论文:《DETRs Beat YOLOs on Real-time Object Detection》 2023.4
DETRs Beat YOLOs on Real-time Object Detection:https://arxiv.org/pdf/2304.08069.pdf
源码地址:https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/rtdetr
本文是RT0-DETR的论文解析,详细部署请查看DETR系列:RT-DETR实战部署
1.目标检测算法发展

第一行是YOLO系列算法的发展过程,第二行是DETR系列算法的发展过程。
2.概述
实时目标检测(Real-Time Object Detection )过去一直由 YOLO 系列模型主导。YOLO 检测器有个较大的待改进点是需要 NMS 后处理,其通常难以优化且不够鲁棒,因此检测器的速度存在延迟。
2020年DETR算法诞生,Detr是第一个基于transformer的端到端算法,没有anchor前处理和NMS后处理,但是Detr收敛慢,训练慢,推理也慢,尽管后续的优化算法不断加快收敛速度,提升推理速度,但仍然无法实现实时要求。
RT-DETR基于DINO检测模型进行改进,首次实现实时端到端检测。
本文的主要贡献总结如下:
本文的主要贡献总结如下
- 提出了第一个实时端到端对象检测器,它不仅在精度和速度方面优于当前的实时检测器,也不需要后期处理,因此它的推理速度没有延迟并且能够保持稳定。
- 本文详细分析了NMS对实时检测器的影响,并从后处理的角度得出了基于CNN的实时检测器的结论(即同等精度情况下,anchor-based算法速度比anchor-free的算法慢)。
- 本文提出的IoU-Aware query选择在我们的模型中显示出优越的性能改进,这为改进目标查询的初始化方案提供了新的思路。
- 本文的工作为端到端检测器的实时实现提供了一个可行的解决方案,并且所提出的检测器可以通过使用不同的解码器层来灵活地调整模型大小和推理速度,而不需要重新训练。
3.NMS分析
NMS在目标检测后处理中应用广泛,主要用来去除重叠的冗余框。NMS有2个超参数:分数阈值和IOU阈值,尤其是,分数低于阈值的检测框不论IOU阈值多大,都会被过滤,因此NMS的执行事件取决于输入的预测框数量,以及2个超参数的值。
本文利用YOLOv5和YOLOv8进行实验。首先输入相同图像,计算不同得分阈值过滤后剩余的预测框数量。分数阈值采样区间是0.001到0.25,对两个检测器的剩余预测框进行计数,并将其绘制成直方图,直观地反映了NMS易受其超参数的影响。此外,本文以YOLOv8为例,在COCO val2017数据集上评估不同NMS超参数下的模型准确性和NMS操作的执行时间,运行设备是GPU T4
从上面图2可以看出,随着分数阈值增大,剩余预测框的数量减少,对于同一个分数阈值,YOLOv5 (anchorbased)剩余框的数量大于YOLOv8 (anchor-free)。从表1可以看出,不同的阈值下推理时间和AP均会变化,超参数会影响算法性能,导致算法不够鲁棒。
4.RT-DETR模型结构
1)Backbone: 采用了经典的ResNet(便于和detr系列算法对比)和百度的HGNet-v2(速度精度由于前者)两种,backbone是可以Scaled,论文只公布ResNet-50和ResNet-101,HGNetv2-l和HGNetv2-x。不同于DINO等DETR类检测器使用最后4个stage输出,RT-DETR为了提速只需要最后3个,下面介绍一下HGNet网络。
PP-HGNet 针对 GPU 设备,对目前 GPU 友好的网络做了分析和归纳,尽可能多的使用 3x3 标准卷积(计算密度最高)。将主要的有利于 GPU 推理的改进点进行融合,从而得到一个有利于 GPU 推理的骨干网络,同样速度下,精度大幅超越其他 CNN 或者 VisionTransformer 模型。
PP-HGNet 骨干网络的整体结构如下:
PP-HGNet是由多个HG-Block组成,HG-Block的细节如下:
PP-HGNet的整体结构由一个Stem模块+四个HG Stage构成,PP-HGNet 的第一层由channel为96的Stem模块构成,目的是为了减少参数量和计算量。stem由一系列ConvBNAct(Conv+BN+Act,添加了use_lab结构,类似于resnet的分支残差),第二层到第五层由HG Stage构成,每个HG Stage主要由包含大量标准卷积的HG Block,其中PP-HGNet的第三到第五层使用了使用了可学习的下采样层(LDS Layer)。其中,可学习的下采样层(Learnable Down-Sampling Layer)是指通过学习参数来进行下采样的一种层次结构。在传统的下采样方法中(如最大池Max Pooling),下采样的过程是固定的,没有可学习的参数。而可学习的下采样层则可以根据输入数据的特征进行动态的下采样,从而提高网络的性能和准确率。PP-HGNet的激活函数为Relu,常数级操作可保证该模型在硬件上的推理速度。
