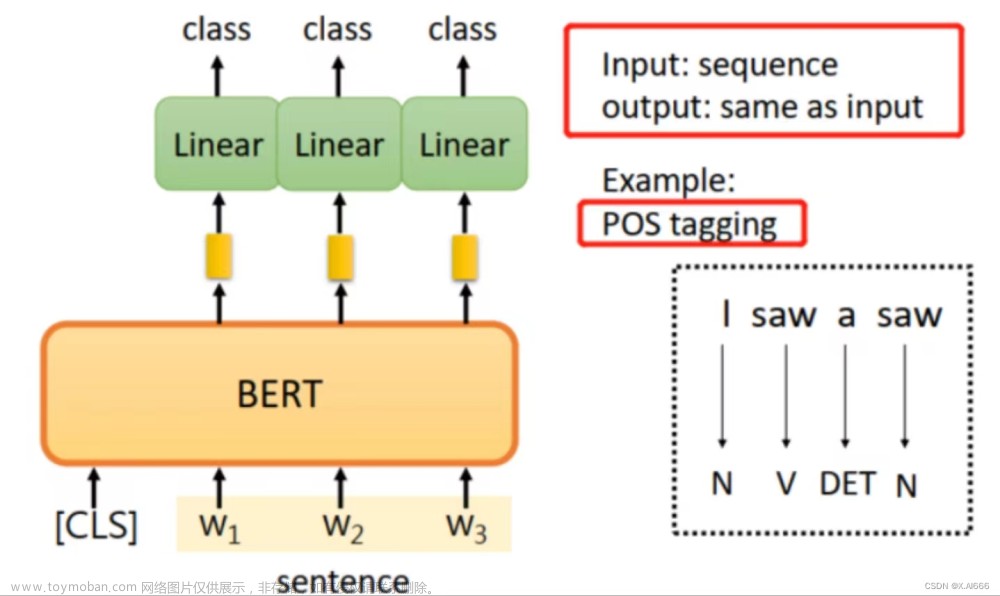
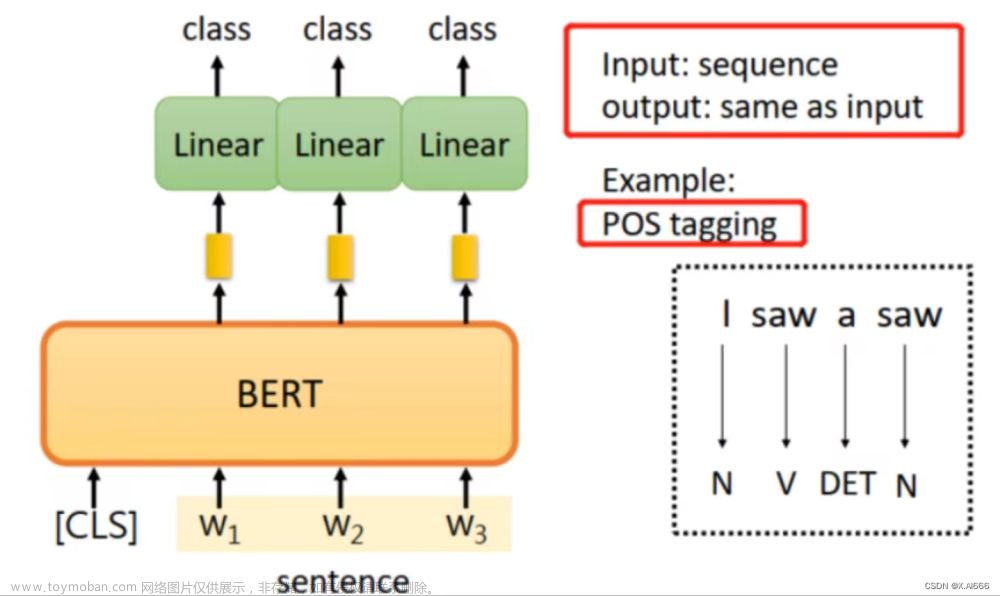
本文介绍两种赋予大模型使用外部工具能力的方法:Toolformer和ART。
Toolformer论文地址:https://arxiv.org/pdf/2302.04761.pdf
ART论文地址:https://arxiv.org/pdf/2303.09014.pdf
相关博客
【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer
【自然语言处理】【大模型】MPT模型结构源码解析(单机版)
【自然语言处理】【大模型】ChatGLM-6B模型结构代码解析(单机版)
【自然语言处理】【大模型】BLOOM模型结构源码解析(单机版)
【自然语言处理】【大模型】极低资源微调大模型方法LoRA以及BLOOM-LORA实现代码
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
一、Toolformer

大语言模型(LLM)效果惊人,但是仍然存在规模无法解决的局限性。这些局限性有:无法获得最新的信息以及产生幻觉的倾向、难以理解低资源语言、缺乏精确的数学计算能力、无法意识到时间推移。
为了克服这些限制,一种可能的选择是赋予其使用外部工具的能力。但是,现有方法依赖于大量的人工标注数据或者仅限制在特定的任务上。Toolformer提出了一种新的方法,其不需要大量人工标注且不影响LLM的通用性。
Toolformer的理想结果就如上图1所示,在生成的文本中间产生外部工具调用命令。
Toolformer核心思想其实很简单:通过prompt让模型生成满足指令要求的候选文本,然后利用自动化的方法过滤出高质量的结果,用于微调。
1. API调用序列化
Toolformer的目标是赋予语言模型
M
M
M调用不同工具的能力。这需要外部工具API的输入输出都表示为文本序列,这样才能无缝嵌入至语言模型上。将API调用表示为一个元组
c
=
(
a
c
,
i
c
)
c=(a_c,i_c)
c=(ac,ic),
a
c
a_c
ac是API的名称,
i
c
i_c
ic是输入。若
r
r
r是API调用的结果,那么API调用不包含结果
e
(
c
)
e(c)
e(c)和包含结果
e
(
c
,
r
)
e(c,r)
e(c,r)定义为:
e
(
c
)
=
<API>
a
c
(
i
c
)
</API>
e
(
c
,
r
)
=
<API>
a
c
(
i
c
)
→
r
</API>
e(c)=\text{<API>}a_c(i_c)\text{</API>} \\ e(c,r)=\text{<API>}a_c(i_c)\rightarrow r\text{</API>}
e(c)=<API>ac(ic)</API>e(c,r)=<API>ac(ic)→r</API>
其中,
<API>
\text{<API>}
<API>、
</API>
\text{</API>}
</API>和
→
\rightarrow
→是特殊tokens。
2. 自动构建微调数据集

