最近在做视频处理相关的业务。其中有需要将视频提取字幕的需求,在我们实现过程中分为两步:先将音频分离,然后就用到了whisper来进行语音识别或者翻译。本文将详细介绍一下whisper的基本使用以及在python中调用whisper的两种方式。
一、whisper简介
whisper 是一款用于语音识别的开源库,支持多种语言,其中包括中文。在本篇文章中,我们将介绍如何安装 whisper 以及如何使用它来识别中文字幕。
二、安装 whisper
首先,我们需要安装 whisper。根据操作系统,可以按照以下步骤进行安装:
-
对于 Windows 用户,可以从 whisper 的 GitHub 页面 (https://github.com/qingzhao/whisper) 下载适用的 Python 版本的whisper 安装包,然后运行安装程序。
-
对于 macOS 用户,可以使用 Homebrew (https://brew.sh/) 进行安装。在终端中运行以下命令:
brew install python@3.10 whisper。 -
对于 Linux 用户,可以使用包管理器 (如 apt 或 yum) 进行安装。例如,对于使用 Python 3.10 的 Ubuntu 用户,在终端中运行以下命令:
sudo apt install python3.10 whisper。
当然,我们还需要配置环境,这里我们可以参考这篇文章,这篇文章是使用控制台的方式来进行字幕翻译,比较适合非开发人员。
三、使用Whisper提取视频字幕并生成文件
3.1 安装Whisper库
首先,我们需要安装Whisper库。可以使用以下命令在命令行中安装:
pip install whisper
3.2 导入所需的库和模块
import whisper
import arrow
import time
from datetime import datetime, timedelta
import subprocess
import re
import datetime
参考 python生成requirements.txt的两种方法
生成失败参考 这里
对应版本生成的requirements.txt信息
arrow==1.3.0
asposestorage==1.0.2
numpy==1.25.0
openai_whisper==20230918
3.3 提取字幕并生成文件
下面是一个函数,用于从目标视频中提取字幕并生成到指定文件:
1.在python中直接调库的方式
def extract_subtitles(video_file, output_file, actual_start_time=None):
# 加载whisper模型
model = whisper.load_model("medium") # 根据需要选择合适的模型
subtitles = []
# 提取字幕
result = model.transcribe(video_file)
start_time = arrow.get(actual_start_time, 'HH:mm:ss.SSS') if actual_start_time is not None else arrow.get(0)
for segment in result["segments"]:
# 计算开始时间和结束时间
start = format_time(start_time.shift(seconds=segment["start"]))
end = format_time(start_time.shift(seconds=segment["end"]))
# 构建字幕文本
subtitle_text = f"【{start} -> {end}】: {segment['text']}"
print(subtitle_text)
subtitles.append(subtitle_text)
# 将字幕文本写入到指定文件中
with open(output_file, "w", encoding="utf-8") as f:
for subtitle in subtitles:
f.write(subtitle + "\n")
2.在python中调用控制台命令
"""
从目标视频中提取字幕并生成到指定文件
参数:
video_file (str): 目标视频文件的路径
output_file (str): 输出文件的路径
actual_start_time (str): 音频的实际开始时间,格式为'时:分:秒.毫秒'(可选)
target_lang (str): 目标语言代码,例如'en'表示英语,'zh-CN'表示简体中文等(可选)
"""
def extract_subtitles_translate(video_file, output_file, actual_start_time=None, target_lang=None):
