衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
AI大神李沐大模型创业方向,终于“水落石出”:
利用大模型能力,做游戏引擎,且是面向4A游戏。

关于4A游戏这个概念,目前业内没有统一的“名词解释”,但通常理解为比3A游戏更强大一点的游戏(doge)。
被曝从亚马逊首席科学家的职务上离职后,李沐联手其导师、另一位亚马逊出身AI大牛Alex Smola的创业公司Boson.ai既没有高调露面,也没有什么隐秘爆料跟上。
外界只能从领英和公司极简风的官网上得知,公司方向是“scalable foundation models”(可扩展基础模型)。
而且是面向所有人(for everyone)那种。
现在,“大家的李沐老师”正在做的事情逐步清晰,AIGC for 游戏。
以及来自投资市场的消息,为了顺利推进这个目标,Boson.ai后来招贤纳士,吸纳了一位游戏方面的大牛坐镇公司联创。
——毕竟粗扫一遍发现,在过去,李沐和Smola没什么与游戏技术直接紧密关联的经历。

目前尚不清楚Boson.ai选择这条创业路线的准确原因,但大模型在游戏引擎上能够释放的能力,还是很明晰的。
比如最直给的创意生成和编辑能力,还有语音指令控制能力;
又或者是为游戏NPC赋予AI的灵魂,形成一个个独特的Agent,增强玩家的互动性和可玩空间等等。
……
总之,它能够让开发者对前端框架知识的门槛降低、效率提升。
而且要知道,上述例子仅仅是“大模型助力游戏引擎”已经露出水面的一角,还有很多水面下的故事值得挖掘。
话说回来,这家创业10个多月还神神秘秘的公司,为什么值得关注和期待?
为什么值得持续关注?
原因之一,就是李沐和Alex Smola都是AI领域里有技术、有名气的大牛。
AI 2.0时代,创业赛道上众星云集,李沐和Alex Smola弃亚马逊入大模型,属于是有名气、有技术的人投身最明星的赛道,当然格外耀眼。
李沐,二者之间大家比较熟悉的那一位。
自己有很厉害的经历,加上在小破站传道授业,打下了响当当的知名度。
而Alex Smola,更是一个AI届的神级大牛。
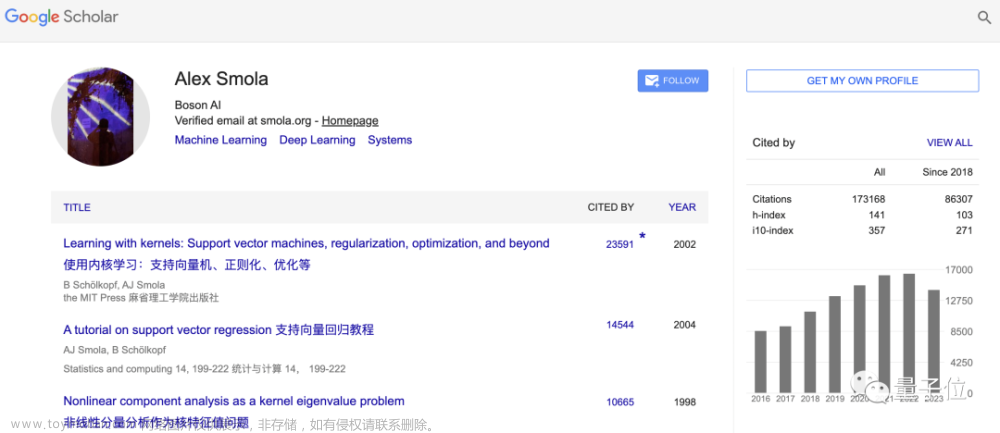
直接上数据:
Smola在Google Scholar上的被引用次数,超过17万次。
其中,被引次数前三的所著论文,被引数统统破万。
除了是ML著作《动手学深度学习》的主要作者外,Smola这些年的履历也很值得好好了解一番——
1996年,Smola在慕尼黑工业大学完成硕士学业,而后又在柏林工业大学拿下计算机科学博士学位。
博士毕业后,他先后去往柏林GMD软件工程和计算机体系结构研究所、NICTA(澳大利亚信息与通信技术研究中心)工作。
2004年起,Smola在NICTA的统计机器学习项目中,担任高级首席研究员和项目负责人;到了2008年,Smola选择入职雅虎研究院。
2012年春天到2014年年底,2年多的时间里,Smola的工作地点是谷歌研究院。
期间,他开始担任CMU的教授。也是这个时候,他成为了李沐的博士导师,二人结缘。