本小节的目标是:给定一个普通的文本数据集 C = { x 1 , … , x ∣ C ∣ } \mathcal{C}=\{x^1,\dots,x^{|\mathcal{C}|}\} C={x1,…,x∣C∣},使用API调用形成增强数据集 C ∗ \mathcal{C}^* C∗,用于后续的模型微调。完整的构造流程如上图2所示,下面详细介绍整个过程。
2.1 采样API调用

对于每个API(也就是工具),人工撰写prompt P ( x ) P(\textbf{x}) P(x)来鼓励语言模型为样本序列 x = x 1 , … , x n \textbf{x}=x_1,\dots,x_n x=x1,…,xn生成API调用。如上图3中,Input上的大段文本指令就是针对问答系统人工撰写的prompt。
令
p
M
(
z
n
+
1
∣
z
1
,
…
,
z
n
)
p_M(z_{n+1}|z_1,\dots,z_n)
pM(zn+1∣z1,…,zn)表示模型
M
M
M在已知前
n
n
n个token的序列
z
1
,
…
,
z
n
z_1,\dots,z_n
z1,…,zn情况下,
z
n
+
1
z_{n+1}
zn+1的条件概率。那么,在位置
i
∈
{
1
,
…
,
n
}
i\in\{1,\dots,n\}
i∈{1,…,n}处开始API调用的概率为
p
i
=
p
M
(
<API>
∣
P
(
x
)
,
x
1
:
i
−
1
)
p_i=p_M(\text{<API>}|P(x),x_{1:i-1})
pi=pM(<API>∣P(x),x1:i−1)
直观上来看,序列 x \textbf{x} x并不是所有的位置都适合作为API调用的开始。因此,Toolformer采用了基于概率的过滤规则。给定一个采样阈值 τ s \tau_s τs,那么仅保留概率高于该阈值的位置,即 I = { i ∣ p i > τ s } I=\{i|p_i>\tau_s\} I={i∣pi>τs}。若这样的位置仍然大于 k k k个,那么就取topk。
对于每个位置 i ∈ I i\in I i∈I,模型 M M M都可以采样出 m m m个API调用序列 c i 1 , … , c i m c_i^1,\dots,c_i^m ci1,…,cim,其中所有的 c i c_i ci都是以序列 [ P ( x ) , x 1 , … , x i − 1 , <API> ] [P(\textbf{x}),x_1,\dots,x_{i-1},\text{<API>}] [P(x),x1,…,xi−1,<API>]为前缀,并以 </API> \text{</API>} </API>为结尾的。
2.2 执行API调用
执行生成的API调用序列。具体的执行方式,依赖于API本身,例如:这个API可以是调用令一个神经网络、执行Python脚本或者使用检索系统。API调用 c i c_i ci产生的结果文本序列表示为 r i r_i ri。
2.3 过滤API调用
前面的步骤中,采样了 k k k个位置,每个位置 m m m个API调用序列,总结 k × m k\times m k×m个调用序列。显然,这个量并不小,且无法保证参数的API调用序列的质量。那么就需要对这些API调用进行过滤。
在序列
x
=
x
1
,
…
,
x
n
\textbf{x}=x_1,\dots,x_n
x=x1,…,xn的位置