# 指定whisper的路径
whisper_path = r"D:\soft46\AncondaSelfInfo\envs\py39\Scripts\whisper"
subtitles = []
# 构建命令行参数
command = [whisper_path, video_file, "--task", "translate", "--language", target_lang, "--model", "large"]
if actual_start_time is not None:
command.extend(["--start-time", actual_start_time])
print(command)
try:
# 运行命令行命令并获取字节流输出
output = subprocess.check_output(command)
output = output.decode('utf-8') # 解码为字符串
subtitle_lines = output.split('\n') # 按行分割字幕文本
start_time = time_to_milliseconds(actual_start_time) if actual_start_time is not None else 0
for line in subtitle_lines:
line = line.strip()
if line: # 空行跳过
# 解析每行字幕文本
match = re.match(r'\[(\d{2}:\d{2}.\d{3})\s+-->\s+(\d{2}:\d{2}.\d{3})\]\s+(.+)', line)
if match:
# 这是秒转时间
# start = seconds_to_time(start_time + time_to_seconds(match.group(1)))
# end = seconds_to_time(start_time + time_to_seconds(match.group(2)))
start = start_time + time_to_milliseconds(match.group(1))
end = start_time + time_to_milliseconds(match.group(2))
text = match.group(3)
# 构建字幕文本 自定义输出格式
subtitle_text = f"【{start} -> {end}】: {text}"
print(subtitle_text)
subtitles.append(subtitle_text)
# 将字幕文本写入指定文件
with open(output_file, "w", encoding="utf-8") as f:
for subtitle in subtitles:
f.write(subtitle + "\n")
except subprocess.CalledProcessError as e:
print(f"命令执行失败: {e}")
3.4 辅助函数
在上述代码中,还使用了一些辅助函数,用于处理时间格式的转换和格式化:
def time_to_milliseconds(time_str):
h, m, s = time_str.split(":")
seconds = int(h) * 3600 + int(m) * 60 + float(s)
return int(seconds * 1000)
def format_time(time):
return time.format('HH:mm:ss.SSS')
def format_time_dot(time):
return str(timedelta(seconds=time.total_seconds())).replace(".", ",")[:-3]
# 封装一个计算方法运行时间的函数
def time_it(func, *args, **kwargs):
start_time = time.time()
print("开始时间:", time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(start_time)))
result = func(*args, **kwargs)
end_time = time.time()
total_time = end_time - start_time
minutes = total_time // 60
seconds = total_time % 60
print("结束时间:", time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(end_time)))
print("总共执行时间: {} 分 {} 秒".format(minutes, seconds))
return result
3.5 调用函数提取字幕
可以使用以下代码调用上述函数,并提取字幕到指定的输出文件中:
if __name__ == '__main__':
video_file = "C:/path/to/video.mp4" # 替换为目标视频文件的路径
output_file = "C:/path/to/output.txt" # 替换为输出txt文件的路径
actual_start_time = '00:00:00.000' # 替换为实际的音频开始时间,格式为'时:分:秒.毫秒',如果未提供则默认为00:00:00.000时刻
# 直接在main方法中调用
# extract_subtitles(video_file, output_file, actual_start_time)
time_it(extract_subtitles_translate, video_file, output_file, None, 'en')
注意替换video_file和output_file为实际的视频文件路径和输出文件路径。如果有实际的音频开始时间,可以替换actual_start_time参数。
在上面的代码中,我们首先导入 whisper 库,然后定义一个名为 recognize_chinese_subtitle 的函数,该函数接受一个音频文件路径作为输入,并使用 whisper 客户端进行语音识别。识别结果保存在 result 字典中,其中 text 字段包含了识别出的字幕文本。
在 if __name__ == "__main__" 块中,我们调用 recognize_chinese_subtitle 函数,传入一个音频文件路径,然后打印识别出的字幕。文章来源:https://www.toymoban.com/news/detail-753988.html
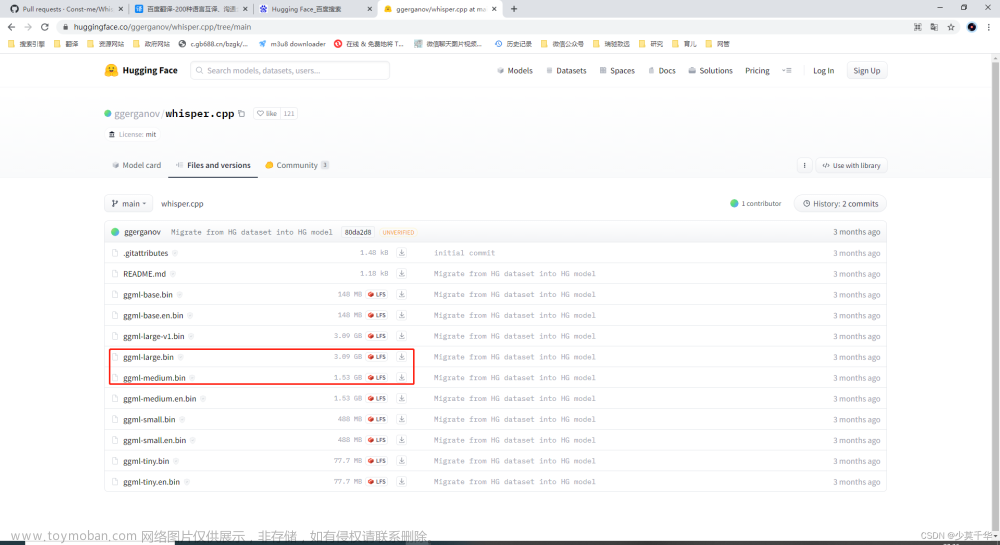
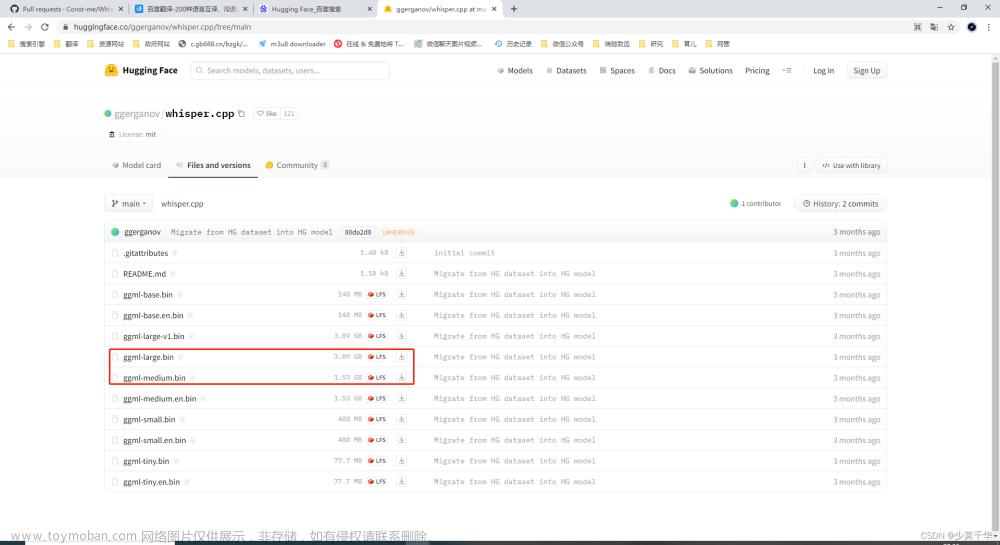
3.6 模型的选择,参考如下
_MODELS = {
"tiny.en": "https://openaipublic.azureedge.net/main/whisper/models/d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03/tiny.en.pt",
"tiny": "https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt",
"base.en": "https://openaipublic.azureedge.net/main/whisper/models/25a8566e1d0c1e2231d1c762132cd20e0f96a85d16145c3a00adf5d1ac670ead/base.en.pt",
"base": "https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt",
"small.en": "https://openaipublic.azureedge.net/main/whisper/models/f953ad0fd29cacd07d5a9eda5624af0f6bcf2258be67c92b79389873d91e0872/small.en.pt",
"small": "https://openaipublic.azureedge.net/main/whisper/models/9ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794/small.pt",
"medium.en": "https://openaipublic.azureedge.net/main/whisper/models/d7440d1dc186f76616474e0ff0b3b6b879abc9d1a4926b7adfa41db2d497ab4f/medium.en.pt",
"medium": "https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt",
"large-v1": "https://openaipublic.azureedge.net/main/whisper/models/e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a/large-v1.pt",
"large-v2": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",
"large": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",
}
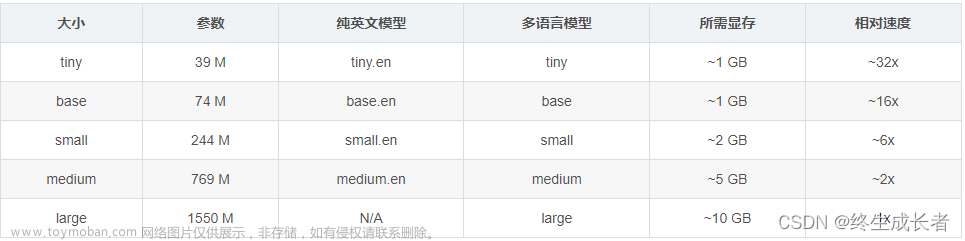
# 1.
# tiny.en / tiny:
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03 / tiny.en.pt
