ArrayList
响应(通过 Json 来组织):
{
{
tiltle:“我是标题”,
showUrl:“我是展示URL”,
clickUrl:“我是点击URL”,
desc:“我是描述信息”,
},
{
}
}
项目部署到云服务器
maven -> package 打包到 target 目录下
当前这个 war 包不能直接放到 Linux 上执行。
Tomcat 肯定会创建 Servlet 实例。Servlet 实例里面包含了 Searcher 对象的实例,又包含了 Index 的实例并且需要进行 build。
build 依赖了一个 raw_data.txt 数据文件。
光把 war 包部署到 Linux 上是不行的,需要把 raw_data.txt 也部署上去,并且要把build 对应的路径给写对。
把 war 包部署到 tomcat 上之后,发现收到第一次请求的时候,才触发了索引构建(Searcher => DocSearcherServlet)
DocSearcherServlet 并不是在 Tomcat 一启动的时候就实例化,而是收到第一个请求的时候才实例化。
问题1:第一次请求响应时间太长了。应该让服务器一启动就创建Servlet 的实例。实例创建好了,索引构造完了,那么后面的响应其实就快了。
让服务器一启动就创建对应 Servlet 的实例,如果这个值 <= 0还是表示收到请求才实例化
如果这个值 >0 表示服务器启动就立刻实例化。
当 >0 的时候,这个值越小,就越先加载。
问题2:如果在加载过程中,用户的请求就来了咋办?
实际的搜索引擎中,会把整个系统拆分成很多不同的服务器。HTTP服务器 + 搜索服务器(需要加载索引启动速度比较慢)这样的情况下 搜索服务器 如果在启动过程中,HTTP请求就来了,HTTP服务器就可以告诉用户“我们还没准备好”
事实上,搜索服务器通常有多台。重启不至于把所有的都重启。总会留下一些可以正常工作的服务器。就能保证HTTP服务器始终能获取到想要的结果。

4、前端模块
写了一个简单的前面页面,用到的技术栈有:
HTML,CSS,JavaScript
Bootstrap:一个用来更好的显示界面的组件库。
JQuery:方便的使用 ajax 和 服务器进行数据交互
Vue:前端框架,方便数据同步展示到界面上

性能优化
运行预处理模块发现执行时间挺长的。
如果要进行性能优化,怎么办?
1、先看这里有没有必要优化,必要性不高。预处理操作其实执行一次就够了
API文档内容是很稳定,内容不变,预处理结果就不变
2、先找到性能瓶颈。枚举目录,转换标题,转换正文,转换URL,写文件??
猜测是这两个,因为涉及到IO操作
3、根据性能瓶颈分析原因,指定解决方案
索引模块有必要进行优化的,构建索引过程,每次服务器启动都需要构建索引
思路还是一样,需要找到性能瓶颈才能优化!
给核心步骤加上时间
构建倒排代码中,性能瓶颈在于分词操作。
分析原因:分词本身就是一个很复杂的操作。
解决方案:文档内容固定,分词结果一定也固定。完全可以在预处理阶段就把标题和正文都分词分好,存到 raw_data 中。后续服务器构建索引,直接加载分词结果即可,不需要重复进行分词。
总时间 = 读文件时间 + 正排索引时间 + 倒排索引时间 + 打印时间
之前IDEA里面执行,log时间就很短。全缓冲,打印换行不会影响刷新缓冲区
在Tomcat上执行,log时间就比较久,行缓冲,每次打印换行都会刷新缓冲区,频繁访问磁盘。
取决于这里打印日志的缓冲策略。
优化手段:把日志去掉~
可以每循环处理1000个文档,打印1条日志。
文章来源:https://www.toymoban.com/news/detail-752935.html
结论:不要在一个频繁循环中加日志。 文章来源地址https://www.toymoban.com/news/detail-752935.html
到了这里,关于搜索引擎项目的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!