i
i
i产生的API调用表示为
c
i
c_i
ci,执行调用产生的结果表示为
r
i
r_i
ri。此外,给定一个权重序列
(
w
i
∣
i
∈
N
)
(w_i|i\in\mathbb{N})
(wi∣i∈N)以及前缀序列
z
\textbf{z}
z时,模型
M
M
M在token序列
x
i
,
…
,
x
n
x_i,\dots,x_n
xi,…,xn的加权交叉熵损失表示为
L
i
(
z
)
=
−
∑
j
=
i
n
w
j
−
i
⋅
log
p
M
(
x
j
∣
z
,
x
1
:
j
−
1
)
L_i(\textbf{z})=-\sum_{j=i}^n w_{j-i}\cdot\log p_{M}(x_j|\textbf{z},x_{1:j-1})
Li(z)=−j=i∑nwj−i⋅logpM(xj∣z,x1:j−1)
注:1. 这里的权重序列是需要人工指定的;2. 这个loss仅是用来比较的,不是用来优化的。
这里在定义两个不同的loss实例:
L
i
+
=
L
i
(
e
(
c
i
,
r
i
)
)
L
i
−
=
min
(
L
i
(
ε
)
,
L
i
(
e
(
c
i
,
ε
)
)
)
L_i^+=L_i(e(c_i,r_i)) \\ L_i^-=\min(L_i(\varepsilon),L_i(e(c_i,\varepsilon)))
Li+=Li(e(ci,ri))Li−=min(Li(ε),Li(e(ci,ε)))
其中,
ε
\varepsilon
ε表示空序列,
L
i
(
ε
)
L_i(\varepsilon)
Li(ε)表示没有进行API调用的loss值,
L
i
(
e
(
c
i
,
ε
)
)
L_i(e(c_i,\varepsilon))
Li(e(ci,ε))表示进行API调用但没有执行结果的loss值,
L
i
(
e
(
c
i
,
r
i
)
)
L_i(e(c_i,r_i))
Li(e(ci,ri))表示进行API调用且有结果的loss值。直觉上,API调用并返回结果应该是有助于模型
M
M
M预测下一个token的。因此,设置一个过来阈值
τ
f
\tau_f
τf,然后仅保留满足下面要求的API调用
L
i
−
−
L
i
+
≥
τ
f
L_i^--L_i^+\geq \tau_f
Li−−Li+≥τf
也就是说,API调用至少将loss降低了
τ
f
\tau_f
τf。
3. 模型微调与推理
微调。在完成API调用采样和过滤后,将API调用和原始输入交叠合并。对于输入文本 x = x 1 , … , x n \textbf{x}=x_1,\dots,x_n x=x1,…,xn以及其对应的API调用和结果 ( c i , r i ) (c_i,r_i) (ci,ri),那么构造新序列 x ∗ = x 1 : i − 1 , e ( c i , r i ) , x i : n \textbf{x}^*=x_{1:i-1},e(c_i,r_i),x_{i:n} x∗=x1:i−1,e(ci,ri),xi:n。对于所有的 x ∈ C \textbf{x}\in\mathcal{C} x∈C应用该操作得到新数据集 C ∗ \mathcal{C}^* C∗。使用这个数据集微调模型 M M M。