2)Neck:如上图所示,本文提出HybridEncoder,包括两部分:Attention-based Intra-scale Feature Interaction (AIFI) 和 CNN-based Cross-scale Feature-fusion Module (CCFM) 。AIFI只采用了一层普通的Transformer的Encoder,包含标准的MHSA(或者Deformable Attention)和FFN,将二维的s5 特征拉成向量,然后交给AIFI模块处理,随后,再将输出调整回二维,记作 f5 ,以便去完成后续的跨尺度特征融合CCFM。AIFI由几个通道维度区分L和X两个版本,配合CCFM中RepBlock数量一起调节宽度深度实现Scaled RT-DETR。
本文通过一系列实验得出HybridEncoder的设计思路,具体如下图


(a) : 将s3 、 s4 和 s5拼接在一起,不包含Encoder的,即没有自注意力机制,在Backbone之后直接接Decoder去做处理,得到最终的输出。注意,这里的拼接是先将二维的 H×W 拉平成 HW ,然后再去拼接: H1W1+ H2W2+ H3W3 。表3中(a)取得43.0 AP的结果。
(b) :在(a)基础上,加入了单尺度的Transformer Encoder(SSE),仅包含一层Encoder层,分别处理三个尺度的输出,这里三个尺度共享一个SSE,而不是为每一个尺度都设计一个独立的SSE,理论上共享SSE优于独立SSE,因为通过这一共享的操作,三个尺度的信息是可以实现一定程度的信息交互。最后将处理结果拼接在一起,交给后续的网络去处理,得到最终的输出。表3中(b)从43.0提升至44.9,表明使用共享的SSE是可以提升性能的。
© : 使用多尺度的Transformer Encoder(MSE),将三个尺度的特征拼接在一起后,交由MSE来做处理,使得三个尺度的特征同时完成“尺度内”和“跨尺度”的信息交互和融合,最后将处理结果,交给后续的网络去处理,得到最终的输出。C使用MSE来同步完成“尺度内”和“跨尺度”的特征融合,这一做法可以让不同尺度的特征之间得到更好的交互和融合, 表3中©AP指标提升至45.6,这表明MSE的做法是有效的,即“尺度内”和“跨尺度”的特征融合是必要的。但是,从速度的角度来看,Latency从7.2增加值13.3 ms,要高于B组的11.1 ms;
(d) : 先用共享的SSE分别处理每个尺度的特征,然后再使用PAN-like的特征金字塔网络去融合三个尺度的特征,最后将融合后的多尺度特征拼接在一起,交给后续的网络去处理,得到最终的输出。d是相当于解耦了c中的MSE:先使用共享的SSE分别去处理每个尺度的特征,完成“尺度内”的信息交互,然后再用一个PAN风格的跨尺度融合网络去融合不同尺度之间的特征,完成“跨尺度”的信息融合。这种做法可以有效地避免MSE中因输入的序列过长而导致的计算量增加的问题。相较于c,表3中(d)的Latency从13.3 ms降低至12.2 ms,性能也从45.6 AP提升至46.4 AP,这表明MSE的做法并不是最优的,先处理“尺度内”,再完成“跨尺度”,性能会更好;
(DS5) :用一个SSE只处理 s5 特征,随后的跨尺度特征融合和D保持一致。DS5的做法必然会提高推理速度, 表3中(DS5)Latency从12.2 ms降低至7.9 ms,同时,性能从46.4提升至46.8。由此可见,Transformer的Encoder只需要处理 s5 特征即可,不需要再加入浅层特征的信息。
(e) :使用一个SSE处理 s5 特征,即所谓的AIFI模块,随后再使用CCFM模块去完成跨尺度的特征融合,最后将融合后的多尺度特征拼接在一起,交给后续的网络去处理,得到最终的输出。CCFM其实还是PaFPN,其中的Fusion模块就是一个CSPBlock风格的模块,如下图所示
上述实验可以看出:1)以往的DETR,如Deformable DETR是将多尺度的特征都拉平成拼接在其中,构成一个序列很长的向量,尽管这可以使得多尺度之间的特征进行充分的交互,但也会造成极大的计算量和计算耗时。并且相较于较浅的s3特征和s4 特征,s5 特征拥有更深、更高级、更丰富的语义特征,这些语义特征是Transformer更加感兴趣的和需要的,对于区分不同物体的特征是更加有用的,而浅层特征因缺少较好的语义特征而起不到什么作用。实验结果也证明,Transformer的Encoder部分只需要处理s5的特征,既能大幅度削减计算量、提升计算速度,同时也不会降低性能,甚至还有所提升;2)对于多尺度特征的交互和融合,我们仍可以采用CNN架构常用的PAN网络来搭建,只需要一些细节上的调整即可。