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / 65147644
# a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9 / tiny.pt
# - 优点:模型体积较小,适合在资源受限的环境中使用,推理速度较快。
# - 缺点:由于模型较小,可能在处理复杂或长文本时表现不如其他大型模型。 -------------错误较多
#
# 2.
# base.en / base:
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / 25
# a8566e1d0c1e2231d1c762132cd20e0f96a85d16145c3a00adf5d1ac670ead / base.en.pt
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e / base.pt
# - 优点:具有更大的模型容量,可以处理更复杂的对话和文本任务。
# - 缺点:相对于较小的模型,推理速度可能会稍慢。
#
# 3.
# small.en / small:
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / f953ad0fd29cacd07d5a9eda5624af0f6bcf2258be67c92b79389873d91e0872 / small.en.pt
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / 9
# ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794 / small.pt
# - 优点:模型规模适中,具有一定的表现能力和推理速度。
# - 缺点:在处理更复杂的对话和文本任务时,可能不如较大的模型表现出色。
#
# 4.
# medium.en / medium:
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / d7440d1dc186f76616474e0ff0b3b6b879abc9d1a4926b7adfa41db2d497ab4f / medium.en.pt
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / 345
# ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1 / medium.pt
# - 优点:更大的模型容量,可以处理更复杂的对话和文本任务。
# - 缺点:相对于较小的模型,推理速度可能会较慢。 ---断句很长 【00:00:52.000 -> 00:01:03.000】: 嗯,有一个那个小箱子,能看到吗?上面有那个白色的泡沫,那个白色塑料纸一样盖着,把那个白色那个塑料纸拿起来,下面就是。
#
# 5.
# large - v1 / large - v2 / large:
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a / large - v1.pt
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / 81
# f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524 / large - v2.pt
# - 链接:https: // openaipublic.azureedge.net / main / whisper / models / 81
# f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524 / large - v2.pt
# - 优点:最大的模型容量,具有最强大的表现能力,可以处理复杂的对话和文本任务。
# - 缺点:相对于其他较小的模型,推理速度较慢,占用更多的内存。
# whisper C:/Users/Lenovo/Desktop/whisper/luyin.aac --language Chinese --task translate
四、结论
通过以上步骤,已经成功安装了 whisper 并实现了识别中文字幕的功能。在实际应用中,可能需要根据实际情况对代码进行一些调整,例如处理音频文件路径、识别结果等。希望这篇文章对你有所帮助!文章来源地址https://www.toymoban.com/news/detail-753988.html
到了这里,关于【whisper】在python中调用whisper提取字幕或翻译字幕到文本的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!