推理。模型 M M M经过微调后,在生成时执行正常的解码,直至产生" → \to →" token,其表示接下来的预测是API调用。此时,中断解码过程,调用适当的API获得响应结果,并将响应结果和</API>插入序列之后,继续解码。
4. 工具
Toolformer通过不同工具来解决语言模型的缺点。这些工具需要满足:(1) 输入和输出都可以表示为序列化的文本;(2) 能够得到一些工具使用的示例。这里探索了5种工具:问答系统、Wikipedia搜索引擎、计算器、日历、机器翻译系统。
二、ART

1. 总览
ART的思路不同于Toolformer。ART使用特定的program语法构建一个任务库。当新任务到来时,会从任务库中检索相似的任务,并将这些任务的实体添加至prompt中。
在生成时,LLM生成program。ART解析这些program,当遇到工具调用是会暂停语言模型生成,但调用完成后再恢复生成。
此外,ART也可以引入人工反馈,从而改善在特定任务上的表现。
2. 任务库
将BigBench中的部分任务作为种子,构建program库。BigBench任务包含了传统NLP、数学、常识推理和问答等任务。
2.1 构建任务库
经过分析,BigBench中超过一半的任务会使用算术、代码、搜索、自由形式推理和字符串操作。因此,基于这5种技能对BigBench中的任务进行分组。
在每个分组中挑选2-4任务,为每个任务人工撰写program(任务分解),这些program包含了外部工具的调用以及调用的输出。这些编写的program遵循下面的语法。
2.2 program语法
program的格式必须灵活的满足各种任务、输入、工具等,且能够覆盖各种NLP任务。因此,这里定义了一种查询语言,其可以按顺序来表达被分解的推理步骤以及合并调用外部工具的函数。每个program均由一系列的节点组成:一个输入节点、若干个子步骤节点、一个答案节点。输入节点由任务名称、描述任务的指令以及任务输入的实例:
Answer this high-school Physics question
Input:Hector yanks...
\begin{align} &\text{Answer this high-school Physics question} \\ &\text{Input:Hector yanks...} \end{align}
Answer this high-school Physics questionInput:Hector yanks...
输入节点后跟随一组子任务节点,表示为(query, answer)对
Q1:[search] What is the formula...
#1: The horizontal component (Fx) can be calculated...
\begin{align} &\text{Q1:[search] What is the formula...} \\ &\text{\#1: The horizontal component (Fx) can be calculated...} \end{align}
Q1:[search] What is the formula...#1: The horizontal component (Fx) can be calculated...