3)Transformer: 起名为RTDETRTransformer,基于DINO Transformer中的decoder改动的不多;
4)Head和Loss: 和DINOHead基本一样,使用到了DINO的“去噪思想”来提升匹配的样本质量,加快训练的收敛速度。不过,有一个细节上的调整,那就是在assignment阶段和计算loss的阶段,classification的标签都换成了IoU-Aware查询选择,将IoU分数引入分类分支的目标函数,以实现对正样本分类和定位的一致性约束。因为按照以往情况,有可能出现“当定位还不够准确的时候,类别就已经先学好了”的“未对齐”的情况,毕竟类别的标签非0即1。但如果将预测框与GT的IoU作为类别预测的标签,那么类别的学习就要受到回归的调制,只有当回归学得也足够好的时候,类别才会学得足够好,否则,类别不会过快地先学得比回归好,因此后者显式地制约着前者。
5)Reader和训练策略:
训练测试数据:本文在COCO train2017数据集上训练,在COCO val2017数据集验证,使用单尺度图像在COCO AP矩阵验证。Reader采用的是YOLO常用的640尺度,没有DETR类检测器复杂的多尺度resize。
网络:使用ImageNet上预训练的ResNet和HGNetv2系列作为骨干网络。AIFI由1层transformer 构成,CCMF由3个RepBlocks构成。在IoU-aware查询选择中,使用encoder的top 300特征来初始化decoder的query。训练的策略和decoder的超参数与DINO一致。用AdamW优化器训练,其他参数配置为base learning rate = 0:0001,weight decay = 0:0001, global gradient clip norm =0:0001, and linear warmup steps = 2000. ema decay = 0:9999.骨干网络学习率同detr。数据增强采用的是基础的随机颜色抖动、随机翻转、裁剪和 Resize,0均值1方差的NormalizeImage大概是为了节省部署时图片前处理的耗时,没有用mosaic等trick。默认在 COCO train2017 上训练 6x ,即72个epoch。
6)模型详情:
如上图所示,本文提供ResNet、HGNetv2系列2个版本。使用depth multiplier和width multiplier将Backbone和混合编码器一起缩放。因此,得到了具有不同数量的参数和FPS的RT-DETR的两个版本。对于混合编码器,通过分别调整CCFM中RepBlock的数量和编码器的嵌入维度来控制depth multiplier和width multiplier。值得注意的是,提出的不同规模的RT-DETR保持了同质解码器,这有助于使用高精度大型DETR模型对光检测器进行蒸馏。
5.性能对比
-
yolo系列精度对比

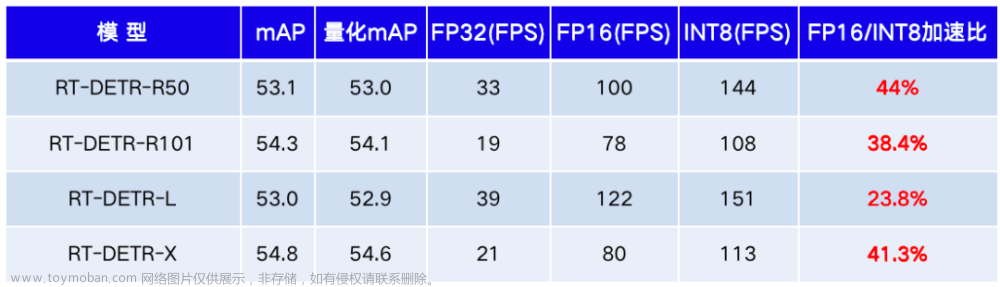
相同尺度的版本下,RT-DETR速度和精度都超过yolo系列,在 COCO val2017 上的精度为 53.0% AP ,在 T4 GPU 上的 FPS 为 114,RT-DETR-X 的精度为 54.8% AP,FPS 为 74。
并且RT-DETR只训练72个epoch,而先前精度最高的YOLOv8需要训练500个epoch,其他YOLO也基本都需要训300epoch。此外RT-DETR的HGNET版本参数量FLOPs也低于yolo系列。 -
对比DETR系列

RT-DETR-R50 在 COCO val2017 上的精度为 53.1% AP,在 T4 GPU 上的 FPS 为 108,RT-DETR-R101 的精度为 54.3% AP,FPS 为 74。总结来说,RT-DETR 比具有相同 backbone 的 DETR 系列检测器有比较显著的精度提升和速度提升。DETR类在COCO上常用的尺度都是800x1333,而RT-DETR采用640x640尺度,精度也能高于之前的DETR系列模型。
6.参考资料
https://blog.csdn.net/PaddlePaddle/article/details/130355297文章来源:https://www.toymoban.com/news/detail-753083.html
https://zhuanlan.zhihu.com/p/626659049文章来源地址https://www.toymoban.com/news/detail-753083.html
到了这里,关于DETR系列:RT-DETR(一) 论文解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!