目录
Spark是什么
一、Spark与MapReduce对比区别
二、Spark的发展
三、Spark的特点
四、Spark框架模块
Spark是什么
Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎,是一个分布式计算框架。
一、Spark与MapReduce对比区别
-
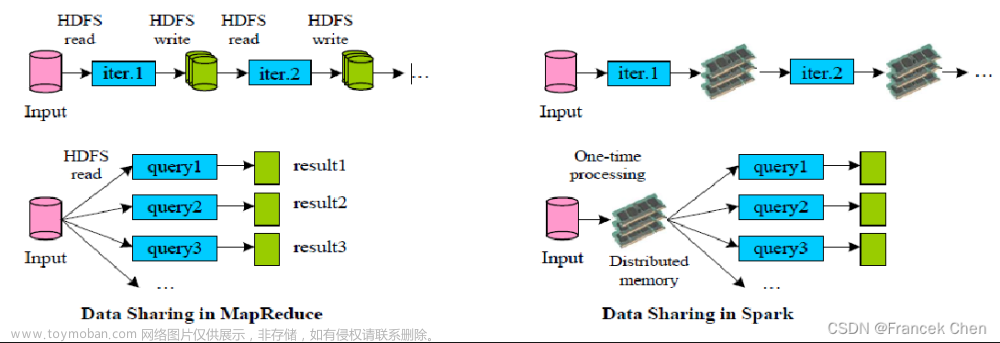
Spark中新的数据结构RDD(弹性分布式数据集),使得大数据分析能够基于内存计算,会将中间结过存放在内存,方便后续计算的使用。MapReduce会将中间结果存储在磁盘上。
-
内存数据的读写速度要比磁盘快的多,所以Spark的计算速度要比MapReduce快
-
Spark对海量数据在内存上的计算做了优化,内存不足时会将结果存在磁盘上,适合海量数据处理,并且可以进行库表创建
-
-
Spark的计算任务是由线程完成的。MapReduce的计算任务是由进程完成的。线程切换计算任务的速度比进程切换计算任务速度快
-

二、Spark的发展

三、Spark的特点
-
高效性
-
计算速度快
-
提供了一个全新的数据结构RDD(弹性分布式数据集)。整个计算操作,基于内存计算。当内存不足的时候,可以放置到磁盘上。整个流程是基于DAG(有向无环图)执行方案。
-
线程完成计算任务执行
-
-
-
易用性
-
支持多种语言开发 (Python,SQL,Java,Scala,R),降低了学习难度
-
-
通用性
-
在 Spark 的基础上,Spark 还提供了包括Spark SQL、Spark Streaming、MLlib 及GraphX在内的多个工具库,我们可以在一个应用中无缝地使用这些工具库。
-
-
兼容性(任何地方运行)
-
支持三方工具接入
-
存储工具
-
hdfs
-
kafka
-
hbase
-
-
资源调度
-
yarn
-
Kubernetes(K8s)
-
standalone(spark自带的)
-
-
高可用
-
zookeeper
-
-
-
支持多种操作系统
-
Linux
-
windows
-
Mac
-
-
四、Spark框架模块
1,Spark Core API:实现了 Spark 的基本功能。包含RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。数据结构RDD。
2,Spark SQL:我们可以使用 SQL处理结构化数据。数据结构:Dataset/DataFrame = RDD + Schema
3,Structured Streaming:基于Spark SQL进行流式/实时的处理组件,主要处理结构化数据。
4,Streaming(Spark Streaming):提供的对实时数据进行流式计算的组件,底层依然是离线计算,只不过时间粒度很小,攒批。
5,MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等。
6,GraphX:Spark中用于图计算的API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。

五、Spark集群模式架构

-
Spark的集群主要角色有:【Master主节点和Worker从节点】
-
主节点Master作用:
-
【管理从节点,管理集群资源】
-
【接收Spark的请求】
-
【分配Driver到某一个Worker从节点上启动】
-
-
从节点Worker作用:
-
【接收Driver分配的任务,执行具体任务】
-
【向Master汇报心跳,任务的运行状态信息等】文章来源:https://www.toymoban.com/news/detail-753368.html
-
【启动Driver程序】文章来源地址https://www.toymoban.com/news/detail-753368.html
-
到了这里,关于Spark基本介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!