Q
i
Q_i
Qi不但有任务名称,也包含输入;答案
#
i
\#i
#i就是该子任务的输出。program以虚拟子程序
(
Q3:[EOQ]
)
(\text{Q3:[EOQ]})
(Q3:[EOQ])表示结束,并在末尾添加最终的答案节点
(
Ans: 59N
)
(\text{Ans: 59N})
(Ans: 59N)。上图2展示了这种格式。
2.3 任务检索
对于新的任务,ART从任务库中检索N个任务来构造一个动态多任务prompt。这里探索两种检索相似任务的策略。
若新任务有少量的标注样本( ≈ 50 \approx 50 ≈50),遍历5个任务组,并从每个组中选择少量的任务program来组成prompt。最后,在预留出的样本集上进行预测,选择表现最好的任务组。该策略需要一组“输入-输出”,但不需要额外的监督来生成分解的program。
第二种策略,构建一个few-shot prompt,每个任务包含名称、指令和少量的"输入-输出"样本。每对样本,提供标签"Similar"或"Not similar"。在推理时,将测试任务与任务库中的每个任务构成一个样本对,基于"Similar"和"Not similar"的对数概率来选择排名最高的任务。
3. 工具库
当子任务的查询名称与工具名称匹配(例如: Q i = [search] Q_i=\text{[search]} Qi=[search]),则生成被暂停;工具调用完成并将结果合并至输出后在继续生产。接下来,将描述用于表示这些工具及其输入所使用的符号,以及如何将工具的输出合并至原始的program。
3.1 搜索
搜索使用SerpAPI,其能够提供基于Google的搜索。搜索是输入就是语言模型在
Q
i
:
[search]
Q_i:\text{[search]}
Qi:[search]后生成的序列。可以合并搜索的top-2结果至原始序列中。如上图2(B)所示,搜索的query就是在原始输入后的
What is the formula for the horizontal component of tension force?
\text{What is the formula for the horizontal component of tension force?}
What is the formula for the horizontal component of tension force?
输出是
...horizontal component (Fx) can be calculated as Ftens*cosine
(
θ
)
\text{...horizontal component (Fx) can be calculated as Ftens*cosine}(\theta)
...horizontal component (Fx) can be calculated as Ftens*cosine(θ)
3.2 代码生成
使用CodeX作为代码生成工具。代码生成工具的输入是,语言模型在子任务查询符号
Q
i
:
[
generate python code
]
Q_i:[\text{generate python code}]
Qi:[generate python code]后生成的序列,其作为python代码的注释来提示CodeX。如上图2(B)所示,使用下面的序列作为CodeX生成时的提示:
Use the formula Fx=Ftens*consine
(
θ
)
to solve...
\text{Use the formula Fx=Ftens*consine}(\theta)\text{ to solve...}
Use the formula Fx=Ftens*consine(θ) to solve...
CodeX生成输出
T = 72.0, theta = 35.0, ..., Fx = T*math.cos(radians)
\text{T = 72.0, theta = 35.0, ..., Fx = T*math.cos(radians)}
T = 72.0, theta = 35.0, ..., Fx = T*math.cos(radians)
3.3 代码执行
在Python环境中安装算术、符号和科学计算的包,使用该环境执行python代码。代码执行工具的输入参数就是前一个子任务的答案 # ( i − 1 ) : … \#(i-1):\dots #(i−1):…。上图2(B)中,前一个步骤生成的代码将被送入代码执行工具,并将变量"Fx"的值加入到未完全生成的序列中。
4. 人工反馈

ART是专门为适应人工反馈设计的。用户通过编辑任务库或者工具库,从而将反馈合并至ART中。ART生成的多步推理program是可解释的,因此能够以debug的方式来探索和反馈。通过编辑的方式纠正子步骤的输出、添加/移除子步骤、添加新工具的调用。
上图3(a)用户添加了两个子步骤:(1) 舍入为整数;(2) 包含合适的单位。上图3(b),展示了如何添加新的工具。
5. ART和Toolformer比较

三、总结
本文介绍了两种赋予到模型使用工具能力的方法:Toolformer和ART。文章来源:https://www.toymoban.com/news/detail-753442.html
- Toolformer的思路:通过prompt令语言模型生成一些能够调用工具的样本,然后利用语言模型对文本的困惑度来过滤这些样本,得到高质量的数据集。最后,利用高质量数据集微调语言模型,赋予其使用工具的能力。
- ART的思路:人工构建一下常见的工具使用样本,然后利用新任务与已有任务的相似性来辅助语言模型使用工具。(ART文章写的真是一言难尽)
两种方法虽然实现思路不同,但是仍然属于prompt工程范畴。语言模型本身的能力,限制了这些方法的可用性。也就是说,语言模型本身的效果不是特别好的话,这些方法也能够有好的效果。文章来源地址https://www.toymoban.com/news/detail-753442.html
到了这里,关于【自然语言处理】【大模型】赋予大模型使用工具的能力:Toolformer与ART的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!