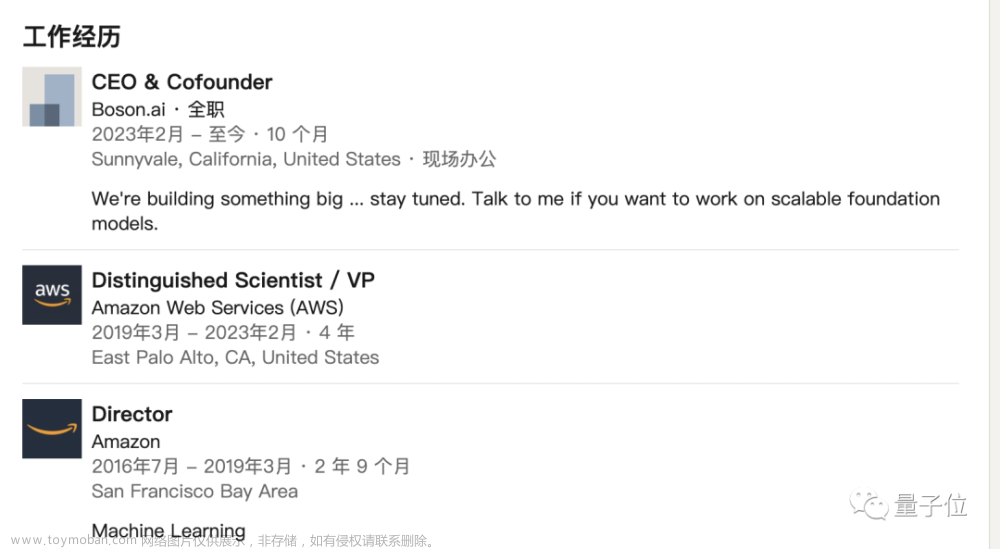
2016年7月,Smola成为了亚马逊的一员,致力于构建AI和机器学习工具。
他的首要任务之一,是让AWS和开发者社区建立和保持联系。
具体来说,他的工作是让更多的开发者共同建设亚马逊深度学习库MXNet。
离职创业前,Smola在亚马逊担任的职位是杰出科学家和副总裁。
值得一提的是,由于Smola在分布式深度学习框架领域曾提出并行LDA(Latent Dirichlet Allocation)的框架——这是参数服务器概念的最早来源,因此,Smola也被业界称为参数服务器之父。
参数服务器,以共享的形式实现不同节点之间数据交互的通信模式。
其采用了一种将模型参数中心化管理的方式,来实现模型参数的分布式存储和更新。
它的作用在于存储一些多节点共享的数据,常适用于存在数据共享的应用场景。
在大模型当道的现在,我们也可以说参数服务器的提出对大模型训练的性能和效果发挥着重要作用。

另一个值得期待的原因,就是李沐和Smola师徒二人,此前有过一次还算成功的创业经历。
Smola是李沐在CMU读博期间的导师,那时候两人曾一同创办数据分析算法公司Marianas Labs,Smola任CEO,李沐任CTO。
李沐在《博士这五年》一文中提到,那次创业,他们拿了几十万投资,风风火火干了好一阵,最后把公司卖给了一家小上市公司。
结束这段创业经历后,两人才先后踏入亚马逊公司的大门。
直到今年2月,Smola在领英宣布离职,成立新公司并担任CEO。
他在领英资料里提到:
我们正在建造一个大项目……请继续关注。如果你想在可扩展基础模型上工作,请告诉我。
随后传出消息,这个“大项目”就是Smola和李沐的二次联手创业。
不过直到现在,除了悄悄招人扩大团队以外,Boson.ai没有再多的公开大动作。
包括李沐的领英,最新动态仍然停留在他的亚马逊经历。
One More Thing
因此,在得知李沐老师要用大模型能力做游戏引擎后,我们第一时间兴奋地冲向了Boson.ai的GitHub主页。
有点遗憾,GitHub仓库和几个月前官宣时一样,没有什么新变化,也没有任何与游戏相关的蛛丝马迹。
但是就这么一个什么也没有的主页,已经有近500颗星了……
— 联系作者 —文章来源:https://www.toymoban.com/news/detail-753997.html
 文章来源地址https://www.toymoban.com/news/detail-753997.html
文章来源地址https://www.toymoban.com/news/detail-753997.html
到了这里,关于李沐大模型公司细节曝光,项目GitHub空仓标星超500的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!